
MySQL知识:MySQL的自增主键是连续自增吗?

从开始接触MySQL,我们就知道在设计主键时,要设置为自增主键,使用自增主键有以下几个优点:
- 效率高:使用自增主键可以避免频繁生成主键值的操作,节省了数据库的资源,提高了查询效率。
- 索引优化:自增主键一般是整数类型,可以方便地使用B-tree索引来加速数据查询。
- 数据唯一性:自增主键可以保证数据的唯一性,防止重复插入数据。
- 方便性:使用自增主键可以方便地进行更新、删除和查询操作,不需要复杂的联合主键或其他索引操作。
我们在使用自增主键统计数据库的数据量时,也会经常使用id的最大值与最小值之间的差值作为数据库当前已有数据的条数,但是这种统计方式是否正确?是否存在误差?
笔者先给出本文结论:自增主键可以保持主键递增顺序插入,避免页分裂,索引更为紧凑,但是自增主键并不能保证连续递增,即出现空洞。
但是问题再次出现,为什么明明是自增主键,为什么不能保证连续递增?为什么会出现空洞?
在本文中,我们使用如下的数据库配置:
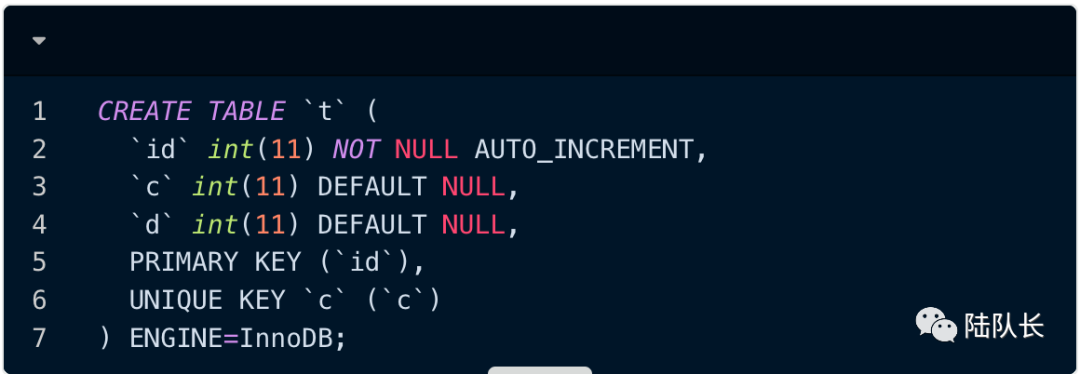
1 自增值的存储
在如上的空表 t 里面执行 insert into t values(null, 1, 1); 插入一行数据,再执行 show create table 命令,就可以看到如下图所示的结果:
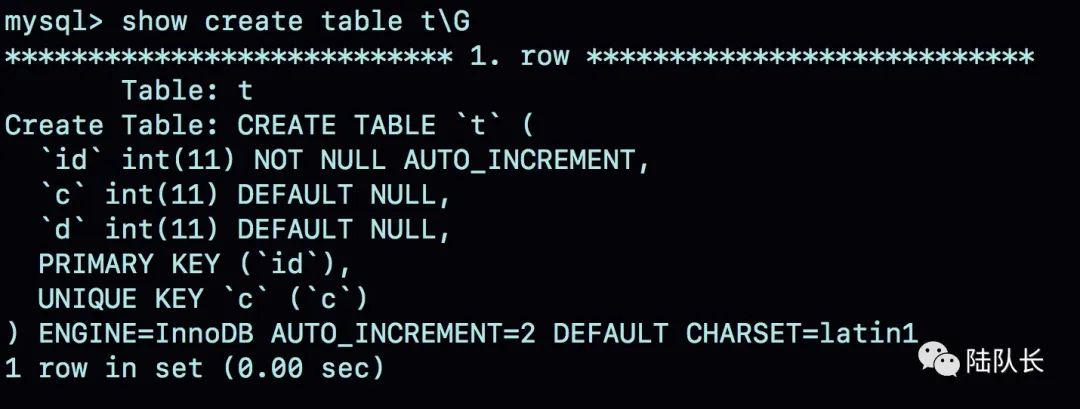
表定义里面出现了一个 AUTO_INCREMENT=2,表示下一次插入数据时,如果需要自动生成自增值,会生成 id=2。
不同的引擎对于自增至的保存策略不同:
- MyISAM 引擎的自增值保存在数据文件中。
- InnoDB 引擎的自增值,其实是保存在了内存里,并且到了 MySQL 8.0 版本后,才有了“自增值持久化”的能力,也就是才实现了“如果发生重启,表的自增值可以恢复为 MySQL 重启前的值”,具体情况是:
- 在 MySQL 5.7 及之前的版本,自增值保存在内存里,并没有持久化。每次重启后,第一次打开表的时候,都会去找自增值的最大值 max(id),然后将 max(id)+1 作为这个表当前的自增值。举例来说,如果一个表当前数据行里最大的id 是10,AUTO_INCREMENT=11。这时候,我们删除 id=10 的行,AUTO_INCREMENT 还是 11。但如果马上重启实例,重启后这个表的 AUTO_INCREMENT 就会变成 10。也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
- 在 MySQL 8.0 版本,将自增值的变更记录在了 redo log 中,重启的时候依靠 redo log 恢复重启之前的值。
2 自增值修改机制
在 MySQL 里面,如果字段 id 被定义为 AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下:
- 如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段;
- 如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。
根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。假设,某次要插入的值是 X,当前的自增值是 Y。
- 如果 X
- 如果 X≥Y,就需要把当前自增值修改为新的自增值。
新的自增值生成算法是:从 auto_increment_offset 开始,以 auto_increment_increment 为步长,持续叠加,直到找到第一个大于 X 的值,作为新的自增值。其中,auto_increment_offset 和 auto_increment_increment 是两个系统参数,分别用来表示自增的初始值和步长,默认值都是 1。
但是在一些场景下,使用的就不全是默认值。比如,双 M 的主备结构里要求双写的时候,我们就可能会设置成 auto_increment_increment=2,让一个库的自增 id 都是奇数,另一个库的自增 id 都是偶数,避免两个库生成的主键发生冲突。
当 auto_increment_offset 和 auto_increment_increment 都是 1 的时候,新的自增值生成逻辑很简单,就是:
- 如果准备插入的值 >= 当前自增值,新的自增值就是“准备插入的值 +1”;
- 否则,自增值不变。
3 自增值修改时机
3.1 唯一键冲突
假设表t有了存在(1,1,1)这条记录,再次执行一次数据命令:
insert into t values(null, 1, 1);
这个语句的执行流程就是:
- 执行器调用 InnoDB 引擎接口写入一行,传入的这一行的值是 (0,1,1);
- InnoDB 发现用户没有指定自增 id 的值,获取表 t 当前的自增值 2;
- 将传入的行的值改成 (2,1,1);
- 将表的自增值改成 3;
- 继续执行插入数据操作,由于已经存在 c=1 的记录,所以报 Duplicate key error,语句返回。
可以看到,这个表的自增值修改为3之后也不会再回退,之后再插入拿到的自增id就是3,自增主键不再连续。
3.2 事务回滚
insert into t values(null,1,1); begin; insert into t values(null,2,2); rollback; insert into t values(null,2,2); //插入的行是(3,2,2)
如上语句就会出现不连续自增id的情况。MySQL不允许做回退,看如下的假设:假设有两个并行执行的事务,在申请自增值时,为了避免两个事务申请到相同自增id,肯定加锁,然后顺序申请。
- 假设事务A申请到了id=2,事务B申请到id=3,那么表t的自增值是4,之后继续执行;
- 事务B正确提交后,事务A出现唯一键冲突;
- 如果允许事务A把自增id回退,也就是表t当前自增值改回2;
- 接下来继续执行的其他事务就会申请到id=2,然后再申请id=3,就会出现插入语句报错“主键冲突";
为了解决这个主键冲突,有两种方法:
- 每次申请 id 之前,先判断表里面是否已经存在这个 id。如果存在,就跳过这个 id。但是,这个方法的成本很高。因为,本来申请 id 是一个很快的操作,现在还要再去主键索引树上判断 id 是否存在。
- 把自增 id 的锁范围扩大,必须等到一个事务执行完成并提交,下一个事务才能再申请自增 id。这个方法的问题,就是锁的粒度太大,系统并发能力大大下降。
出于性能考虑,如果设计为必须连续,那就需要每次都去检查当前申请的ID是否已存在,浪费性能;或者提升锁粒度,会导致申请ID退化为串行申请
3.3 批量申请自增id策略
对于批量插入数据的语句,MySQL 有一个批量申请自增 id 的策略:
- 语句执行过程中,第一次申请自增 id,会分配 1 个;
- 1 个用完以后,这个语句第二次申请自增 id,会分配 2 个;
- 2 个用完以后,还是这个语句,第三次申请自增 id,会分配 4 个;
- 依此类推,同一个语句去申请自增 id,每次申请到的自增 id 个数都是上一次的两倍。
4 自增锁优化
自增id锁并不是一个事务锁,而是每次申请完就马上释放,以便允许别的事务再申请。
在MySQL 5.0版本的时候,自增锁的范围是语句级别。也就是说,如果一个语句申请了一个表自增锁,这个锁会等语句执行结束以后才释放。显然,这样设计会影响并发度。
MySQL 5.1.22版本引入了一个新策略,新增参数innodb_autoinc_lock_mode,默认值是1。
- 这个参数的值被设置为 0 时,表示采用之前 MySQL 5.0 版本的策略,即语句执行结束后才释放锁;
- 这个参数的值被设置为 1 时:
普通 insert 语句,自增锁在申请之后就马上释放;
类似 insert … select 这样的批量插入数据的语句,自增锁还是要等语句结束后才被释放;
- 这个参数的值被设置为 2 时,所有的申请自增主键的动作都是申请后就释放锁。
你一定有两个疑问:为什么默认设置下,insert … select 要使用语句级的锁?为什么这个参数的默认值不是 2?原因就是为了保证数据的一致性。
在生产上,尤其是有 insert … select 这种批量插入数据的场景时,从并发插入数据性能的角度考虑,我建议你这样设置:innodb_autoinc_lock_mode=2 ,并且 binlog_format=row. 这样做,既能提升并发性,又不会出现数据一致性问题。
需要注意的是,我这里说的批量插入数据,包含的语句类型是 insert … select、replace … select 和 load data 语句。
但是,在普通的 insert 语句里面包含多个 value 值的情况下,即使 innodb_autoinc_lock_mode 设置为 1,也不会等语句执行完成才释放锁。因为这类语句在申请自增 id 的时候,是可以精确计算出需要多少个 id 的,然后一次性申请,申请完成后锁就可以释放了。
也就是说,批量插入数据的语句,之所以需要这么设置,是因为“不知道要预先申请多少个 id”。
既然预先不知道要申请多少个自增 id,那么一种直接的想法就是需要一个时申请一个。但如果一个 select … insert 语句要插入 10 万行数据,按照这个逻辑的话就要申请 10 万次。显然,这种申请自增 id 的策略,在大批量插入数据的情况下,不但速度慢,还会影响并发插入的性能。
因此,对于批量插入数据的语句,MySQL 有一个批量申请自增 id 的策略:
- 语句执行过程中,第一次申请自增 id,会分配 1 个;
- 1 个用完以后,这个语句第二次申请自增 id,会分配 2 个;
- 2 个用完以后,还是这个语句,第三次申请自增 id,会分配 4 个;
- 依此类推,同一个语句去申请自增 id,每次申请到的自增 id 个数都是上一次的两倍。
原文地址:https://mp.weixin.qq.com/s/O6UuPJ_K_mzFSWvLlB_odw
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









