
MySQL:Innodb 唯一索引出现重复值的场景分析

最近遇到类似案例,这里将可能出现这种情况的2个场景描述一下,其中一种情况在翻看老叶的公众号有类似文章,如下,
故障案例:MySQL唯一索引有重复值,官方却说This is not a bug
我们分别描述。

场景1 unique_checks = 0
1.原理
当我们进行数据插入的时候,对于唯一索引,实际上大概会经历数据查找,唯一性检查、数据插入 3个阶段。而对于普通索引来讲如果page不在buffer pool中则可能在数据查找阶段就会写入到ibuff,这种情况就等待后续的ibuff合并即可。
但是我们一旦设置了unique_checks=0,对于唯一索引(非主键)而言也可能走普通索引的方式,我们大概看看是如何改变的,首先根据设置,事务检查唯一索引的标记会设置为如下,
trx->check_unique_secondary =
!thd_test_options(thd, OPTION_RELAXED_UNIQUE_CHECKS);
然后在插入阶段,row_ins_sec_index_entry_low函数首先会根据是否检查唯一性将search_mode 设置上BTR_IGNORE_SEC_UNIQUE标记,search_mode 的值很多,主要包含2类,A:读写锁模式/B:操作方式,他们各自占用不同的bit位。
if (!thr_get_trx(thr)->check_unique_secondary) {search_mode |= BTR_IGNORE_SEC_UNIQUE;}
接下来就是查找数据调用btr_cur_search_to_nth_level上层函数,进行数据定位,然后在其中判定,
case BTR_INSERT:
btr_op = (latch_mode & BTR_IGNORE_SEC_UNIQUE)
? BTR_INSERT_IGNORE_UNIQUE_OP
: BTR_INSERT_OP;
break;
如果为insert且latch_mode带有BTR_IGNORE_SEC_UNIQUE,设置btr_op为BTR_INSERT_IGNORE_UNIQUE_OP。
最后在判定是否能够使用ibuf上,我们看到如下,
if (btr_op != BTR_NO_OP &&
ibuf_should_try(index, btr_op != BTR_INSERT_OP)) { //是否进入 ibuf
/* Try to buffer the operation if the leaf
page is not in the buffer pool. */
fetch = btr_op == BTR_DELETE_OP ? Page_fetch::IF_IN_POOL_OR_WATCH //这里和 WATCH和purge线程有光
: Page_fetch::IF_IN_POOL; //bug page get gen 只看是否在buffer中
}
而函数ibuf_should_try就是判定是否使用ibuf,一旦使用ibuf,当然修改的相关page就不一定非要在buffer pool中,因此对于insert操作定义为Page_fetch::IF_IN_POOL,而函数ibuf_should_try主要包含如下判定:
- A:开启了change buffer
- B:不等于系统表空间
- C:不能是聚集索引
- D:不能处于export状态下
- E:insert操作不能是唯一索引
- F:其他操作,唯一索引也可以使用ibuf,这里实际上就只剩下delete和ignore唯一性的insert了
而在底层修改操作实际上只有insert和delete操作,而这里满足的是F条件因此insert操作的查找page动作被标记为Page_fetch::IF_IN_POOL,接下来buf_page_get_gen函数就不会再去访问物理磁盘了,这个时候可能返回的page为NULL,那就要走这个逻辑了:
if (block == nullptr) { //如果block没有在innodb buffer中进行操作
...
switch (btr_op) {
case BTR_INSERT_OP:
case BTR_INSERT_IGNORE_UNIQUE_OP: //注意这里
...
if (ibuf_insert(IBUF_OP_INSERT, tuple, index, page_id, page_size,
cursor->thr)) {
cursor->flag = BTR_CUR_INSERT_TO_IBUF;
goto func_exit;
}
也就是插入到ibuf中,那么我们可以想象,如果设置了unique_checks=0,这个时候如果重复的数据在磁盘上(因为innodb buffer查询不到page返回NULL),则会将接下来的数据本该重复的数据插入到ibuf,而不会去检测重复值。然后等到需要读取这个page到buffer pool的时候比如select,那就需要做ibuf的合并,合并后重复的数据就出现了。
2.测试
测试可以根据老叶公众号的方式测试,主体思想就是做一个大一点的表,然后重启数据库,并且不要开启启动时加载page到buffer pool,下面是我测试的结果:
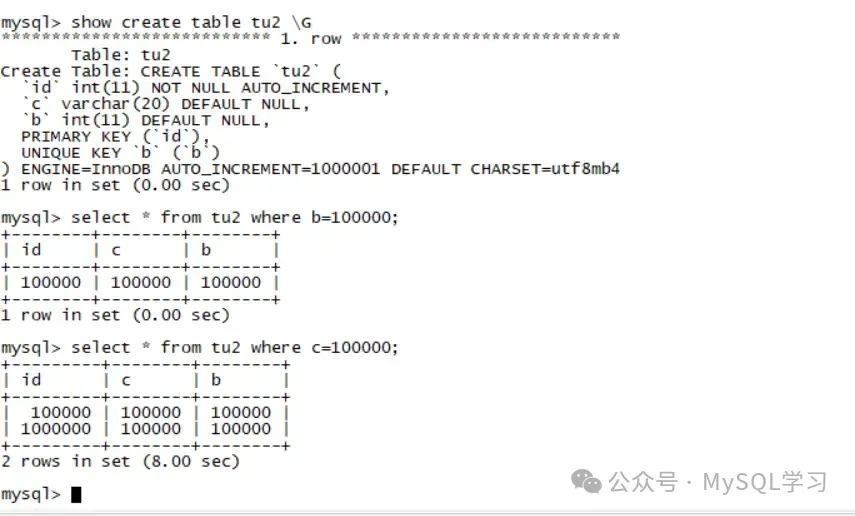
这里b列是一个唯一索引,我们看到了第二查询出现了2个相同的值。
3.其他和总结
当出现这种情况的时候可以看到,第一个查询只出现了一行,这看起来好像是对的,但是实际上索引上有2行不同的值,对于唯一索引来讲如果访问到一行值,访问就会停止,因此出现了这种情况,看起来也是比较奇特。 因此我们在考虑使用unique_checks=0加速导入数据的时候需要特别注意一下这个问题,除非能够保证数据都是唯一的否则不建议设置,现在我们知道实际上加速就是让唯一索引也能够使用ibuf这个特性,这里我们再来会看一下官方的这句话
For big tables, this saves a lot of disk I/O because InnoDB can use its change buffer to write secondary index records in a batch. Be certain that the data contains no duplicate keys.
很显然和我们分析一致。
场景2 RR隔离级别相关
这个地方主要和隔离级别有关了,虽然提出这个BUG的时间有点久了,但是这不是BUG,并且8.0也能重现,如下, https://bugs.mysql.com/bug.php?id=69979
重现如下:
建表和插入数据 create table testuniq(id int primary key,a int unique key); insert into testuniq values (10, 100), (20, 200); mysql> select * from testuniq; +----+------+ | id | a | +----+------+ | 10 | 100 | | 20 | 200 | +----+------+
TRX1 |
TRX2 |
1.begin; |
|
2.select * from testuniq; |
|
3.update testuniq set a=300 where id=10; |
|
4.update testuniq set a=100 where id=20; |
|
5.select * from testuniq; |
完成第四步的时候数据就是:
mysql> select * from testuniq; +----+------+ | id | a | +----+------+ | 10 | 100 | | 20 | 100 | +----+------+
可以看到唯一索引出现了重复值,对于这个问题,只要不阻止第4步的update testuniq set a=100 where id=20操作按照原理上来讲就会出现重复值,因为RR有一个read view在begin开始后第一个select语句后一直存在,而update属于当前读访问的当前记录已经被修改了,因此第4步并没有访问历史记录,因此update通过,最终出现这种现象。同时在BUG中也详细描述了这是符合设计的PG也是类似的结果,可以自行参考。
原文地址:https://mp.weixin.qq.com/s?__biz=MzkxMjI1MTI4OQ==&mid=2247484548&idx=1&sn=443b11a3cf003956d3ad78da0787319e
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








