
MySQL 原理与优化之Limit 查询优化


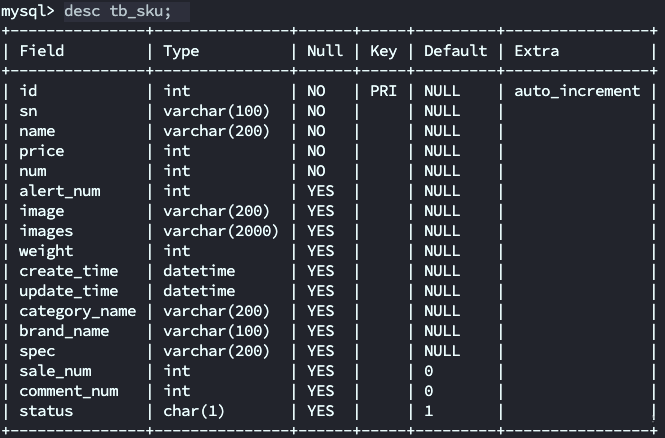
假设有表tb_sku,其表结构如下:
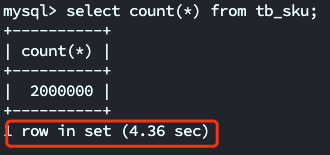
表中大约有200w条记录,执行如下的sql 语句大约 4.36s 返回数据
select count(*) from tb_sku;
接着我们使用 对其进行分页查找:
select * from tb_sku limit 0,10;
limit 语句 其中0 代表起始位置,10 为每页返回的数据数量。
如上图所示,很快就返回了查询结果。
接着我们再使用SQL 语句
select * from tb_sku limit 10,10;
语句从记录位置10的位置开始再往下返回10 条记录,也就是第二页的信息。其返回时间也是比较快。
然后,我们加大起始位置 到100w如下:
select * from tb_sku limit 1000000,10;

此时返回时间需要0.74 s,这说明了使用limit 对大数据量的表进行分页,位置越靠后效率越低。拿上面的例子来说,limit 会先对 100w 的数据进行排序,然后再返回10 条数据,而且仅仅返回100w 到 100w 零10条 的记录,其他查询的记录都会丢弃掉,这种做法查询排序的代价非常大。
由此我们需要对大数据量表进行limit 操作进行优化,官方给出的方案是通过覆盖索引和子查询的方式进行优化
根据这个思路首先对id 进行查询:
select id from tb_sku order by id limit 1000000,10;
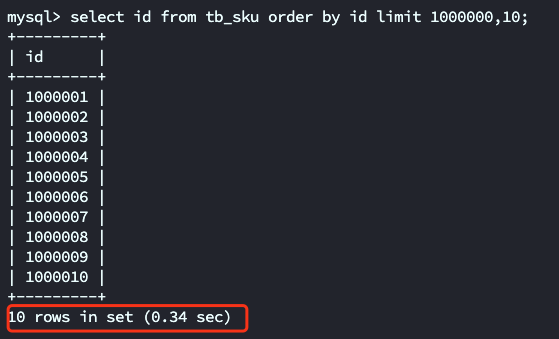
查询结果就只需要0.34s 比之前的0.74s要快多了。究其原因,因为直接返回id的信息,并没有进行回表操作,所以速度别select * 要快
由于我们需要获得select * 的信息,也就是tb_user 所有字段的信息,因此需要将上面的查询结果和tb_user 进行jion 操作。
select s.* from tb_sku s ,(select id from tb_sku order by id limit 1000000,10 ) t where s.id = t.id;
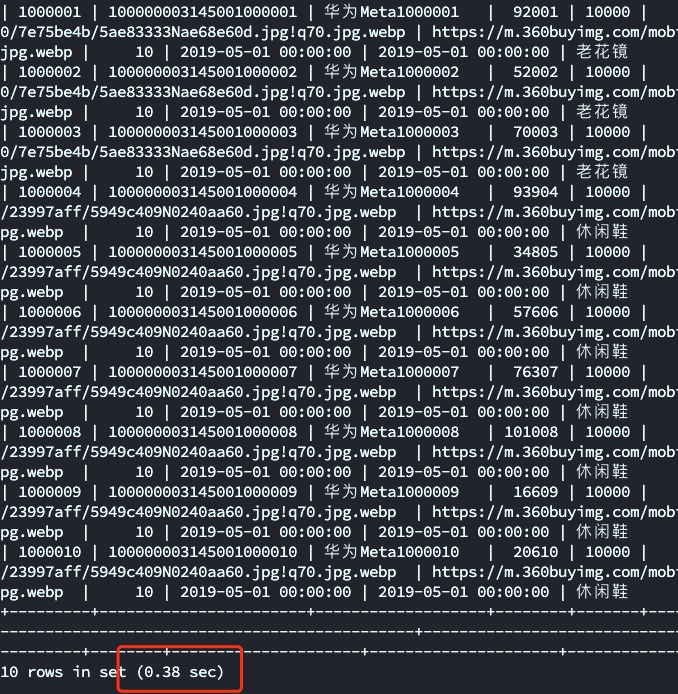
这里通过查询id 和子查询 的方式将查询结果缩短为 0.38s,比之前直接通过 select * 的方式要缩短一倍的查询时间。
到此这篇关于MySQL 原理与优化之Limit 查询优化的文章就介绍到这了,更多相关MySQL Limit 优化内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文地址:https://blog.51cto.com/u_14279308/5558674
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








