
MySQL多表查询与7种JOINS的实现举例

前言
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。
前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,这个关联字段可能建立了外键,也可能没有建立外键。比如:员工表和部门表,这两个表依靠“部门编号”进行关联。
1.案例多表连接
案例说明
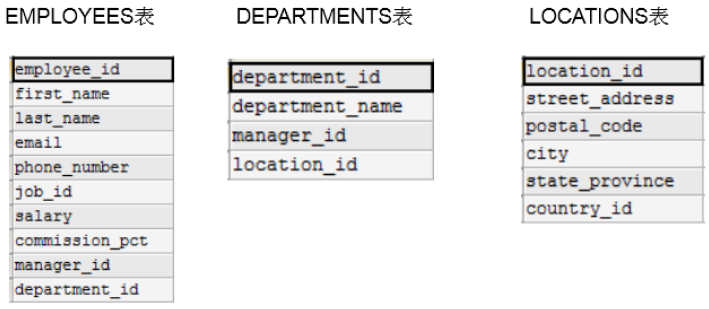
从多个表中获取数据:
# 错误的实现方式:每个员工都与每个部门匹配了一遍。 SELECT employee_id,department_name FROM employees,departments; # 查询出2889条记录
分析错误情况:
SELECT COUNT(employee_id) FROM employees; #输出107行 SELECT COUNT(department_id)FROM departments; # 输出27行 SELECT 107*27 FROM dual;
因此把多表查询中出现的问题称为:笛卡尔积的错误。
笛卡尔积(或交叉连接)
笛卡尔乘积是一个数学运算。假设我有两个集合 X 和 Y,那么 X 和 Y 的笛卡尔积就是 X 和 Y 的所有可能组合,也就是第一个对象来自于 X,第二个对象来自于 Y 的所有可能。组合的个数即为两个集合中元素个数的乘积数。
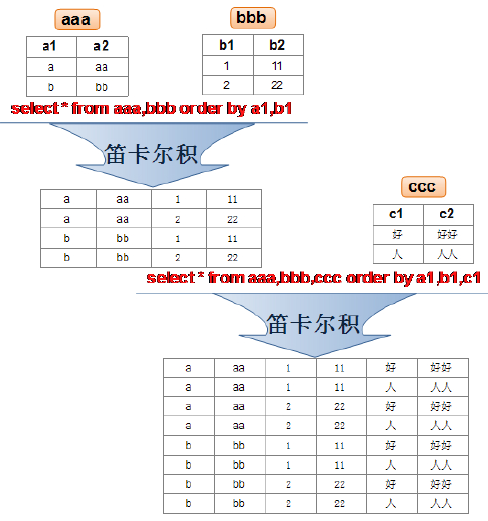
SQL92中,笛卡尔积也称为交叉连接,英文是 CROSS JOIN 。在 SQL99 中也是使用 CROSS JOIN表示交叉连接。它的作用就是可以把任意表进行连接,即使这两张表不相关。
因此上面的代码可以等价于:
# 错误的方式 SELECT employee_id,department_name FROM employees CROSS JOIN departments; # 查询出2889条记录
笛卡尔积的错误会在下面条件下产生:
- 省略多个表的连接条件(或关联条件)
- 连接条件(或关联条件)无效
- 所有表中的所有行互相连接
为了避免笛卡尔积, 可以在 WHERE 加入有效的连接条件。加入连接条件后,查询语法:
# 在表中有相同列时,在列名之前加上表名前缀。 SELECT last_name, department_name, departments.department_id; FROM employees, departments # 连接条件 WHERE employees.department_id = departments.department_id;
注意:在表中有相同列时,在列名之前加上表名前缀。
建议:从sql优化的角度,建议多表查询时,每个字段前都指明其所在的表。
此外,方便起见,表名也可以用别名代替。但是如果给表起了别名,一旦在SELECT或WHERE中使用表名的话,则必须使用表的别名,而不能再使用表的原名。
多个连接条件的拼接需要使用 AND 关键字。例如:
SELECT e.employee_id,e.last_name,d.department_name,l.city,e.department_id,l.location_id FROM employees e, departments d, locations l WHERE e.`department_id` = d.`department_id` AND d.`location_id` = l.`location_id`;
如果有 n 个表实现多表的查询,则需要至少 n-1 个连接条件。
2. 多表查询分类讲解
角度1:等值连接与非等值连接
这里涉及 job_grades 表,通过查询可知,每个薪水都有其相应的等级区间。
SELECT * FROM job_grades;
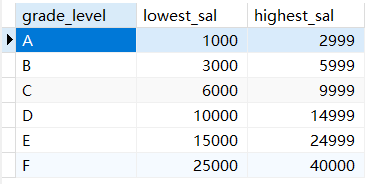
这里通过员工表与其相应的区间等级做一个匹配:
SELECT e.last_name,e.salary,j.grade_level FROM employees e,job_grades j WHERE e.`salary` between j.`lowest_sal` and j.`highest_sal`; # WHERE e.`salary` >= j.`lowest_sal` AND e.`salary` <= j.`highest_sal`;
角度2:自连接与非自连接
当table1和table2本质上是同一张表,只是用取别名的方式虚拟成两张表以代表不同的意义。然后两个表再进行内连接,外连接等查询。

连接的条件是WORKER表中的MANAGER_ID和MANAGER表中的EMPLOYEE_ID相等。
题目:查询employees表,返回“Xxx works for Xxx”
SELECT CONCAT(worker.last_name ," works for ", manager.last_name) FROM employees worker, employees manager WHERE worker.manager_id = manager.employee_id ;
-
CONCAT的作用是连接字符串。
角度3:内连接与外连接
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
如果是左外连接,则连接条件中左边的表也称为主表,右边的表称为从表。
如果是右外连接,则连接条件中右边的表也称为主表,左边的表称为从表。
SQL92:使用(+)创建连接
在 SQL92 中采用(+)代表从表所在的位置。即左或右外连接中,(+) 表示哪个是从表。
但是Oracle 对 SQL92 支持,而 MySQL 则不支持 SQL92 的外连接。
# 左外连接 SELECT last_name,department_name FROM employees ,departments WHERE employees.department_id = departments.department_id(+); # 右外连接 SELECT last_name,department_name FROM employees ,departments WHERE employees.department_id(+) = departments.department_id;
- 在 SQL92 中,只有左外连接和右外连接,没有满(或全)外连接。
3. SQL99语法实现多表查询
SQL99语法中使用 JOIN …ON 的方式实现多表的查询。这种方式也能解决外连接的问题。
MySQL是支持此种方式的。
- 可以使用 ON 子句指定额外的连接条件。
- 这个连接条件是与其它条件分开的。
- 关键字 JOIN、INNER JOIN、CROSS JOIN 的含义是一样的,都表示内连接
内连接(INNER JOIN)的实现
SELECT 字段列表
FROM A表 INNER JOIN B表
ON 关联条件
WHERE 等其他子句;
外连接(OUTER JOIN)的实现
左外连接(LEFT OUTER JOIN)
语法:
SELECT e.last_name, e.department_id, d.department_name FROM employees e LEFT OUTER JOIN departments d ON (e.department_id = d.department_id) ;
右外连接(RIGHT OUTER JOIN)
语法:
SELECT e.last_name, e.department_id, d.department_name FROM employees e RIGHT OUTER JOIN departments d ON (e.department_id = d.department_id) ;
满外连接(FULL OUTER JOIN)
满外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
- SQL99是支持满外连接的。使用FULL JOIN 或 FULL OUTER JOIN来实现。
- 但是MySQL不支持FULL JOIN,但是可以用
LEFT JOINUNIONRIGHT JOIN代替。
4. UNION的使用
合并查询结果
利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。
- 合并时,两个表对应的列数和数据类型必须相同,并且相互对应。
- 各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
语法格式:
SELECT column,... FROM table1 UNION [ALL] SELECT column,... FROM table2
UNION操作符
UNION 操作符返回两个查询的结果集的并集,去除重复记录。由于需要去除重复,因此它的性能相对低一点。
UNION ALL操作符
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
如果明确知道合并数据后的结果数据无重复数据,尽量使用UNION ALL语句,以提高数据查询的效率。
5. 7种SQL JOINS的实现
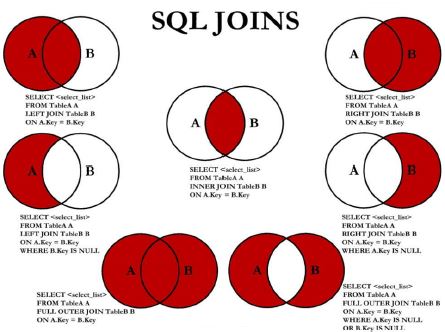
代码实现
中图:内连接 A ∩ B
SELECT employee_id,last_name,department_name FROM employees e JOIN departments d ON e.`department_id` = d.`department_id`;
左上图:左外连接
SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id`;
右上图:右外连接
SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id`;
左中图:A - A ∩ B
SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` IS NULL
右中图:B - A ∩ B
这里解释一下WHERE e.department_id IS NULL,首先是由右外连接衍生出来的,减去中间交集的部分,然后交际的部分是包含A和B的,只需要用条件从表A为NULL,即可将在B中有A的部分筛掉。
SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` IS NULL
左下图:满外连接,左中图 + 右上图 A∪B
SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` IS NULL UNION ALL #没有去重操作,效率高 SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id`;
右下图:左中图 + 右中图 A ∪ B - A ∩ B 或者 ( A - A ∩ B) ∪ ( B - A ∩ B)
SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` IS NULL UNION ALL SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` IS NULL
6.SQL99语法新特性
自然连接
可以把自然连接理解为 SQL92 中的等值连接。它会帮你自动查询两张连接表中所有相同的字段,然后进行等值连接。
在 SQL92 标准中:
SELECT employee_id,last_name,department_name FROM employees e JOIN departments d ON e.department_id = d.department_id AND e.manager_id = d.manager_id;
在 SQL99 中你可以写成:
SELECT employee_id,last_name,department_name FROM employees e NATURAL JOIN departments d;
USING连接
当我们进行连接的时候,SQL99 还支持使用 USING 指定数据表里的同名字段进行等值连接。但是只能配合JOIN一起使用。比如:
SELECT employee_id,last_name,department_name FROM employees e JOIN departments d USING (department_id);
你能看出与自然连接 NATURAL JOIN 不同的是,USING 指定了具体的相同的字段名称,你需要在 USING的括号 () 中填入要指定的同名字段。同时使用 JOIN…USING 可以简化 JOIN ON 的等值连接。它与下面的 SQL 查询结果是相同的:
SELECT employee_id,last_name,department_name FROM employees e ,departments d WHERE e.department_id = d.department_id;
总结:表连接的约束条件可以有三种方式:WHERE, ON, USING
- WHERE:适用于所有关联查询
- ON :只能和JOIN一起使用,只能写关联条件。虽然关联条件可以并到WHERE中和其他条件一起写,但分开写可读性更好。建议一个JOIN一个ON的写法。
- USING:只能和JOIN一起使用,而且要求两个关联字段在关联表中名称一致,而且只能表示关联字段值相等。
注意:
要控制连接表的数量。多表连接就相当于嵌套 for 循环一样,非常消耗资源,会让 SQL 查询性能下降得很严重,因此不要连接不必要的表。在许多 DBMS 中,也都会有最大连接表的限制。
附录:常用的 SQL 标准有哪些
SQL 存在不同版本的标准规范,因为不同规范下的表连接操作是有区别的。
SQL 有两个主要的标准,分别是 SQL92 和 SQL99 。92 和 99 代表了标准提出的时间,SQL92 就是 92 年
提出的标准规范。当然除了 SQL92 和 SQL99 以外,还存在 SQL-86、SQL-89、SQL:2003、SQL:2008、
SQL:2011 和 SQL:2016 等其他的标准。
最重要的 SQL 标准就是 SQL92 和 SQL99。一般来说 SQL92 的形式更简单,但是写的 SQL 语句会比较长,可读性较差。而 SQL99 相比于 SQL92 来说,语法更加复杂,但可读性更强。
SQL92 和 SQL99 是经典的 SQL 标准,也分别叫做 SQL-2 和 SQL-3 标准。也正是在这两个标准发布之后,SQL 影响力越来越大,甚至超越了数据库领域。现如今 SQL 已经不仅仅是数据库领域的主流语言,还是信息领域中信息处理的主流语言,在图形检索、图像检索以及语音检索中都能看到 SQL 语言的使用。
练习题
1.显示所有员工的姓名,部门号和部门名称
SELECT last_name, e.department_id, department_name FROM employees e LEFT OUTER JOIN departments d ON e.department_id = d.department_id;
2.查询90号部门员工的job_id和90号部门的location_id
SELECT job_id, location_id FROM employees e JOIN departments d ON e.department_id = d.department_id WHERE e.department_id = 90;
顺便提一句,写这道题时ON语句后加了个; 导致查询总是不对,分析了好久才发现。不得不感叹,SQL中分号真的不要乱加。
3.选择所有有奖金的员工的 last_name , department_name , location_id , city
SELECT last_name , department_name , d.location_id , city FROM employees e LEFT OUTER JOIN departments d ON e.`department_id` = d.`department_id` LEFT OUTER JOIN locations l ON d.`location_id` = l.`location_id` WHERE commission_pct IS NOT NULL;
4.选择city在Toronto工作的员工的 last_name , job_id , department_id , department_name
SELECT e.last_name , e.job_id , d.department_id , d.department_name FROM locations l JOIN departments d ON l.location_id = d.location_id JOIN employees e ON d.department_id = e.department_id WHERE l.city = "Toronto";
5.查询员工所在的部门名称、部门地址、姓名、工作、工资,其中员工所在部门的部门名称为’Executive’
SELECT department_name, street_address, last_name, job_id, salary FROM employees e JOIN departments d ON e.department_id = d.department_id JOIN locations l ON d.`location_id` = l.`location_id` WHERE department_name = "Executive"
6.选择指定员工的姓名,员工号,以及他的管理者的姓名和员工号,结果类似于下面的格式
employees Emp# manager Mgr# kochhar 101 king 100
SELECT emp.last_name employees, emp.employee_id "Emp#", mgr.last_name manager,mgr.employee_id "Mgr#" FROM employees emp LEFT OUTER JOIN employees mgr ON emp.manager_id = mgr.employee_id;
7.查询哪些部门没有员工
SELECT d.department_name FROM departments d LEFT OUTER JOIN employees e ON d.department_id = e.department_id WHERE e.department_id IS NULL;
这里简单地描述一下解题的思路:首先涉及两张表,员工表和部门表,然后通过department_id建立联系。接下来就要考虑如上图的两个部分,交集是有部门且有员工的部分,然后左外连接是各个部门号,去除中间的交集就是部门号但是没员工的部分。因此类似于左中图。只需要让从表的该条件为NULL即可。
此外还有第二种办法,子查询:
SELECT department_id FROM departments d WHERE NOT EXISTS ( SELECT * FROM employees e WHERE e.`department_id` = d.`department_id` )
8.查询哪个城市没有部门
SELECT l.location_id,l.city FROM locations l LEFT JOIN departments d ON l.`location_id` = d.`location_id` WHERE d.`location_id` IS NULL
9.查询部门名为 Sales 或 IT 的员工信息
SELECT employee_id,last_name,department_name
FROM employees e,departments d
WHERE e.department_id = d.`department_id`
AND d.`department_name` IN ("Sales","IT");
练习题Part2
储备:建表操作:
CREATE TABLE `t_dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `t_emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`deptId` INT(11) DEFAULT NULL,
empno int not null,
PRIMARY KEY (`id`),
KEY `idx_dept_id` (`deptId`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO t_dept(deptName,address) VALUES("华山","华山");
INSERT INTO t_dept(deptName,address) VALUES("丐帮","洛阳");
INSERT INTO t_dept(deptName,address) VALUES("峨眉","峨眉山");
INSERT INTO t_dept(deptName,address) VALUES("武当","武当山");
INSERT INTO t_dept(deptName,address) VALUES("明教","光明顶");
INSERT INTO t_dept(deptName,address) VALUES("少林","少林寺");
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES("风清扬",90,1,100001);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES("岳不群",50,1,100002);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES("令狐冲",24,1,100003);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES("洪七公",70,2,100004);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES("乔峰",35,2,100005);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES("灭绝师太",70,3,100006);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES("周芷若",20,3,100007);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES("张三丰",100,4,100008);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES("张无忌",25,5,100009);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES("韦小宝",18,null,100010);
【题目】
#1.所有有门派的人员信息
( A、B两表共有)
#2.列出所有用户,并显示其机构信息
(A的全集)
#3.列出所有门派
(B的全集)
#4.所有不入门派的人员
(A的独有)
#5.所有没人入的门派
(B的独有)
#6.列出所有人员和机构的对照关系
(AB全有)
#MySQL Full Join的实现 因为MySQL不支持FULL JOIN,下面是替代方法
#left join + union(可去除重复数据)+ right join
#7.列出所有没入派的人员和没人入的门派
(A的独有+B的独有)
1.所有有门派的人员信息( A、B两表共有)
select * from t_emp a inner join t_dept b on a.deptId = b.id;
2.列出所有用户,并显示其机构信息(A的全集)
select * from t_emp a left join t_dept b on a.deptId = b.id;
3.列出所有门派(B的全集)
select * from t_dept b;
4.所有不入门派的人员(A的独有)
select * from t_emp a left join t_dept b on a.deptId = b.id where b.id is null;
5.所有没人入的门派(B的独有)
select * from t_dept b left join t_emp a on a.deptId = b.id where a.deptId is null;
6.列出所有人员和机构的对照关系 (AB全有)
#MySQL Full Join的实现 因为MySQL不支持FULL JOIN,下面是替代方法 #left join + union(可去除重复数据)+ right join SELECT * FROM t_emp A LEFT JOIN t_dept B ON A.deptId = B.id UNION SELECT * FROM t_emp A RIGHT JOIN t_dept B ON A.deptId = B.id
7.列出所有没入派的人员和没人入的门派(A的独有+B的独有)
SELECT * FROM t_emp A LEFT JOIN t_dept B ON A.deptId = B.id WHERE B.`id` IS NULL UNION SELECT * FROM t_emp A RIGHT JOIN t_dept B ON A.deptId = B.id WHERE A.`deptId` IS NULL;
总结
到此这篇关于MySQL多表查询与7种JOINS实现的文章就介绍到这了,更多相关MySQL多表查询与JOINS实现内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文地址:https://blog.csdn.net/m0_52316372/article/details/128745622
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








