
如何解决mysql深度分页问题
吾爱主题
阅读:282
2023-05-23 13:53:00
评论:0

mysql深度分页问题
数据:单表数据25万条。
1.基本分页:耗时0.019秒
?| 1 | select * from cf_qb_info limit 0,20 |
2.深度分页:耗时10.236秒
?| 1 | select * from cf_qb_info limit 200000,20 |
3.深度ID分页:耗时0.052秒
提示:如果这一步很慢,count(1) 查询总数应该也会很慢-解决方式:请为主键加上unique索引。
?| 1 2 | -- 主键ID字段:NUMID select NUMID from cf_qb_info limit 200000,20 |
4.两步走深度分页:耗时0.049秒+0.017秒
基于第三步的缺陷(只能查出ID信息),我们可以先查出分页数据的ID,在根据ID查询数据。
?| 1 | select NUMID from cf_qb_info LIMIT 200000,20 |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | select * from cf_qb_info where NUMID in ( '330681650000202108180227345510' , '330681650000202108171031534500' , '330681650000202108190251532141' , '330681650000202108200246376830' , '330681650000202108210229398665' , '330681650000202108220236113895' , '330681650000202108230230034133' , '330681650000202108231017279739' , '330681650000202108231043456276' , '330681650000202108231051404340' , '330681650000202108240237397251' , '330681650000202108250221489228' , '330681650000202108250241536726' , '330681650000202108260253039326' , '330681650000202108270216016138' , '330681650000202108280234013754' , '330681650000202108290230029720' , '330681650000202108300255579204' , '330681650000202108310234184991' , '330681650000202109010237315937' ); |
两步合成一步SQL耗时:11.9秒;这一步着实出乎了我的意料。
?| 1 2 3 4 5 | select * from cf_qb_info where NUMID in ( select NUMID from ( select NUMID from cf_qb_info LIMIT 200000,20) as t ); |
鉴于这个结果:我们可以在程序里分成两步进行分页查询。
5.一步走深度分页:耗时0.05秒
这一步是对第四步的优化,毕竟两条SQL还需要码代码。利用join 两条SQL合成一条。
?| 1 2 3 4 5 | SELECT * FROM cf_qb_info a JOIN ( SELECT NUMID FROM cf_qb_info LIMIT 200000, 20 ) b ON a.NUMID = b.NUMID |
6.集成BeanSearcher框架
原理是使用了BeanSearcher的sql拦截器对SQL进行拦截改造。
①改造Bean
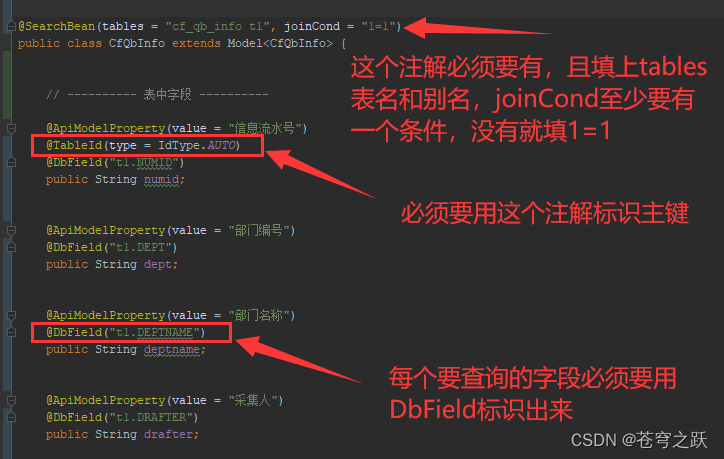
②注入Sql拦截器
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | package com.ciih.qbbs.config; import cn.hutool.core.util.ReUtil; import cn.hutool.core.util.StrUtil; import com.baomidou.mybatisplus.annotation.TableId; import com.ejlchina.searcher.SearchSql; import com.ejlchina.searcher.SqlInterceptor; import com.ejlchina.searcher.SqlSnippet; import com.ejlchina.searcher.param.FetchType; import org.springframework.stereotype.Component; import java.lang.reflect.Field; import java.util.List; import java.util.Map; /** * BeanSearcher的Sql拦截器:优化深度分页 * * @author sunziwen */ @Component public class SqlInterceptorImpl implements SqlInterceptor { @Override public <T> SearchSql<T> intercept(SearchSql<T> searchSql, Map<String, Object> paraMap, FetchType fetchType) { /** * 改造思路 * * <> * 前:SELECT * FROM table1 t1 LIMIT 200000,20; * 后:SELECT * FROM table1 t1 JOIN ( SELECT id FROM table1 LIMIT 200000, 20 ) t99 ON t1.id = t99.id; * </> */ Field[] fields = searchSql.getBeanMeta().getBeanClass().getDeclaredFields(); String primaryColumnName = null ; for (Field field : fields) { //这里使用了mybatis_plus的注解作为主键标识 TableId tableId = field.getAnnotation(TableId. class ); if (tableId != null ) { if (! "" .equals(tableId.value())) { primaryColumnName = tableId.value(); } else { //驼峰转下划线 primaryColumnName = StrUtil.toUnderlineCase(field.getName()); } } } //如果没有主键标识,则不能进行SQL优化。 if (primaryColumnName == null ) { return searchSql; } //正则表达式获取where之后语句 List<String> limits = ReUtil.findAll( "where[\s\S]*limit[ ]+[?]{1}[ ]*,[ ]+[?]{1}" , searchSql.getListSqlString(), 0 ); //如果不分页,则不进行SQL优化,即语句中没有limit关键字不优化。 if (limits.size() == 0 ) { return searchSql; } //表名小片段 SqlSnippet tableSnippet = searchSql.getBeanMeta().getTableSnippet(); //合成子查询SQL String inSql = "JOIN ( SELECT " + primaryColumnName + " FROM " + tableSnippet.getSql() + " " + limits.get( 0 ) + " ) t99 ON t1." + primaryColumnName + " = t99." + primaryColumnName + ";" ; //合成整条SQL String replace = searchSql.getListSqlString().replace(limits.get( 0 ), inSql); //替换 searchSql.setListSqlString(replace); return searchSql; } } |
7.万能优化技巧:索引
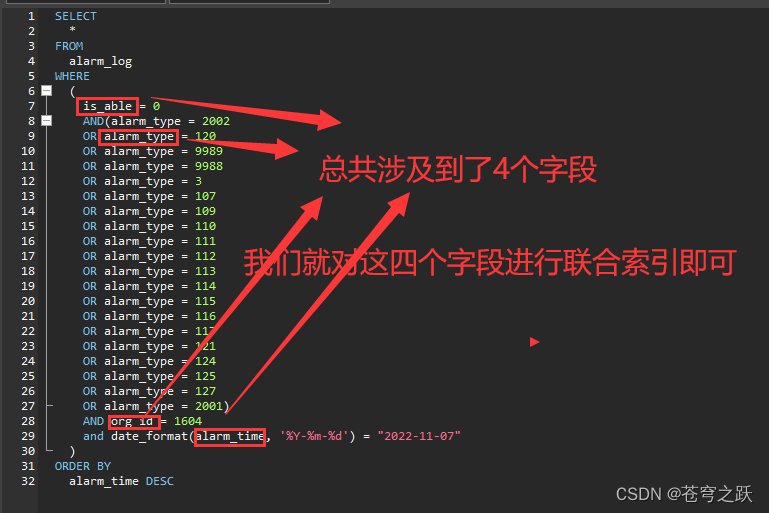
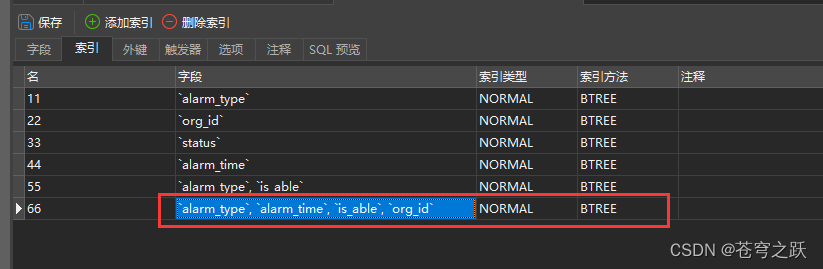
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持服务器之家。
原文链接:https://blog.csdn.net/wenxingchen/article/details/126540876
声明
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








