
MySQL 优化 index merge引起的死锁分析

背景
生产环境出现死锁流水,通过查看死锁日志,看到造成死锁的是两条一样的update语句(只有where条件中的值不同),
如下:
UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0;
一开始比较费解,通过大量查询跟学习后,分析出了死锁形成的具体原理,特分享给大家,希望能帮助到遇到同样问题的朋友。
因为MySQL知识点较多,这里对很多名词不进行过多介绍,有兴趣的朋友,可以后续进行专项深入学习。
死锁日志
*** (1) TRANSACTION: TRANSACTION 791913819, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 LOCK WAIT 4 lock struct(s), heap size 1184, 3 row lock(s) MySQL thread id 462005230, OS thread handle 0x7f55d5da3700, query id 2621313306 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913819 lock_mode X waiting Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) TRANSACTION: TRANSACTION 791913818, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 5 lock struct(s), heap size 1184, 4 row lock(s) MySQL thread id 462005231, OS thread handle 0x7f55cee63700, query id 2621313305 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0; *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913818 lock_mode X Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 41569 n bits 88 index `PRIMARY` of table `test`.`test_table` trx id 791913818 lock_mode X locks rec but not gap waiting Record lock, heap no 14 PHYSICAL RECORD: n_fields 30; compact format; info bits 0 *** WE ROLL BACK TRANSACTION (1)
简要分析下上边的死锁日志:
- 1、第一块内容(第1行到第9行)中,第6行为事务(1)执行的SQL语句,第7和第8行意思为事务(1)在等待 idx_status 索引上的X锁;
- 2、第二块内容(第11行到第19行)中,第16行为事务(2)执行的SQL语句,第17和第18行意思为事务(2)持有 idx_status 索引上的X锁;
- 3、第三块内容(第21行到第23行)的意思为,事务(2)在等待 PRIMARY 索引上的X锁。(but not gap指不是间隙锁)
- 4、最后一句的意思即为,MySQL将事务(1)进行了回滚操作。
表结构
CREATE TABLE `test_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, `trans_id` varchar(21) NOT NULL, `status` int(11) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uniq_trans_id` (`trans_id`) USING BTREE, KEY `idx_status` (`status`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
通过表结构可以看出,trans_id 列上有一个唯一索引uniq_trans_id ,status 列上有一个普通索引idx_status ,id列为主键索引 PRIMARY 。
InnoDB引擎中有两种索引:
- 聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。
- 辅助索引:辅助索引叶子节点存储的是主键值,也就是聚簇索引的键值。
主键索引 PRIMARY 就是聚簇索引,叶子节点中会保存行数据。uniq_trans_id 索引和idx_status 索引为辅助索引,叶子节点中保存的是主键值,也就是id列值。
当我们通过辅助索引查找行数据时,先通过辅助索引找到主键id,再通过主键索引进行二次查找(也叫回表),最终找到行数据。
执行计划
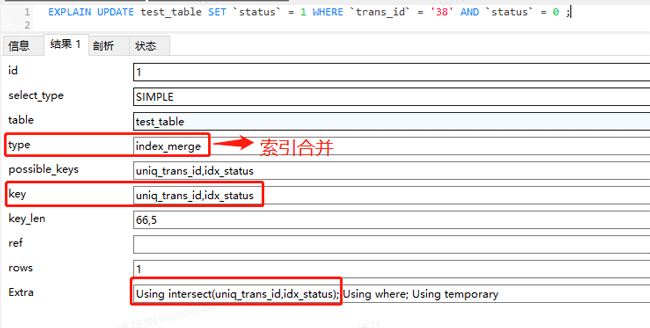
通过看执行计划,可以发现,update语句用到了索引合并,也就是这条语句既用到了uniq_trans_id索引,又用到了idx_status索引,Using intersect(uniq_trans_id,idx_status)的意思是通过两个索引获取交集。
为什么会用 index_merge(索引合并)
MySQL5.0之前,一个表一次只能使用一个索引,无法同时使用多个索引分别进行条件扫描。但是从5.1开始,引入了index merge优化技术,对同一个表可以使用多个索引分别进行条件扫描。
如执行计划中的语句:
UPDATE test_table SET `status` = 1 WHERE `trans_id` = '38' AND `status` = 0 ;
MySQL会根据trans_id = ‘38’这个条件,利用uniq_trans_id索引找到叶子节点中保存的id值;同时会根据status = 0这个条件,利用idx_status索引找到叶子节点中保存的id值;然后将找到的两组id值取交集,最终通过交集后的id回表,也就是通过 PRIMARY 索引找到叶子节点中保存的行数据。
这里可能很多人会有疑问了,uniq_trans_id已经是一个唯一索引了,通过这个索引最终只能找到最多一条数据,那MySQL优化器为啥还要用两个索引取交集,再回表进行查询呢,这样不是多了一次idx_status索引查找的过程么。我们来分析一下这两种情况执行过程。
第一种 只用uniq_trans_id索引 :
- 根据trans_id = ‘38’查询条件,利用uniq_trans_id索引找到叶子节点中保存的id值;
- 通过找到的id值,利用PRIMARY索引找到叶子节点中保存的行数据;
- 再通过status = 0条件对找到的行数据进行过滤。
第二种 用到索引合并Using intersect(uniq_trans_id,idx_status):
- 根据trans_id = ‘38’查询条件,利用uniq_trans_id索引找到叶子节点中保存的id值;
- 根据status = 0查询条件,利用idx_status索引找到叶子节点中保存的id值;
- 将1/2中找到的id值取交集,然后利用PRIMARY索引找到叶子节点中保存的行数据
上边两种情况,主要区别在于,第一种是先通过一个索引把数据找到后,再用其它查询条件进行过滤;第二种是先通过两个索引查出的id值取交集,如果取交集后还存在id值,则再去回表将数据取出来。
当优化器认为第二种情况执行成本比第一种要小时,就会出现索引合并。(生产环境流水表中status = 0的数据非常少,这也是优化器考虑用第二种情况的原因之一)。
为什么用了index_merge就死锁了
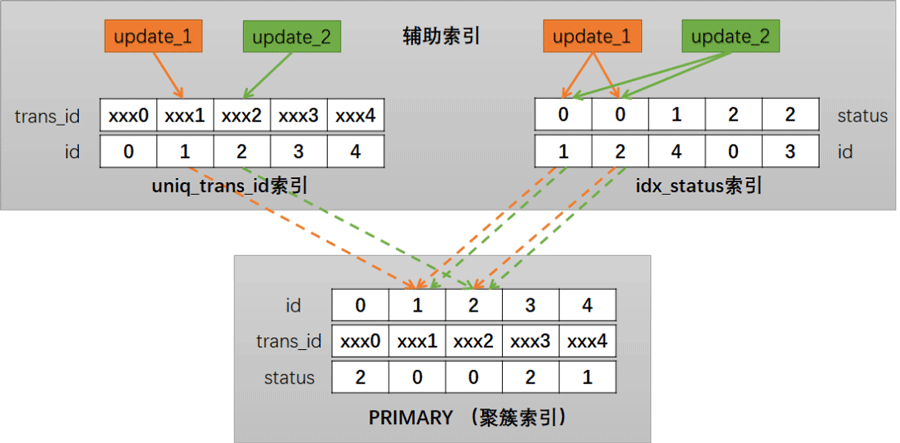
上面简要画了一下两个update事务加锁的过程,从图中可以看到,在idx_status索引和 PRIMARY (聚簇索引) 上都存在重合交叉的部分,这样就为死锁造成了条件。
如,当遇到以下时序时,就会出现死锁:
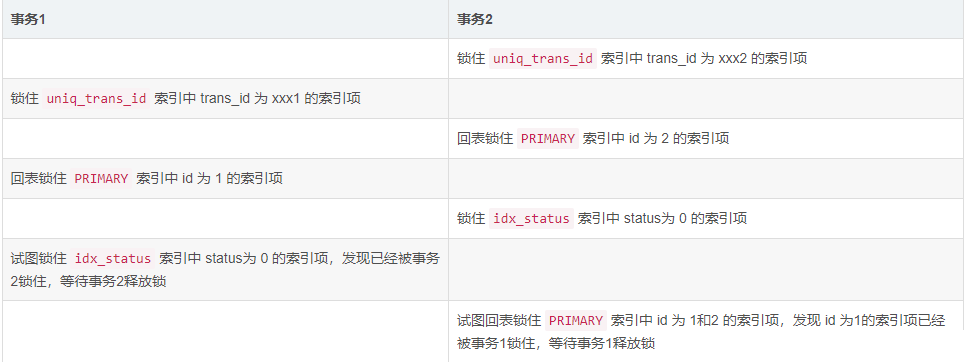
事务1等待事务2释放锁,事务2等待事务1释放锁,这样就造成了死锁。
MySQL检测到死锁后,会自动回滚代价更低的那个事务,如上边的时序图中,事务1持有的锁比事务2少,则MySQL就将事务1进行了回滚。
解决方案
一、从代码层面
- where 查询条件中,只传trans_id,将数据查询出来后,在代码层面判断 status 状态是否为0;
- 使用force index(uniq_trans_id)强制查询语句使用uniq_trans_id索引;
- where 查询条件后边直接用 id 字段,通过主键去更新。
二、从MySQL层面
- 删除idx_status索引或者建一个包含这俩列的联合索引;
- 将MySQL优化器的index merge优化关闭。
到此这篇关于MySQL 优化 index merge引起的死锁分析的文章就介绍到这了,更多相关MySQL 优化 index merge内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.51cto.com/u_14057963/5220807
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









