
MySQL --- 多表查询 & 驱动表

多表查询、事务、以及提升查询效率最有手段的索引
一. 多表查询
1.1 多表查询 --- 概述
1.1.1 数据准备
- 将资料中准备好的多表查询数据准备的SQL脚本导入数据库中。
部门表:
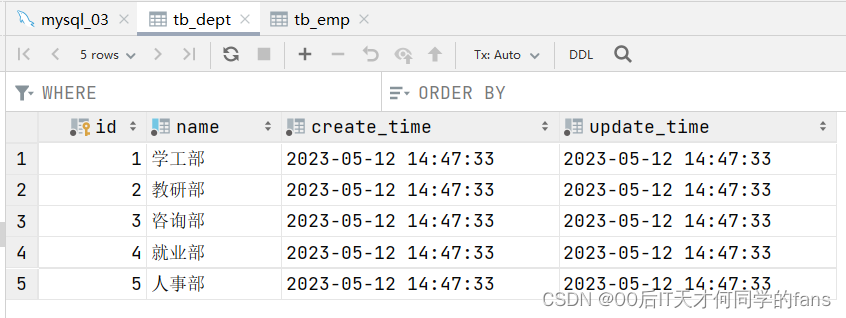 员工表:
员工表:
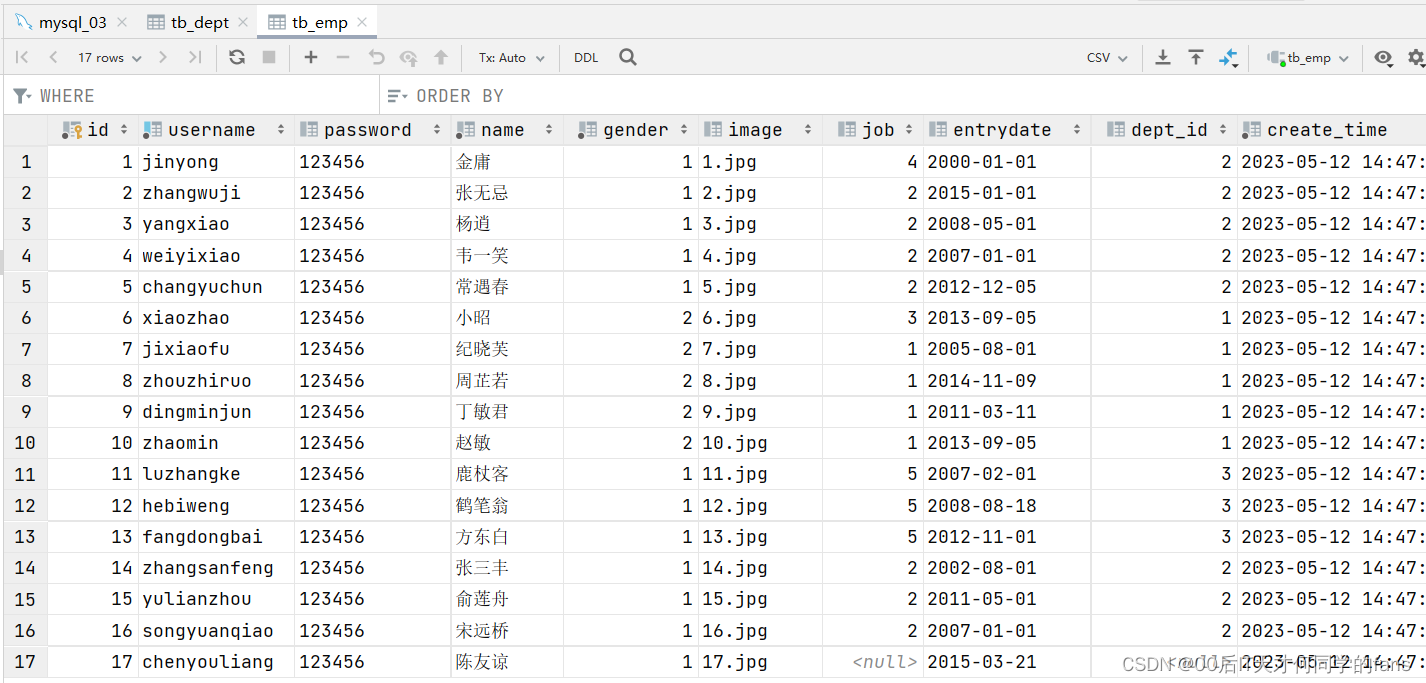
1.1.2 介绍
多表查询:指从多张表中查询数据,就是从多张表当中进行查询
单表查询的SQL语句:select 字段列表 from 表名;
那么要执行多表查询,只需要使用逗号分隔多张表即可,如: select 字段列表 from 表1, 表2;
查询用户表和部门表中的数据:
-- 多表查询:直接在from之后跟上多张表就可以了,多张表之间使用逗号分隔 select * from tb_dept,tb_emp,;
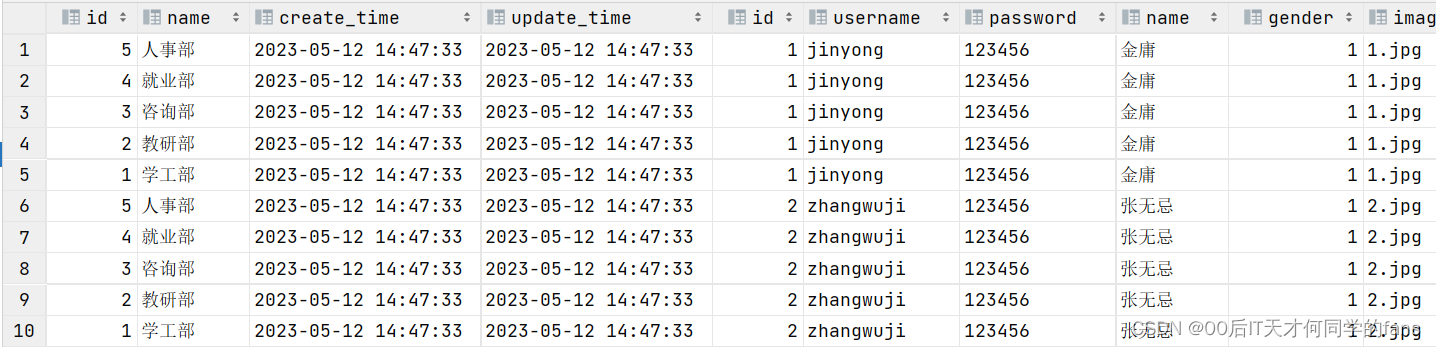

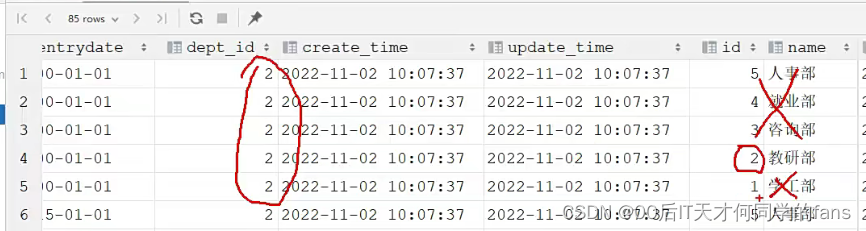
可以看到,在多表查询的结果当中,每个员工都展示了5次,将每个员工分别和五个部门进行了一次匹配, 也就是将17个员工和5个部门挨个组合了一次,就是17 * 5 = 85。
此时,我们看到查询结果中包含了大量的结果集{包含了大量的无效数据},总共85条记录,而这其实就是员工表所有的记录(17行)与部门表所有记录(5行)的所有组合情况,这种现象称之为笛卡尔积。
之所以出现笛卡尔积这种现象是因为我们没有对两张表使用条件约束进行和关联查询!
笛卡尔积:笛卡尔乘积是指在数学中,两个集合(A集合和B集合它们)的所有组合情况。就相当于 是把A集合当中的每一条记录都拿出来和B集合进行一个匹配。
总数据量 = A集合的数据量 * B集合的数据量
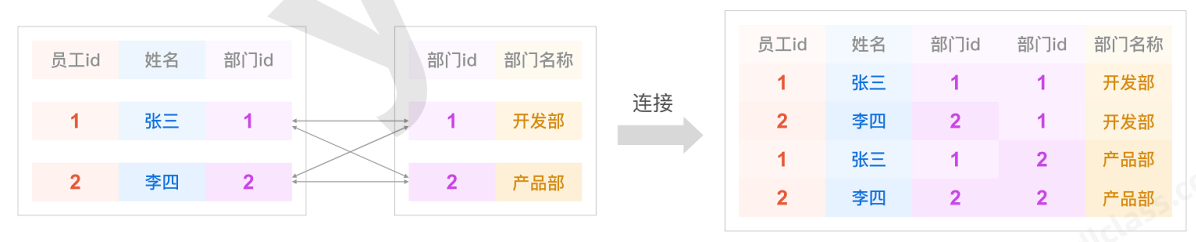
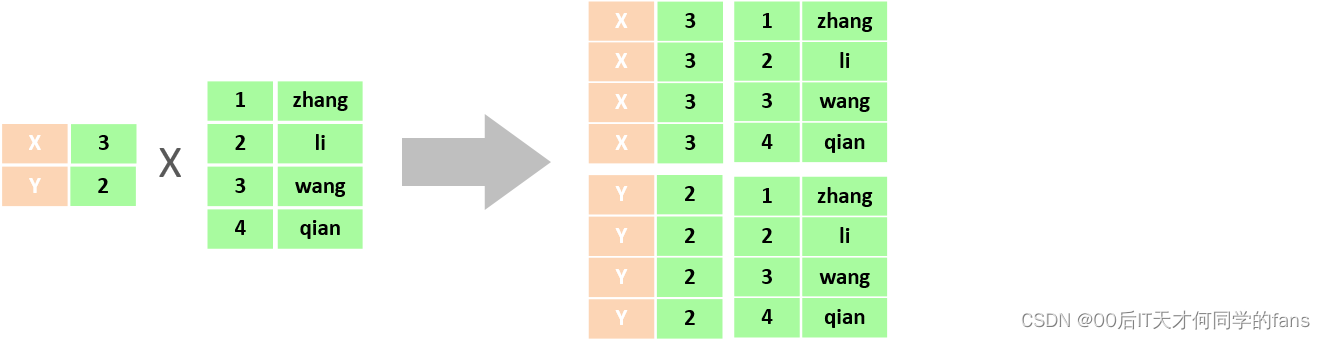 2 * 4 = 8条记录, 产生的这个结果被一个法国的数据加笛卡尔发现了,所以叫笛卡尔积。这个笛卡尔积是数学当中的一个概念,指的就是两个集合,A集合与B集合所有的组合情况。
2 * 4 = 8条记录, 产生的这个结果被一个法国的数据加笛卡尔发现了,所以叫笛卡尔积。这个笛卡尔积是数学当中的一个概念,指的就是两个集合,A集合与B集合所有的组合情况。
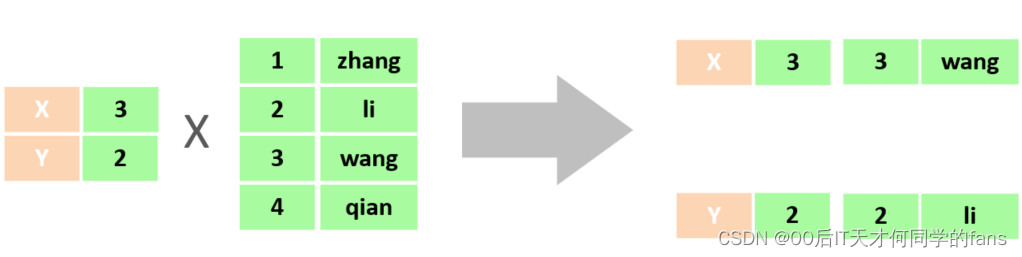
- 我们知道一个员工只能归属于一个部门, 而其它无效数据我们是不需要的,所以多表查询的目的就是根据业务需求从多张表当中来查询数据,并且根据业务需要,要消除掉这些无效的笛卡尔积。
- 就拿当前这个例子来说,假如我们要查询的是每一个员工的信息以及员工对应的部门信息,那我们就可以将员工表当中部门ID这个字段与部门表的主键ID对应起来即可。
- 而其它的这些数据,对于我们当前需求来说都是无效的笛卡尔积。
注意:在多表查询时,需要消除无效的笛卡尔积,只保留表关联部分的数据
在SQL语句中,如何去除无效的笛卡尔积呢?
- 只需要给多表查询加上连接查询的条件即可,通过连接查询的条件来消除无效的笛卡尔积。
-- 多表查询:直接在from之后跟上多张表就可以了,多张表之间使用逗号分隔 -- 在多表查询时,需要消除无效的笛卡尔积,只保留表关联部分的数据 -- 在SQL语句中,只需要给多表查询加上连接查询的条件即可去除无效的笛卡尔积 select * from tb_emp,tb_dept where tb_emp.dept_id = tb_dept.id;
在多表查询当中,消除无效的笛卡尔积之后,剩下的这一部分数据就是我们想要的正确的数据:
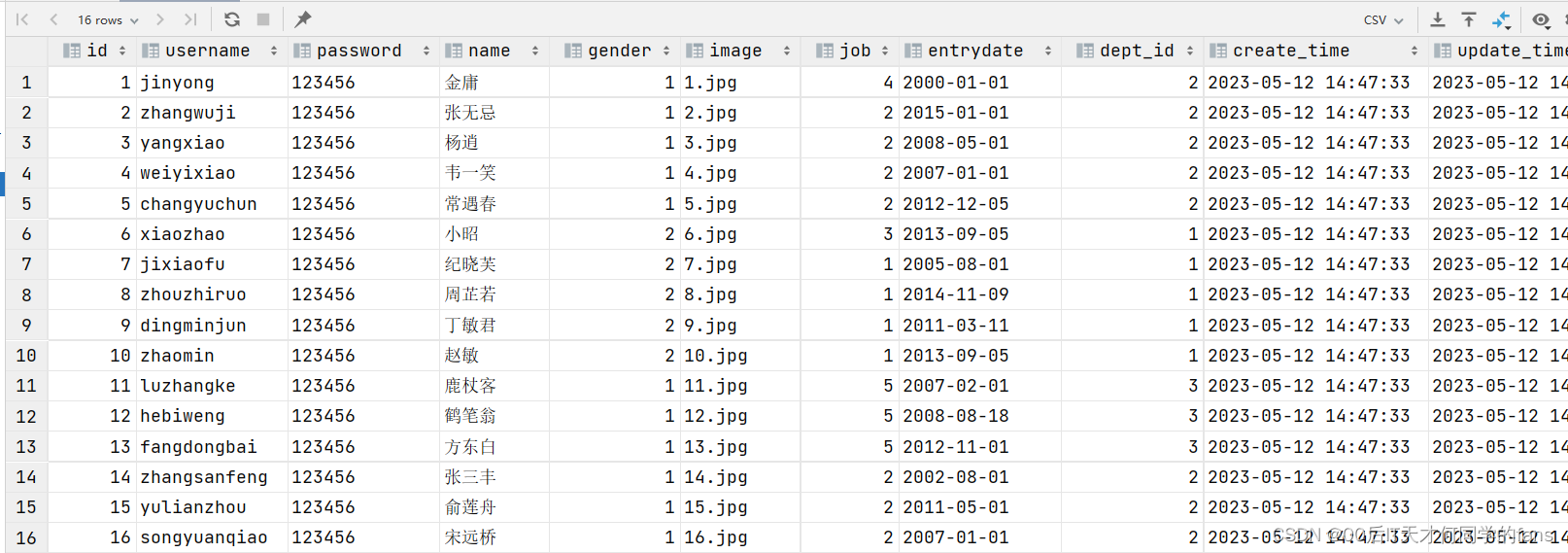
由于id为17的员工,没有dept_id字段值,所以在多表查询时,根据连接查询的条件并没有查询到。
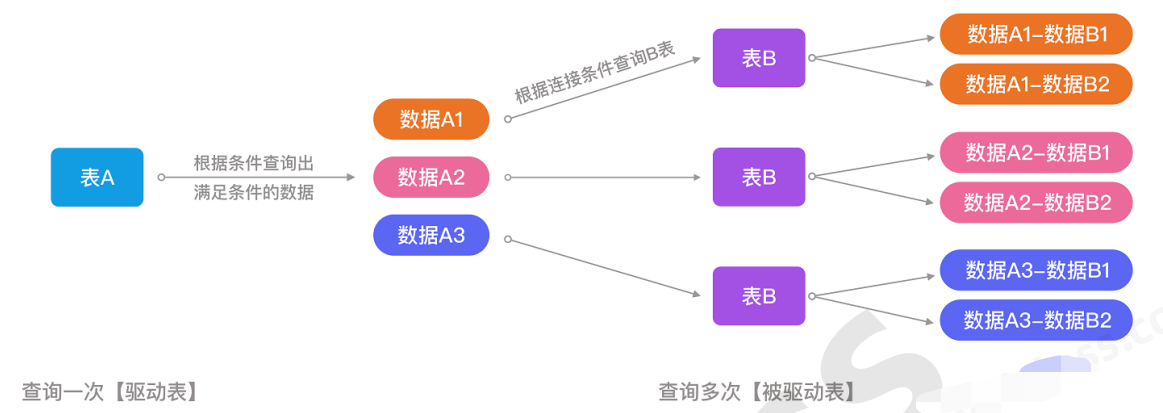
驱动表和被驱动表:
我们在进行多表联查的时候,查询的过程大致如下:
- 首先选取一张表,我们称之为驱动表,从驱动表中开始查询,找到满足条件的所有数据,如果没有条件就全部取出。
- 然后根据从驱动表查询的这条数据,以及联查条件,去第二张被驱动表中查询,并将查询结果进行拼接,以此类推,从驱动表获取的第二条数据,使用该数据和联查条件,再次去被驱动表进行查询,并将查询结果进行拼接。
- 整个过程,会查询驱动表一次,查询被驱动表多次。
- 驱动表在SQL语句执行的过程中先读取,而被驱动表在SQL语句执行的过程中后读取!
- 驱动表的选择会决定着一条SQL的执行效率!所以,一条SQL中,该使用哪张表作为驱动表,其实是由优化器决定的!
- MySQL的优化器选择驱动表的原则是:具有更好的访问性能~!
因此,通常情况下,驱动表的选择可以从以下几个方面考量:
- 表的大小:小表驱动大表,小表作为驱动表可以更快的被扫描和匹配,所以优化器倾向于选择较小的表作为驱动表!
- 利用索引进行加速访问的表可以作为驱动表:我们知道在MySQL中,索引能大大的提高查询效率,因此我们可以选择利用索引进行加速访问的表作为驱动表,以提升效率!
- where条件:如果查询中包含过滤条件,优化器会选择能够使用过滤条件进行筛选的表作为驱动表,以减少后续的匹配操作!
- 连接类型:根据连接类型,比如:inner join、left outer join、right outer join。
- left outer join:会选择左表作为驱动表,右表是被驱动表,主要是因为left join要返回左表中的所有记录,而右表的匹配记录是可选的。通过左表为驱动表,可以确保返回左表中的所有记录!
- right join:右表是驱动表,左表是被驱动表
- inner join:内连接中,驱动表是系统优化后自动选取的,会将执行计划中扫描次数少的表作为驱动表!
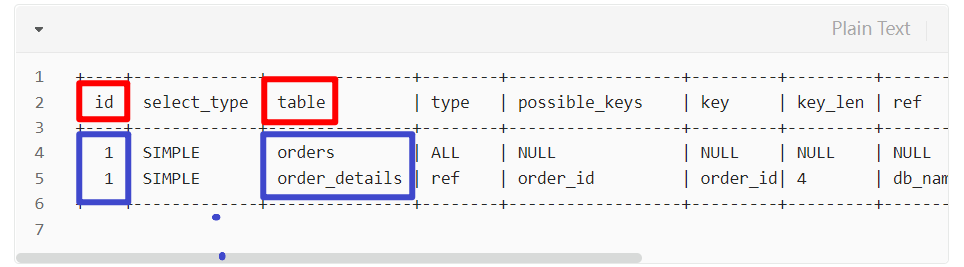
如何判断哪张表是驱动表?
- 可以使用explain查看一下SQL的执行计划,在输出的执行计划中,排在第一行的表是驱动表,排在第二行的表是被驱动表!
- 如上图,orders表为驱动表,order_details表为非驱动表~!
- 在SQL执行计划中,有一个id字段,这个是SQL执行计划中每个操作的唯一标识符,对于一条查询语句,每个操作都有一个唯一的id,但是在进行多表join的时候,一次explain中的多条记录的id是相同的,而排在前面的表会被作为驱动表先执行!
left join一定是左表作为驱动表吗?
- 当然不一定,因为这是MySQL的优化器决定的,当右表的数据量远远小于左表的时候,通过以右表作为驱动表可以更快的完成匹配操作;当右表上存在合适的索引或过滤条件,也可以通过右表作为驱动表来进行优化,更快的完成匹配操作!
1.1.3 分类
在多表查询当中,根据查询的形式,我们将其分为两大类:一类是连接查询,一类是子查询。
多表查询可以分为:
1. 连接查询
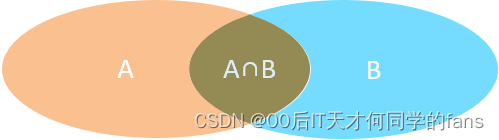
1. 内连接:相当于查询A表和B表,这两张表交集部分的数据
2. 外连接
左外连接:是以左表为基准,查询左表当中所有的数据(包括两张表交集部分的数据)
右外连接:是以右表为基准,查询右表所有数据(包括两张表交集部分的数据)
3. 全(外)连接
- 只不过MySQL不支持,但是有些数据库是支持的,比如Orcale支持全连接,使用 full outer join关键字!
2. 子查询:指的是在查询当中又嵌套了查询
---------------------------------------------------------------------------------------------------------------------------------
1.2 内连接
内连接查询:查询两张表或多张表中交集部分数据。
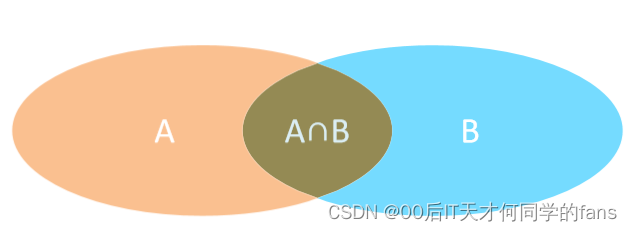
内连接从语法上可以分为:
-
隐式内连接
-
显式内连接

- 内连接中,驱动表是系统优化后自动选取的,会将执行计划中扫描次数少的表选做驱动表!
- 注意:使用 join 关键字后要使用 on 来确定连接条件,而不是where,在内连接中的where 和 on效果是等价的,但是一定要明确 on 用来声明连接条件,where 是筛选条件!
隐式内连接语法:
select 字段列表 from 表1 , 表2 where 条件 ... ;
显式内连接语法:
select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ;
-- =============================内连接============================== -- A.查询员工的姓名,及所属的部门名称(隐式内连接实现) -- 隐式内连接:select 字段列表 from 表1,表2 where 条件...; -- 提问:刚才所插入进来的员工表的测试数据一共有17条,为什么查询出来的结果只有16条呢? -- 因为第17条员工的数据它是没有分配部门的,既然没有分配部门,说明这条记录它和部门表是没有关系的 -- 内连接查询的是两张表交集部分的数据,即A表当中没有和B表产生关联的数据是查询不出来的 select tb_emp.name,tb_dept.name from tb_emp,tb_dept where tb_emp.dept_id = tb_dept.id; select tb_emp.name, tb_dept.name -- 分别查询返回两张表中的数据 from tb_emp,tb_dept -- 关联两张表 where tb_emp.dept_id = tb_dept.id; -- 连接查询条件消除笛卡尔积 -- 在多表查询时,如果表名较长写起来比较繁琐,可以给表起别名 select e.name as 员工姓名 , d.name as 部门名称 from tb_emp as e ,tb_dept as d where e.dept_id = d.id; -- B.查询员工的姓名,及所属的部门名称(显示内连接实现) -- 显式内连接:select 字段列表 from 表1 [inner] join 表2 on 连接条件...; select tb_emp.name,tb_dept.name from tb_emp inner join tb_dept on tb_emp.dept_id = tb_dept.id;
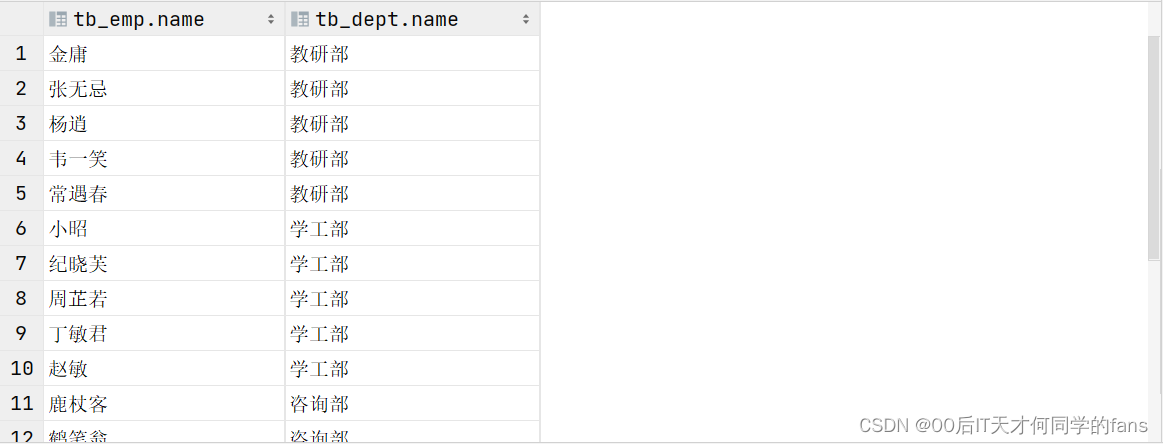
多表查询时给表起别名:
-
tableA as 别名1 , tableB as 别名2 ;
-
tableA 别名1 , tableB 别名2 ;

使用了别名的多表查询:
select emp.name , dept.name from tb_emp emp inner join tb_dept dept on emp.dept_id = dept.id;
注意事项:
一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字段。
1.3 外连接
内连接和外连接的区别:
- 对于内连接中的两张表,若驱动表中的记录在被驱动表中找不到与之匹配的记录,则该记录不会被加入到最后的结果集当中。
- 对于外连接中的两张表,即使驱动表中的记录在被驱动表中找不到与之匹配的记录,也要将该记录加入到最后的结果集当中。
针对不同的驱动表的选择,又可以将外连接分为左外连接和右外连接。
所以:
- 对于左外连接查询的结果会包含左表的所有数据; => 驱动表选择了左边那张表(左表)
- 对于右外连接查询的结果会包含右表的所有数据。 => 驱动表选择了右边那张表(右表)
外连接分为两种:左外连接 和 右外连接。
-
左外连接:是以左表为基准,查询左表当中所有的数据(包括两张表交集部分的数据)
-
右外连接:是以右表为基准,查询右表所有数据(包括两张表交集部分的数据)
左外连接语法结构:
select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ;
- 左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。
右外连接语法结构:
select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ;
- 右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。

- 我们把left outer join左侧的这张表也就是表1叫做左表,右侧的表2叫做右表。
- 左外连接会完全包含左表,也就是表1当中的数据。中间outer关键字可以省略。
- 如果是右外连接,会完全包含右表,也就是表2当中的数据。
-- =======================外连接================================
-- A.查询员工表中 所有 员工的姓名,和对应的部门名称(左外连接)
-- 注意看,要查询返回所有员工的姓名
-- 左外连接:select 字段列表 from 表1 left [outer] join 表2 on 连接条件...;
-- 由于是左外连接,因此会完全包含左表的数据,也就是tb_emp员工表的数据
select emp.name, dept.name
from tb_emp as emp
left join tb_dept as dept on emp.dept_id = dept.id;
-- B.查询部门表中 所有 部门的名称,和对应的员工名称(右外连接)
-- 注意看,要查询返回所有部门的名称
-- 右外连接会完全包含右表的数据,即使右表当中有一部分数据和左表没有关联,也会查询出来
select emp.name as 员工姓名, dept.name as 部门名称
from tb_emp as emp
right join tb_dept as dept on emp.dept_id = dept.id;
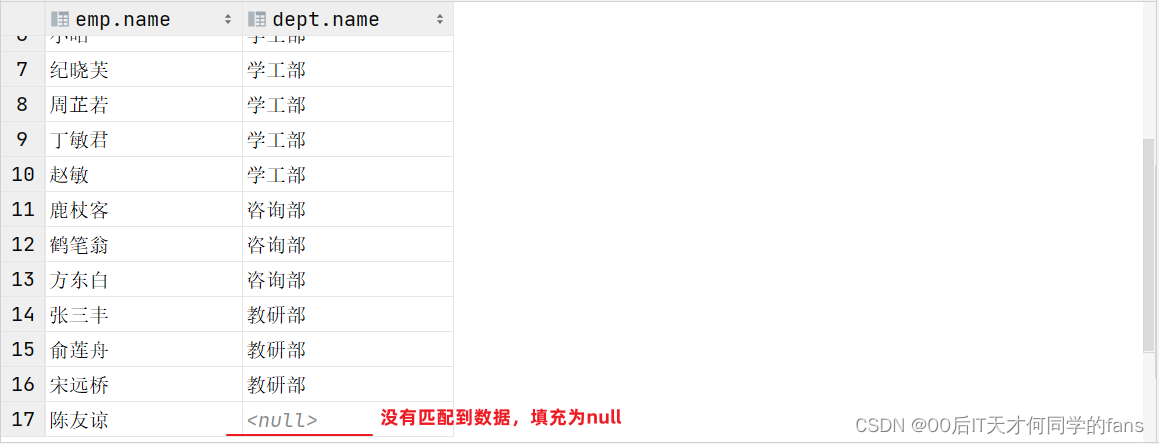

注意事项:
在我们项目开发当中,基本上使用的都是左外连接,右外连接使用的比较少,因为右外连接可以替换成左外连接。
左外连接和右外连接是可以相互替换的,只需要调整连接查询时SQL语句中表的先后顺序就可以了。而我们在日常开发使用时,更偏向于左外连接。
1.4 子查询(嵌套查询)
1.4.1 介绍

子查询:指的是在查询当中又嵌套了查询。
所谓子查询指的就是在SQL语句当中嵌套select查询语句,我们把嵌套的这个select查询语句叫做嵌套查询,也称为子查询。
这条查询语句的查询条件是取决于另外一个查询语句的。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ... );
- 子查询外部的语句可以是insert / update / delete / select 的任何一个,最常见的是 select。
根据子查询返回的结果不同,我们将子查询分为四类,根据子查询结果的不同分为:
-
标量子查询:子查询返回的结果为单个值[一行一列]
-
列子查询:子查询返回的结果为一列,但可以是多行
-
行子查询:子查询返回的结果为一行,但可以是多列
-
表子查询:子查询返回的结果为多行多列[相当于子查询结果是一张表]
表子查询指的是子查询返回的结果为多行多列,就相当于子查询返回的结果又是一张表。
子查询可以书写的位置:
-
where之后
-
from之后
-
select之后
1.4.2 标量子查询
- 子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
- 常用的操作符: = <> > >= < <=

-- ======================子查询=============================== -- 标量子查询:子查询返回的结果是一个单行单列的值 -- A.查询 "教研部" 的所有员工信息 -- 首先明确"教研部"是部门ID -- a.查询 教研部 的部门ID --- tb_dept select id from tb_dept where name = '教研部'; #查询结果:2 -- b.再查询该部门ID下的员工信息 --- tb_emp select * from tb_emp where dept_id = 2; -- 合并以上两条SQL语句,改写成一行 select * from tb_emp where dept_id = (select id from tb_dept where name = '教研部'); -- B.查询在 "方东白" 入职之后的员工信息 -- a.查询"方东白"的入职时间 select entrydate from tb_emp where name = '方东白'; -- b.再查询大于该入职时间的员工信息 select * from tb_emp where entrydate > '2012-11-01'; -- 合并以上两条SQL语句,改写成一行 select * from tb_emp where entrydate > (select entrydate from tb_emp where name = '方东白');
1.4.3 列子查询
- 子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
- 常用的操作符:in 、not in等
常用的操作符:
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
-- 列子查询:子查询返回的结果是一列多行
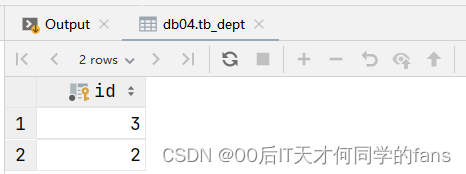
-- Example:查询 "教研部" 和 "咨询部" 的所有员工信息
-- a.查询 "教研部" 和 "咨询部" 的部门ID --- tb_dept
-- 方式一:使用or关键字连接多个条件
select id from tb_dept where name = '教研部' or name = '咨询部'; #查询结果:3,2
-- 方式二:in关键字
select id from tb_dept where name in('教研部','咨询部'); #查询结果:3,2
-- b.根据部门ID,查询该部门下的员工信息 --- tb_emp
-- 方式一:使用or关键字连接多个条件
select * from tb_emp where dept_id = 3 or dept_id = 2;
-- 方式二:in关键字
select * from tb_emp where dept_id in (3,2);
-- 合并以上两条SQL语句,改写成一行
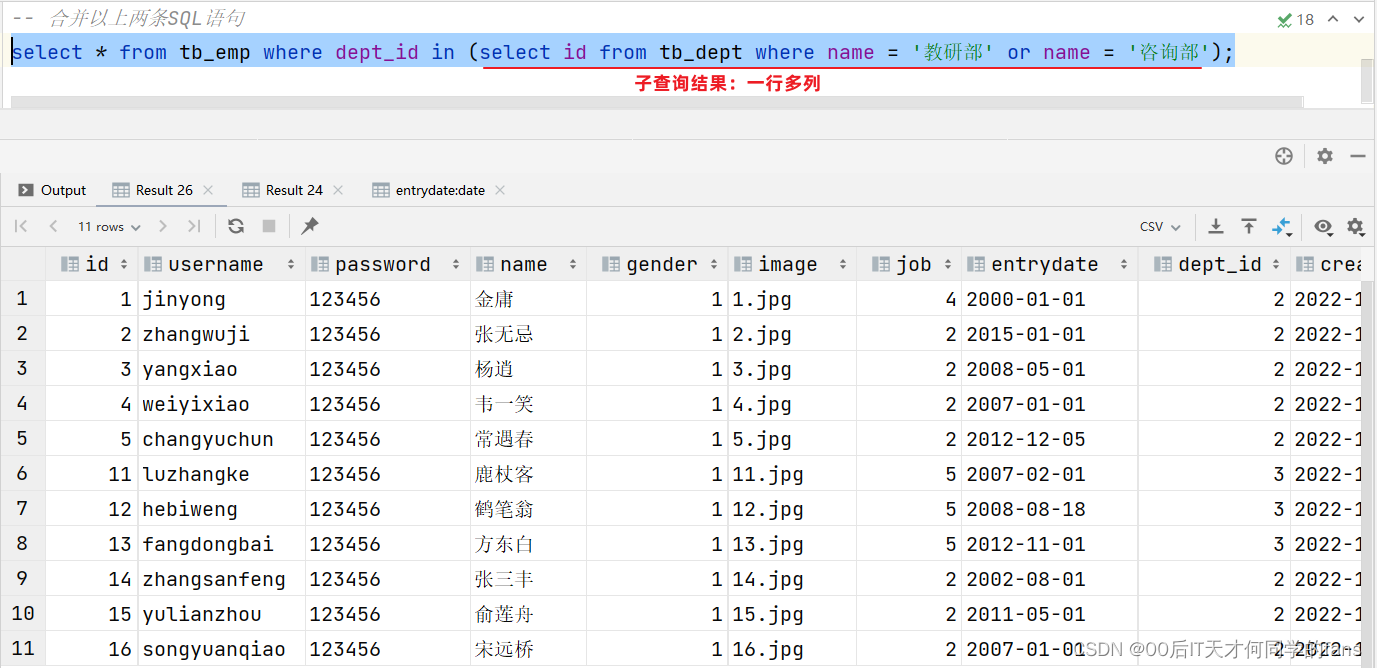
select * from tb_emp where dept_id in (select id from tb_dept where name in ('教研部','咨询部'));
1.4.4 行子查询
- 子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
- 常用的操作符:= 、<> 、IN 、NOT IN
-- 行子查询:查询返回的结果是一行多列
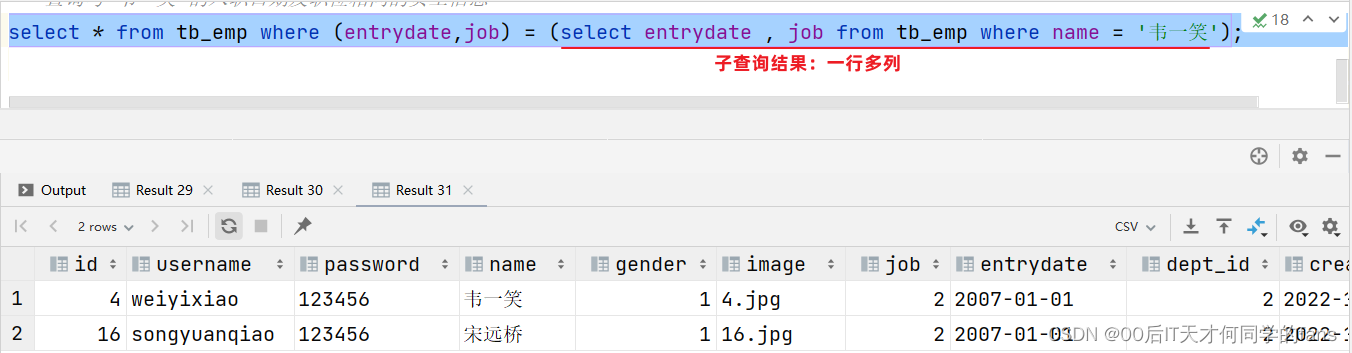
-- Example:查询与 "韦一笑" 的入职日期及职位都相同的员工信息;
-- a.查询 "韦一笑" 的 入职日期 及 职位
select entrydate,job from tb_emp where name = '韦一笑'; #查询结果: 2007-01-01 , 2
-- b.查询与其入职日期 及 职位 都相同的员工信息
select * from tb_emp where entrydate = '2007-01-01' and job = 2;
-- 合并以上两条SQL语句,改写成一行
select *
from tb_emp
where entrydate = (select entrydate from tb_emp where name = '韦一笑')
and job = (select job from tb_emp where name = '韦一笑');
-- 该SQL语句出现了多次子查询,性能其实并不高
-- 提问:怎么对这条SQL语句进行优化
-- 启发
select * from tb_emp where entrydate = '2007-01-01' and job = 2;
-- 改造
select * from tb_emp where (entrydate,job) = ('2007-01-01',2);
-- 正式改造,改造后只有一条子查询
select * from tb_emp where (entrydate,job) = (select entrydate,job from tb_emp where name = '韦一笑');
1.4.5 表子查询
- 表子查询指的是子查询返回的结果为多行多列,就相当于子查询返回的结果又是一张表。
- 子查询返回的结果是多行多列,常作为临时表来使用,这种子查询称为表子查询。
- 既然是作为一张临时表,就经常会出现在select语句的from之后
- 常用的操作符:in
-- 表子查询:子查询返回的结果是多行多列,常作为临时表来使用
-- Example:查询入职日期是 "2006-01-01" 之后的员工信息,及其部门名称
-- a.查询入职日期是 "2006-01-01" 之后的员工信息
select * from tb_emp where entrydate > '2006-01-01'; #查询到一共有14条记录
-- 基于查询到的员工信息,在查询对应的部门信息
-- 把上面这条SQL语句查询返回的结果作为一张临时表来使用
-- b.查询这部分员工信息及其部门名称
-- [表名.*] 就代表这张表的所有信息
-- 这是隐式内连接查询,注意:陈友谅入职时间是2015-03-21,但是并没有查询到陈友谅的信息
-- 因为内连接查询的是两张表交集部分的数据
select emp.*, dept.name
from (select * from tb_emp where entrydate > '2006-01-01') as emp,
tb_dept as dept
where emp.dept_id = dept.id; #查询到一共有13条记录,少了陈友谅
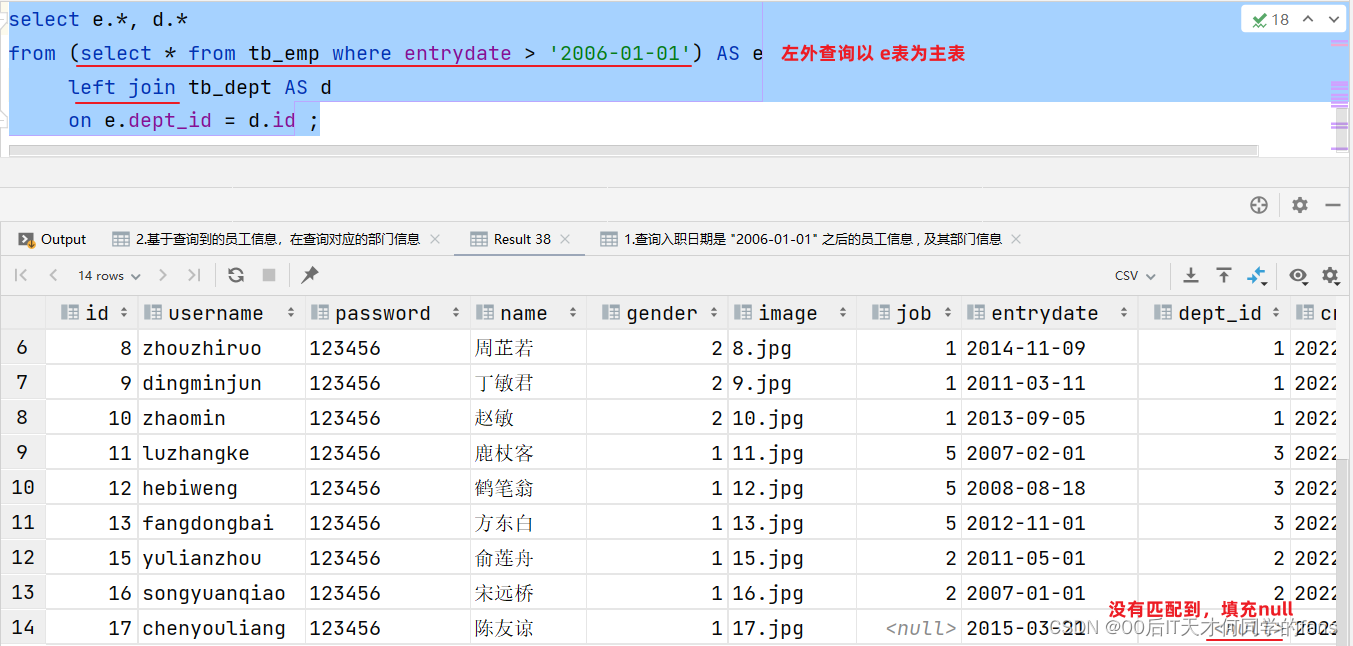
-- 改进上述SQL语句,使其能够查询到陈友谅的信息
-- 使用左外连接,使其员工表为左表
-- 因为左外连接是以左表为基准,查询左表当中所有的数据
select emp.*, dept.name
from (select * from tb_emp where entrydate > '2006-01-01') as emp
left join tb_dept as dept on emp.dept_id = dept.id;
1.5 exists型子查询
- 表示判断子查询是否有返回值,有则返回 true,没有则返回 false,这类子查询使用的并不是很多!
SELECT * FROM teacher t WHERE EXISTS ( SELECT * FROM course c WHERE c.t_id = t.id );
到此这篇关于MySQL --- 多表查询 & 驱动表的文章就介绍到这了,更多相关内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文地址:https://blog.csdn.net/weixin_53622554/article/details/130642217
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









