
Elasticsearch实现MySQL的Like效果

在Mysql数据库中,模糊搜索通常使用LIKE关键字。然而,随着数据量的不断增加,Mysql在处理模糊搜索时可能面临性能瓶颈。因此,引入Elasticsearch(ES)作为搜索引擎,以提高搜索性能和用户体验成为一种合理的选择。

一、客户的诉求
在ES中,影响搜索结果的因素多种多样,包括分词器、Match搜索、Term搜索、组合搜索等。有些用户已经养成了在Mysql中使用LIKE进行模糊搜索的习惯。若ES返回的搜索结果不符合用户的预期,可能会引发抱怨,甚至认为系统存在Bug。
谁让客户是上帝,客户是金主爸爸呢,客户有诉求,我们就得安排上。下面我们就聊聊如何用ES实现Mysql的like模糊匹配效果。
二、短语匹配match_phrase
1.定义
为实现模糊匹配的搜索效果,通常有两种方式,其中之一是match_phrase,先说说match_phrase。
match_phrase短语匹配会对检索内容进行分词,要求这些分词在被检索内容中全部存在,并且顺序必须一致。默认情况下,这些词必须是连续的。
2.实验
场景1:创建一个mapping,采用默认分词器(即每个字都当做分词),然后插入两条数据。注意:被搜索的字段先采用text类型。
# 创建mapping,这里的customerName先使用text类型
PUT /search_test
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"customerName": {
"type": "text"
}
}
},
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
# 插入2条数据
PUT /search_test/_create/1
{
"id": "111",
"customerName": "都是生产医院的人"
}
PUT /search_test/_create/2
{
"id": "222",
"customerName": "家电清洗"
}
# match_phrase短语匹配查询,可以查出结果
POST search_test/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"match_phrase": {
"customerName": "医院的"
}
}
]
}
}
}
以上操作结果显示可以查询到数据。如下图:
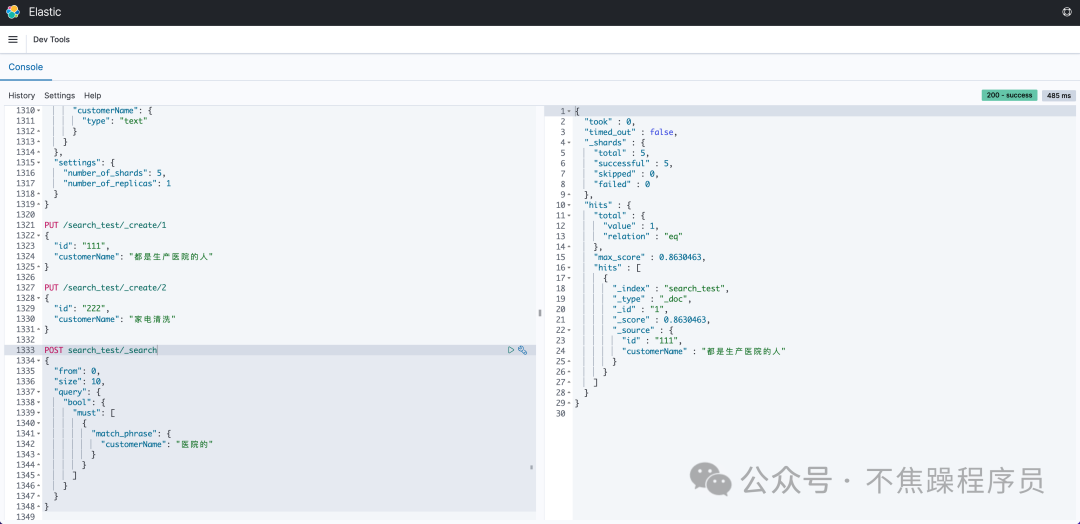
场景2:创建一个mapping,采用默认分词器,然后插入两条数据。注意:被搜索的字段先采用keyword类型。
# 创建mapping,这里的customerName先使用text类型
PUT /search_test2
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"customerName": {
"type": "keyword"
}
}
},
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
# 插入2条数据
PUT /search_test2/_create/1
{
"id": "111",
"customerName": "都是生产医院的人"
}
PUT /search_test2/_create/2
{
"id": "222",
"customerName": "家电清洗"
}
# match_phrase短语匹配查询,可以查出结果
POST search_test2/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"match_phrase": {
"customerName": "医院的"
}
}
]
}
}
}
以上操作结果显示查不到数据。如下图:
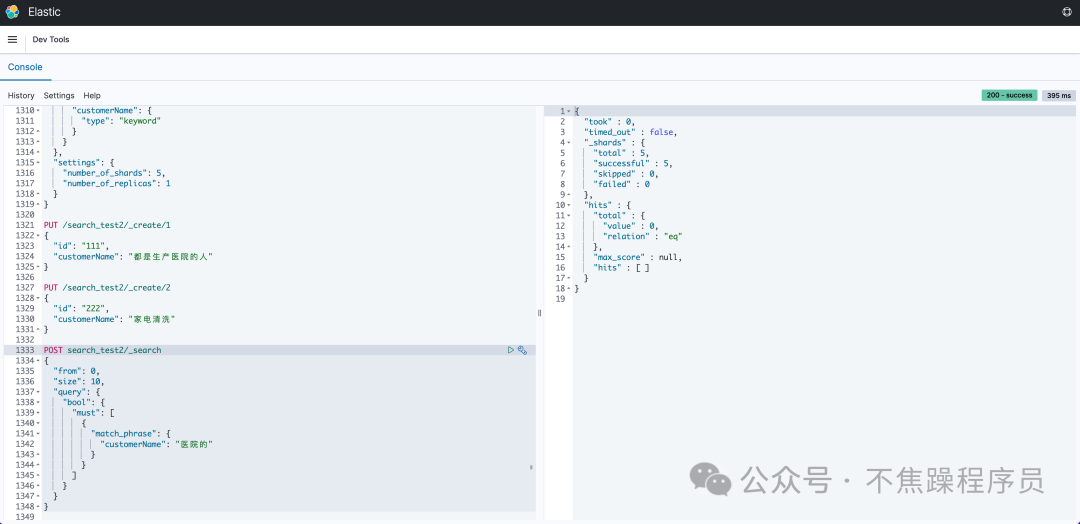
3.小结
match_phrase短语匹配适用于text类型的字段,实现了类似Mysql的like模糊匹配。然而,它并不适用于keyword类型的字段。
三、通配符匹配Wildcard
为实现模糊匹配的搜索效果,Wildcard通配符匹配是另一种常见的方式。下面我们详细介绍wildcard通配符查询。下面接着说Wildcard通配符查询。
1.定义
Wildcard Query 是使用通配符表达式进行查询匹配。Wildcard Query 支持两个通配符:
- ?,使用 ? 来匹配任意字符。
- *,使用 * 来匹配 0 或多个字符。
使用示例:
POST search_test/_search
{
"query": {
"wildcard": {
"customerName": "*测试*"
}
}
}
2.实验
场景1:创建一个mapping,采用默认分词器,然后插入两条数据。注意:被搜索的字段先采用text类型。使用上文已经创建的索引search_test。
# wildcard查询
POST search_test/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"wildcard": {
"customerName": {
"value": "*医院的*"
}
}
}
]
}
}
}
以上操作结果显示查不到数据,如下图:
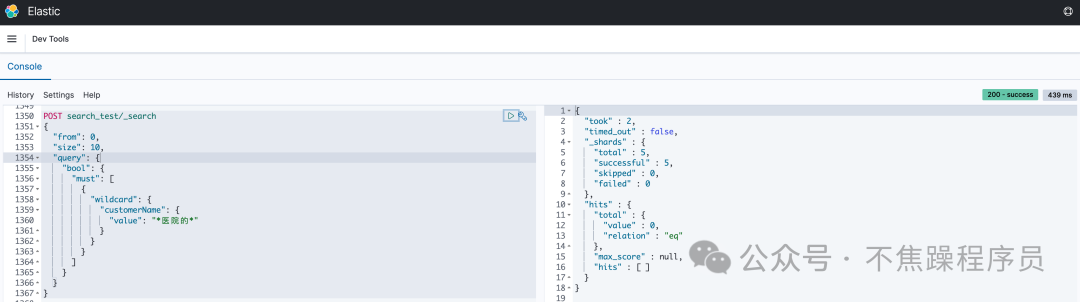
注意:如果将DSL查询语句改成只查“医”,就可以查到数据,这与分词器有关。默认分词器将每个字都切成分词。
# Wildcard查询
POST search_test/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"wildcard": {
"customerName": {
"value": "*医*"
}
}
}
]
}
}
}
场景2:创建一个mapping,采用默认分词器,然后插入两条数据。注意:被搜索的字段先采用keyword类型。使用上文已经创建的索引search_test2。
POST search_test2/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"wildcard": {
"customerName": {
"value": "*医院的*"
}
}
}
]
}
}
}
以上操作结果显示可以查到数据,如下图:
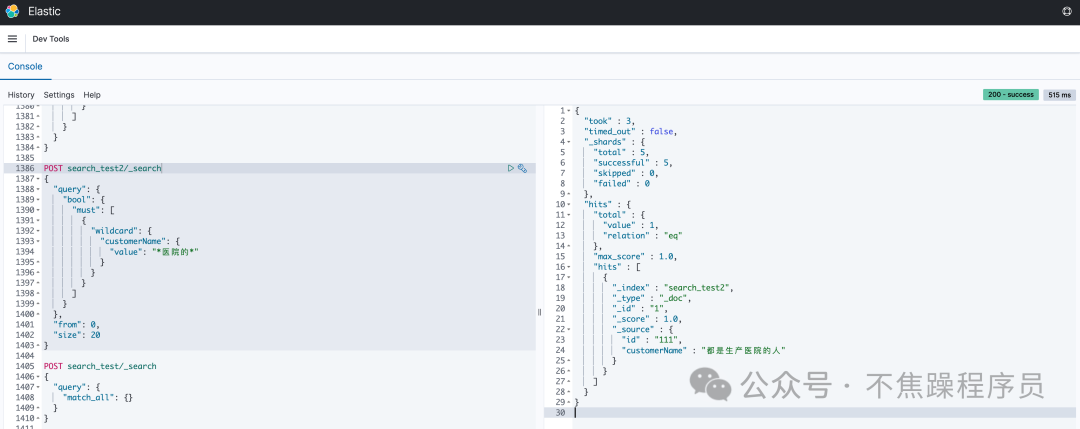
3.小结
Wildcard通配符查询适用于keyword类型的字段,实现了类似Mysql的like模糊匹配。然而,它不太适用于text类型的字段。
四、选择分词器
上述实验中均使用了默认分词器的结果。接下来,我们尝试使用IK中文分词器进行实验。
1.实验
创建一个名为search_test3的mapping,采用IK中文分词器,然后插入两条数据。注意:被搜索的字段先采用text类型。
PUT /search_test3
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"customerName": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
},
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
PUT /search_test3/_create/1
{
"id": "111",
"customerName": "都是生产医院的人"
}
PUT /search_test3/_create/2
{
"id": "222",
"customerName": "家电清洗"
}
执行搜索,比如搜索“医院的”,无论是match_phrase还是wildcard两种方式都查不到数据。
POST search_test3/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"match_phrase": {
"customerName": "医院的"
}
}
]
}
}
}
POST search_test3/_search
{
"query": {
"bool": {
"must": [
{
"wildcard": {
"customerName": {
"value": "*医院的*"
}
}
}
]
}
},
"from": 0,
"size": 20
}
执行搜索,比如搜索“医院”,match_phrase和wildcard两种方式都可以查到数据。
POST search_test3/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"match_phrase": {
"customerName": "医院"
}
}
]
}
}
}
POST search_test3/_search
{
"query": {
"bool": {
"must": [
{
"wildcard": {
"customerName": {
"value": "*医院*"
}
}
}
]
}
},
"from": 0,
"size": 20
}
4.小结
无论是match_phrase还是wildcard两种方式,它们的效果与选择的分词器密切相关。因为两者都是对分词进行匹配,只有匹配到了分词,才能找到对应的文档。
如果搜索内容正好命中了对应的分词,就可以查询到数据。如果没有命中分词,则查不到。在遇到问题时,可以使用DSL查询查看ES的分词情况:
POST _analyze
{
"analyzer": "ik_smart",
"text": "院的人"
}
POST _analyze
{
"analyzer": "ik_smart",
"text": "医院的"
}
POST _analyze
{
"analyzer": "ik_max_word",
"text": "都是生产医院的人"
}
五、总结
match_phrase和wildcard都能实现类似Mysql的like效果。然而,需要注意以下几点:
- 如果要完全实现Mysql的like效果,最好使用默认分词器,即每个字都切成分词。
- match_phrase短语匹配,适合于text类型的字段。
- Wildcard通配符查询,适合于keyword类型的字段。
原文地址:https://mp.weixin.qq.com/s?__biz=MzI3OTA2MDQyOQ==&mid=2247485183&idx=1&sn=b8415e166d24101ba9eb42d34d06ce50
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









