
MySQL之复杂查询的实现

1.排序
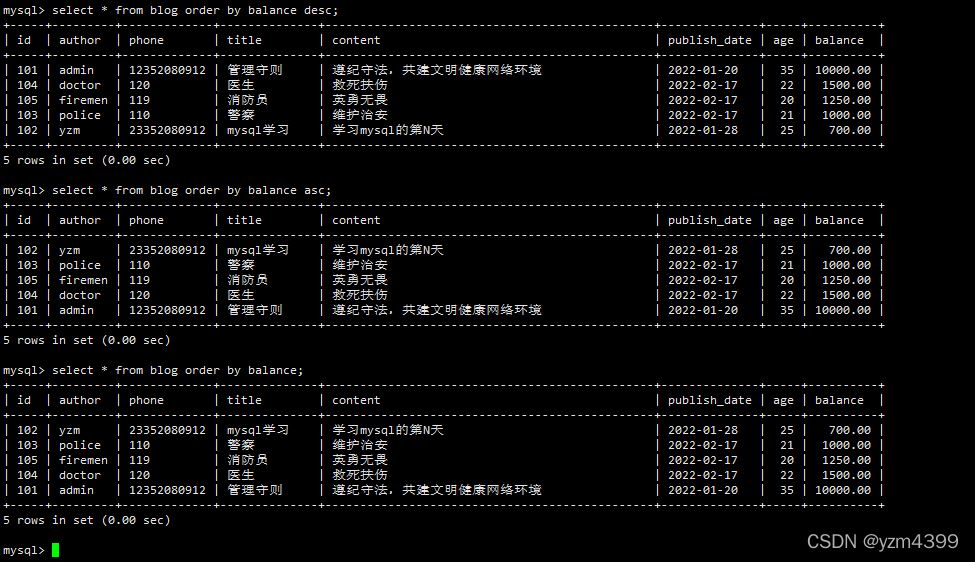
ORDER BY 子句来设定哪个字段哪种方式来进行排序,再返回搜索结果。
desc:降序
select * from blog order by balance desc;
asc:升序,默认,可不写
select * from blog order by balance asc;
多字段排序
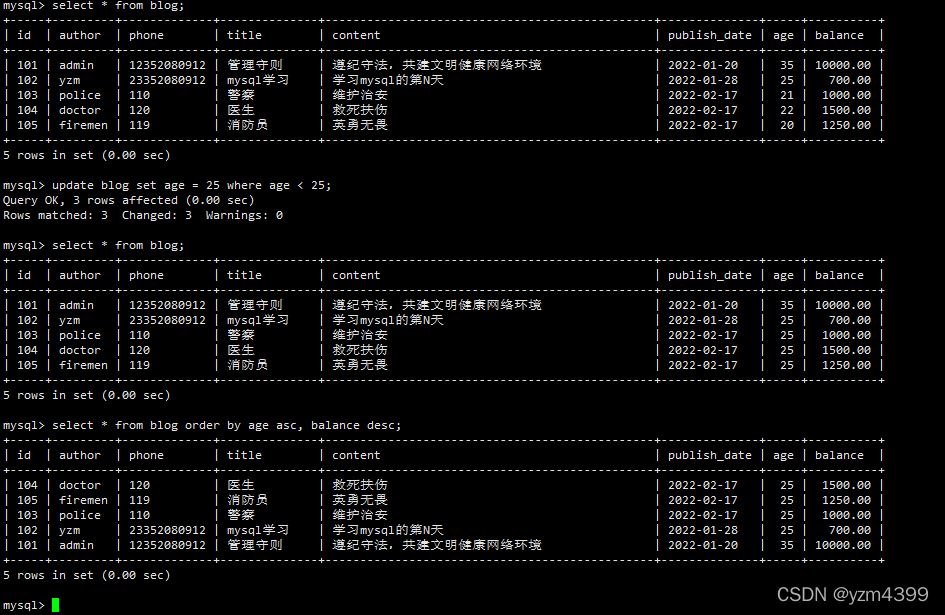
update blog set age = 25 where age < 25;
先根据年龄升序,再根据余额降序
select * from blog order by age asc, balance desc;
2.分组
GROUP BY 语句根据一个或多个列对结果集进行分组。
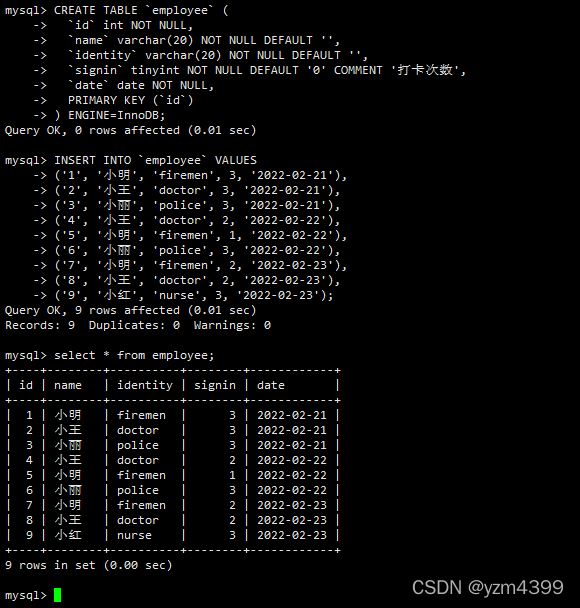
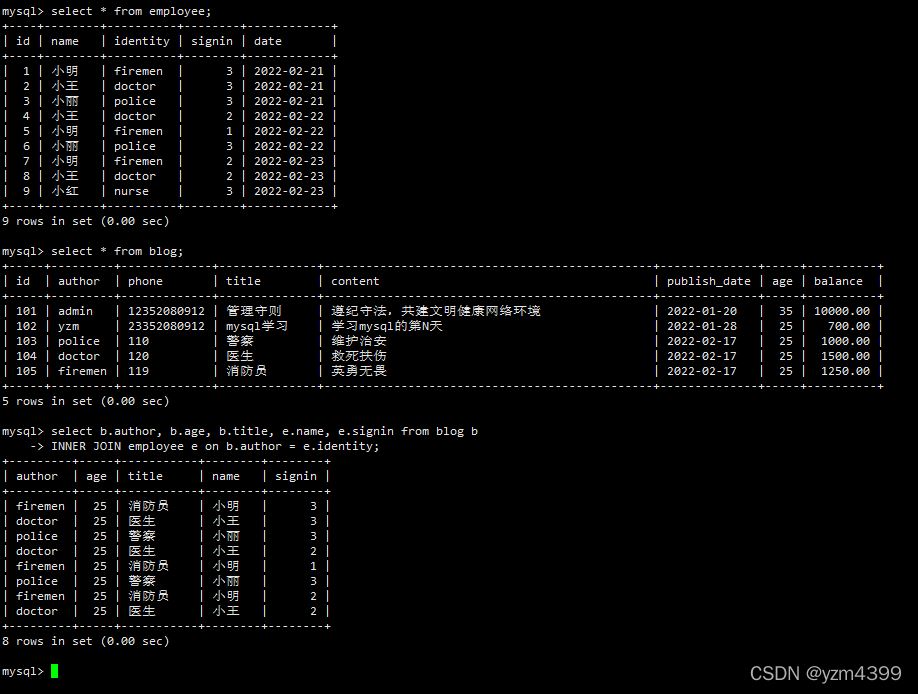
新建员工表
CREATE TABLE `employee` ( `id` int NOT NULL, `name` varchar(20) NOT NULL DEFAULT "", `identity` varchar(20) NOT NULL DEFAULT "", `signin` tinyint NOT NULL DEFAULT "0" COMMENT "打卡次数", `date` date NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB;
插入数据
INSERT INTO `employee` VALUES
("1", "小明", "firemen", 3, "2022-02-21"),
("2", "小王", "doctor", 3, "2022-02-21"),
("3", "小丽", "police", 3, "2022-02-21"),
("4", "小王", "doctor", 2, "2022-02-22"),
("5", "小明", "firemen", 1, "2022-02-22"),
("6", "小丽", "police", 3, "2022-02-22"),
("7", "小明", "firemen", 2, "2022-02-23"),
("8", "小王", "doctor", 2, "2022-02-23"),
("9", "小红", "nurse", 3, "2022-02-23");
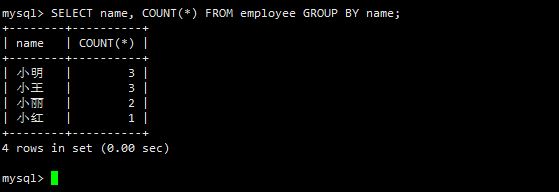
统计每人打卡记录数
SELECT name, COUNT(*) FROM employee GROUP BY name;
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)
统计每人打卡总数
SELECT name, SUM(signin) as signin_count FROM employee GROUP BY name WITH ROLLUP;
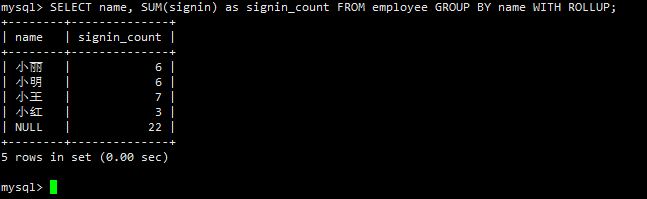
其中记录 NULL 表示所有人的登录次数。
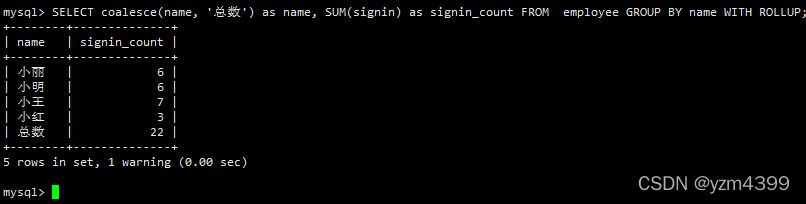
使用 coalesce 来设置一个可以取代 NUll 的名称
coalesce 语法:select coalesce(a,b,c);
SELECT name, SUM(signin) as signin_count FROM employee GROUP BY name WITH ROLLUP;
3.联合查询
UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。
UNION ALL:返回所有结果集,包含重复数据。
select author from blog UNION ALL select identity from employee;
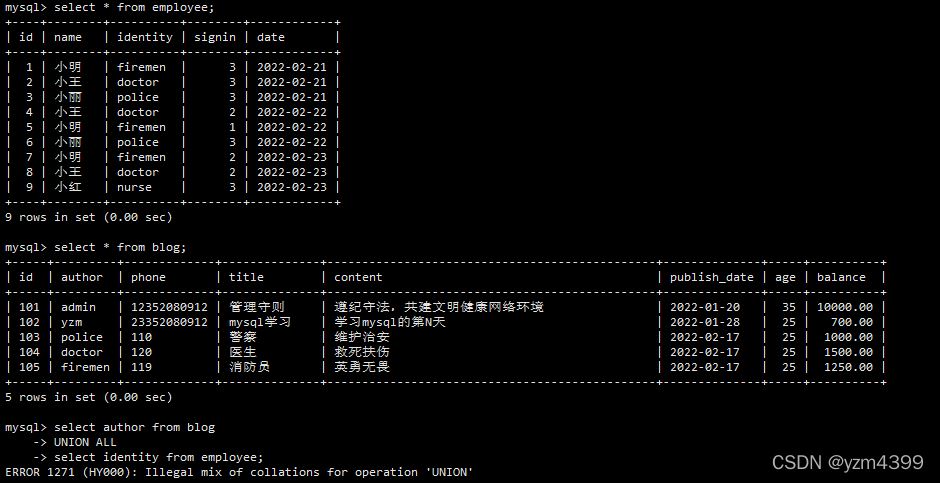
报错:Illegal mix of collations for operation ‘UNION’
原因:相同字段的编码不一致造成的
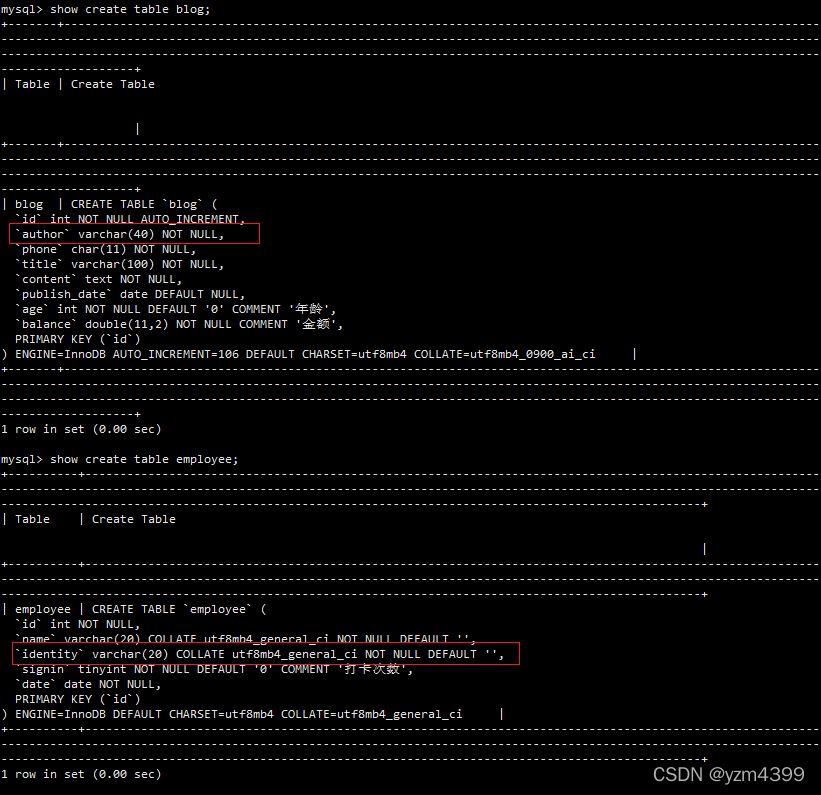
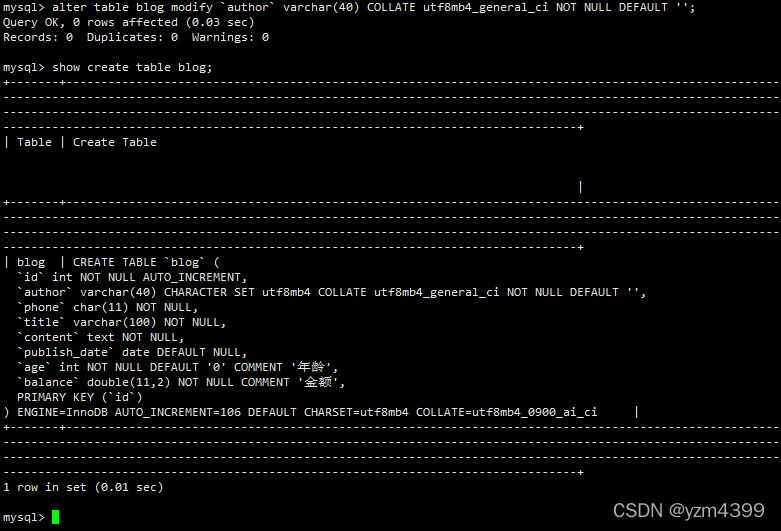
解决:修改blog表的author字段
alter table blog modify `author` varchar(40) COLLATE utf8mb4_general_ci NOT NULL DEFAULT "";
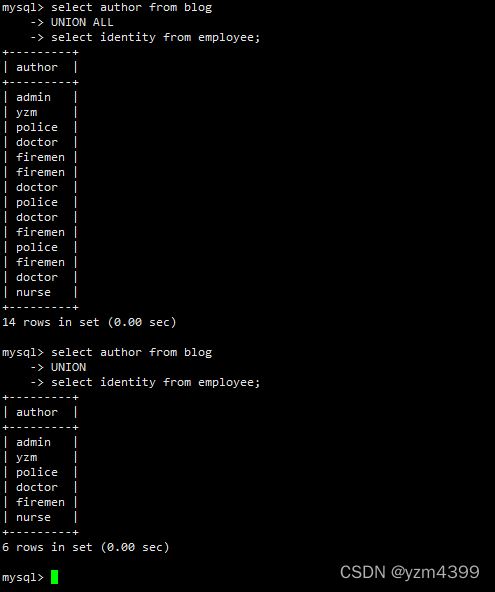
UNION DISTINCT: 删除结果集中重复的数据。默认,可不写
select author from blog UNION select identity from employee;
4.多表连接
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。 LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。 RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
内连接
INNER 可以省略
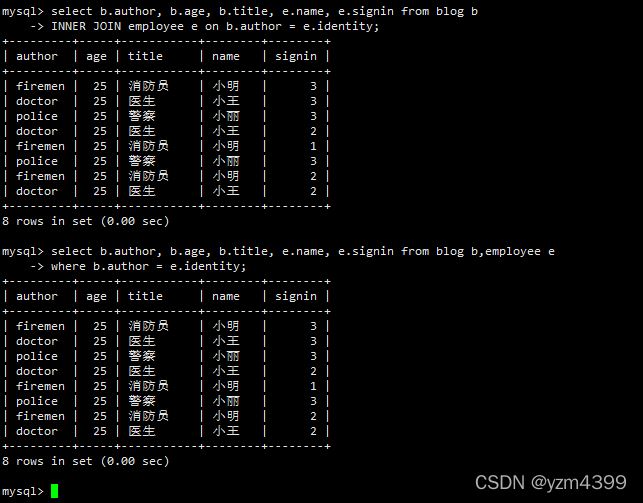
select b.author, b.age, b.title, e.name, e.signin from blog b INNER JOIN employee e on b.author = e.identity;
where条件实现内连接效果
select b.author, b.age, b.title, e.name, e.signin from blog b,employee e where b.author = e.identity;
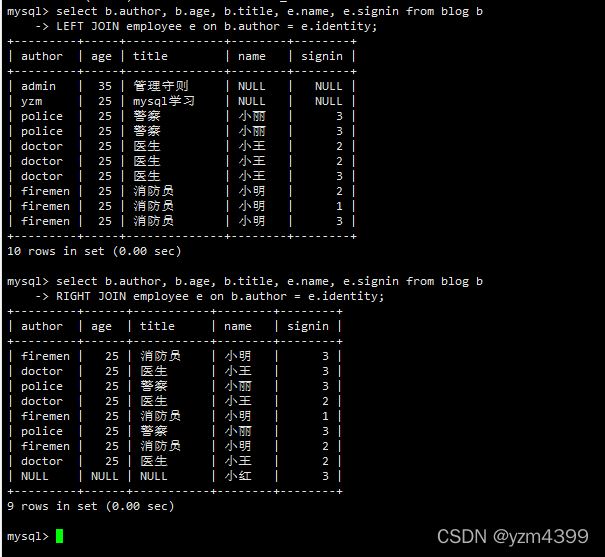
左连接:读取左边数据表的全部数据,即便右边表无对应数据。
select b.author, b.age, b.title, e.name, e.signin from blog b LEFT JOIN employee e on b.author = e.identity;
右连接:读取右边数据表的全部数据,即便左边边表无对应数据。
select b.author, b.age, b.title, e.name, e.signin from blog b RIGHT JOIN employee e on b.author = e.identity;
到此这篇关于MySQL之复杂查询的实现的文章就介绍到这了,更多相关MySQL 复杂查询内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.csdn.net/qq_43654581/article/details/122980185
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









