
系统性能排查方略及工商银行MySQL性能管控

一、系统性能问题五大特性
二、系统性能排查方略
三、MySQL开发规范和常见调优策略
四、MySQL性能管控体系
五、未来展望
一、系统性能问题五大特性

如果大家了解一些方法论的话,应该听过两个原则:一个是海恩法则,强调量变引发质变;另一个是老生常谈的墨菲定律,强调会出错的事总会出错。针对这两个原则,我总结了系统性能问题的五大特性。
1)系统响应慢
不论负载情况如何,系统应用程序一直特别慢,响应时间长。
2)时间序列日益缓慢
负载稳定,但系统随着时间推进越来越慢,到达某个阈值后,系统可能会被锁定或因大量错误出现而崩溃。
3)突发混乱
系统稳定运行,在某一时刻突然出现大量错误。
4)局部功能异常
用户访问部分页面异常,上图右下角图片是用F12对访问谷歌页面进行的截图,从中可以看出,我们访问谷歌时一直超时,无法访问。
5)随负载变化越来越慢
用户量增加时,系统明显变慢,用户离开系统后,系统恢复原状。上图左下角的图片展示了CPU的使用情况,其从100%负载恢复到常态化,后续随着用户增加又逐渐涨至100%负载。
二、系统性能排查方略
1、系统性能排查方略方法论
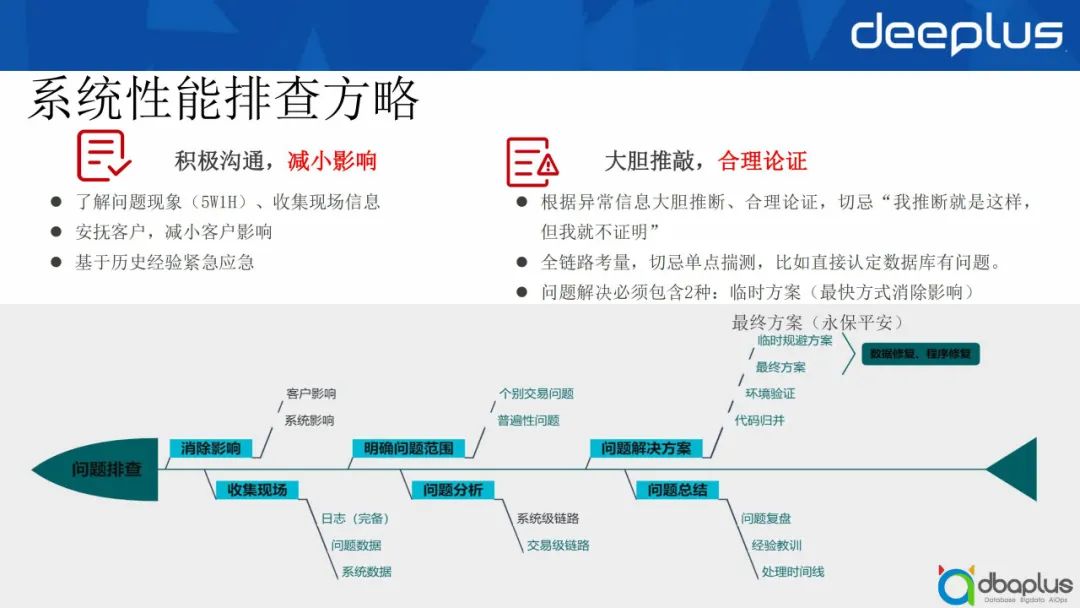
系统性能排查方略可总结为以下两点:
1)积极沟通,减小影响
- 利用5W1H原则了解问题现象,即什么问题、在什么时间、什么地点、如何发生、何人处理。同时还要收集现场信息,包括常见的日志信息、流量信息等,尽量做到全面排查。
- 安抚客户,减小客户影响。一件小事可能会由于客户恐慌性的增长酿成大事故。
- 基于历史经验紧急应急。
2)大胆推敲,合理论证
- 根据异常信息要大胆推断、合理论证,切忌“我推断就是这样,但我就不证明”;
- 进行全链路考量,切忌单点揣测,比如直接认定数据库有问题,但是经分析来看,数据库负载实际上没问题,而是网络问题或中间件问题;
- 问题解决必须包含临时方案和最终方案。用临时方案以最快的方式消除影响,然后针对问题做最终方案,避免后续类似问题带来的隐患。
为此,我通过鱼骨图进一步描述问题的排查方式:
1)消除影响
首先需要消除对客户的影响,其次要消除对系统的影响,可以通过历史经验紧急应急或其他方式帮助客户或系统避开问题。
2)收集现场
这一步强调日志的完备,同时我们需要知道发生问题时的问题数据和系统数据,才可通过数据进行重演。
3)明确问题范围
判断发生的是个别交易问题还是普遍性问题。如果是个别交易问题,我们可以很快定位交易当时做过哪些改变;如果是普遍性问题,我们要判断哪些客户、客流受到影响,以及这一问题是否会对其他方面造成影响。
4)问题分析
问题分析包括两个方面,一方面是系统级链路分析,从最早的端到端的链路进行统一排查;另一方面是交易级链路分析,从交易进来后经过中间件到数据库返回,对整个交易级链路进行分析。
5)问题解决方案
经过之前的一系列步骤,最终我们就可以制定问题的解决方案。在制定解决方案时,一般会进行数据修复和程序修复,在环境中同步验证,并将修改后的部分归并至后续版本中,避免导致类似问题重复发生。
6) 问题总结
这一步主要是针对问题进行复盘,从中发现优化点,并从问题的处理方式中总结经验教训,然后进行一些横向排查,沉淀为相关经验。
下面向大家讲述性能问题排查,其中包括两大方面:系统环境和运行环境。
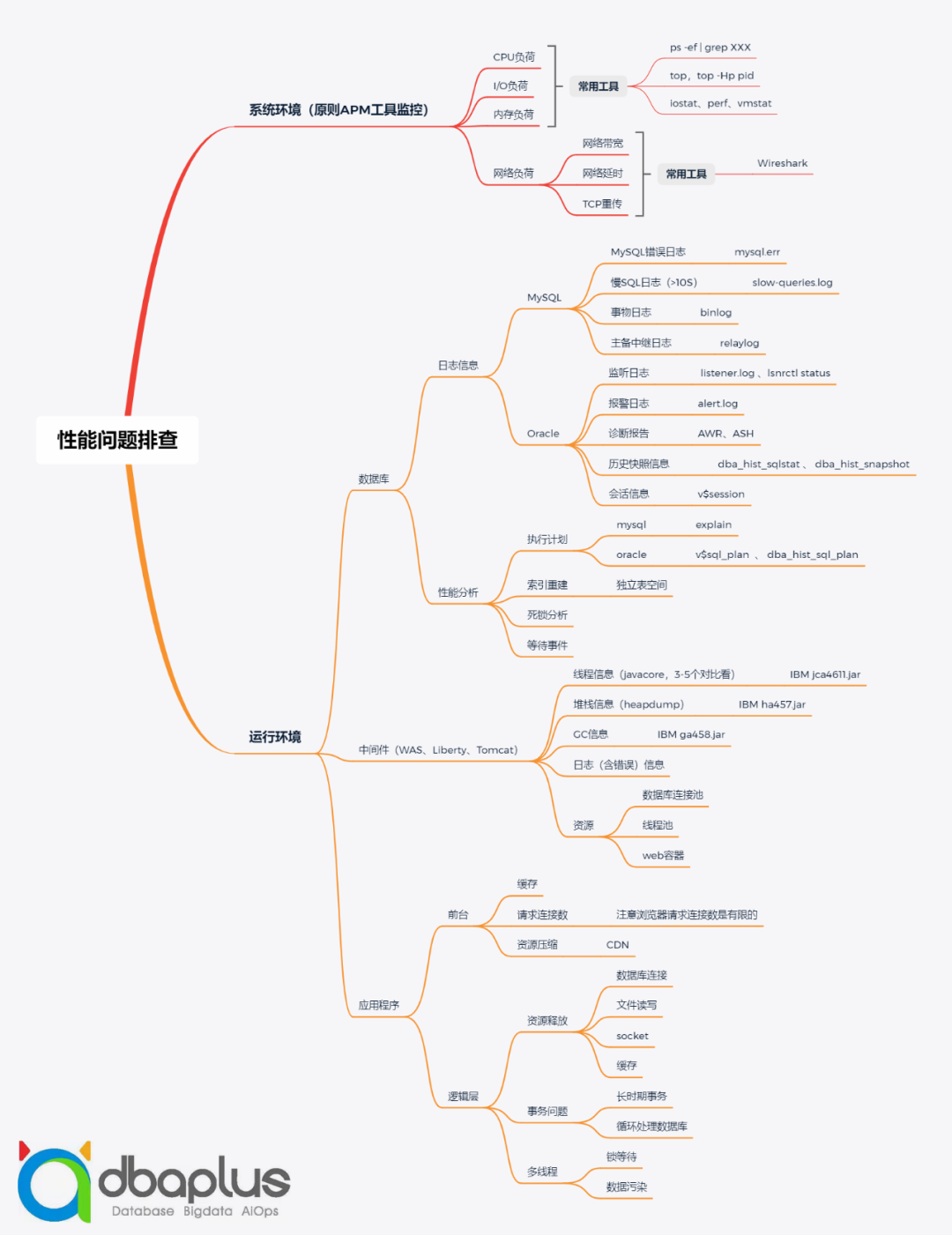
1)系统环境
我们原则上通过APM工具监控系统环境。业界已经有些很好的开源监控工具,比如Prometheus、Zabbix等,可以利用这些工具监测CPU负荷、lO负荷、内存负荷以及网络负荷。
2)运行环境
可以将运行环境的问题大致分为以下三类:
① 数据库
- 日志信息
对于MySQL,首先查看其错误日志,通过mysql.err直接查看当时到底有什么问题;如果交易比较缓慢,可以从慢SQL日志(一般是slow-queries.log)中查看,原则上大于10秒的交易都会在这里体现;接下来看事务日志,通过binlog查看当时交易的情况,如果是备库重演的一些问题,可以看主备中继日志,通过relaylog查看备库重演的状态。
对于Oracle也大体相似,可以通过监听日志listener.log、lsnrctl status查看监听器的状态,Oracle中有一个报警日志,通过alert.log可以查看当时发生的事件。我们还可以进一步打AWR报告和ASH报告,对数据库进行监控,这一点MySQL不如Oracle。除此之外,Oracle也提供了一些历史快照信息表,比如dba_hist_sqlstat和 dba_hist_snapshot,可以通过这两张快照表获取需要的任意快照时间的处理信息。最后,可以通过会话信息,查看当前会话有哪些中间件正在访问,以及整个会话的状态。
- 性能分析
进行性能分析时,我们可以查看执行计划。对于MySQL,我们可以通过explain语句看当时的执行计划,到底有没有走索引,索引走得好不好。对于Oracle,我们可以通过v$sql_plan和dba_hist _sql_plan查看执行计划变更的原因,针对执行计划对索引进行重建。除此之外,我们还要对死锁进行分析,并处理等待事件。
② 中间件
对于中间件,例如业界使用较多的WAS、Liberty、Tomcat以及国产的东方通等,我们可以查看它的一些线程信息。这里建议大家打出3~5个javacore,一般是1分钟打一个,这样可以通过IBM的jca4611.jar工具对比分析问题出于哪个线程,或者线程卡在何种情况之下。
如果涉及到OOM(内存溢出),可以打出heapdump的信息,再通过IBM的ha457.jar工具进行分析。
我们可以通过GC信息看是否因为服务器full gc导致系统持续夯住,如果是,可以对vm信息进行调优。除此之外,中间件还会打一些日志信息,可以从中发现当时发生的问题。最后可以监控一些中间件的资源信息,包括数据库连接池、线程池和一些web容器。
③ 应用程序
若发现数据库和中间件都没有问题,我们再看应用程序。
对于前台来说,我们看是不是因为它在前台做了缓存,没有实时刷新,因此导致新请求获得老交易,最终出现问题。除此之外可以看请求连接数,浏览器的请求连接数实际上是有限的,请求连接数过大也会导致应用程序出问题。最后可以看一下是否因为资源过大导致网络传输量较大,这种问题可以通过两种方式解决,一种是资源压缩,另一种是将资源部署在CDN上。
对于逻辑层来说,我们可以看它有没有资源释放,包括数据库连接、文件读写、socket、缓存等。然后可以看事务问题,比如事务长时间没有结束,这样会卡死很多线程信息,循环处理数据库也会导致事务的持续时间较长。最后可以看多线程信息中是否包含锁等待,是否存在数据污染。
综上所述,系统性能排查有四个关键点:查看完备的日志、利用良好的工具、执行计划和关注逻辑问题。
接下来会对java中间件和数据库性能两部分进行详细分析:
2、java中间件分析
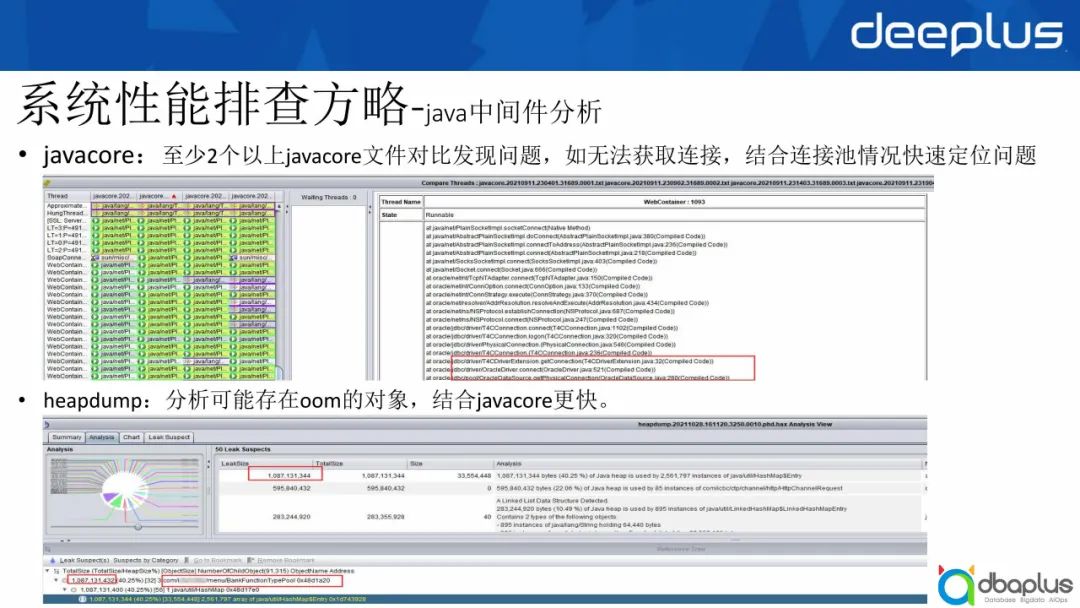
1)通过jca分析javacore
我对比了4个javacore文件,发现大部分问题集中在无法获取连接池,即连接池都已经被占满且长时间没有释放,这时可以结合连接池情况快速定位问题。
2)分析oom对象
对于oom对象,上图可以看出有一个情况是BankFunctionTypePool中,oom大约存了1G空间,换言之,已直接将jvm内存耗尽。这种情况下,一般建议heapdump加上javacore共同做分析,这样可以快速定位问题。
3、数据库相关问题分析
针对数据库方面的问题,有如下分析流程。
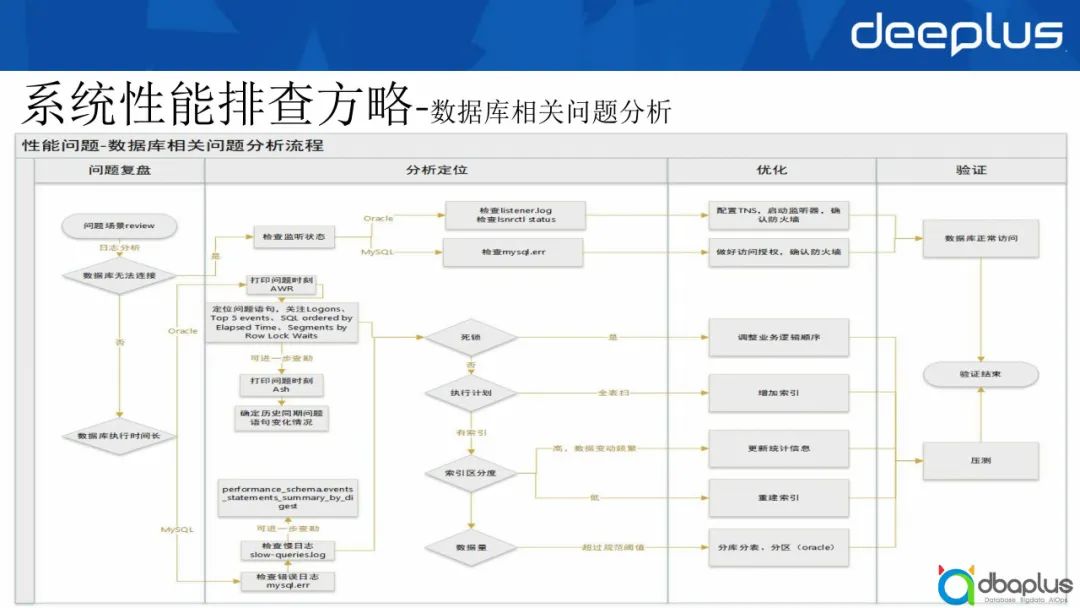
一般出现问题场景后,首先通过日志分析判断是不是数据库无法连接。
如果数据库无法连接,就检查监听状态。如果是Oracle,listener.log并没有状态的日志记录,可以检查lsnrctl status,然后配置TNS,启动监听器,确保数据库正常访问。如果是MySQL,可以检查mysql.err文件,发现其中有一个access denied报错,这种情况下我们做好访问授权并确认防火墙,之后数据库就可以正常访问。
如果数据库可以连接,但是数据库执行时间过长,这种情况下应该按照以下方法解决。
如果是Oracle,可以打印问题时刻的AWR报告,定位问题语句(一般关注Logons、Top 5 events、SQL order by Elapsed time等),然后处理问题。如需进一步查勘,可以打印ASH报告,查看历史同期问题引进的变化情况,从而快速定位一些问题。如果是MySQL,一般检查mysql.err的错误日志,然后检查slow-queries.log,如需进一步查勘,可以把performance_schema.events _statements_summary_by_digest表中的数据提取出来进行进一步查勘。
一般来说,数据库相关问题可分为以下4种:
1)如果有死锁,需要调整业务逻辑顺序,进行压测,然后验证结束。
2)如果没有死锁,只是执行计划有问题,例如出现一个全表扫,则在上面增加合适的索引处理。
3)如果有索引,需要判断它的区分度:如果区分度高并且数据变动频繁,需要更新统计信息;如果区分度低,就决定索引是否合适,如果不合适就重建索引,选择合适的索引进行处理。
4)最后需要看数据量的大小,如果超过了规范的阈值,就要进行分库分表以及分区策略。
我们将逻辑调整后,再进行相关压测,当压测满意时验证结束,真正上生产去做处理。
三、MySQL调优策略
1、索引
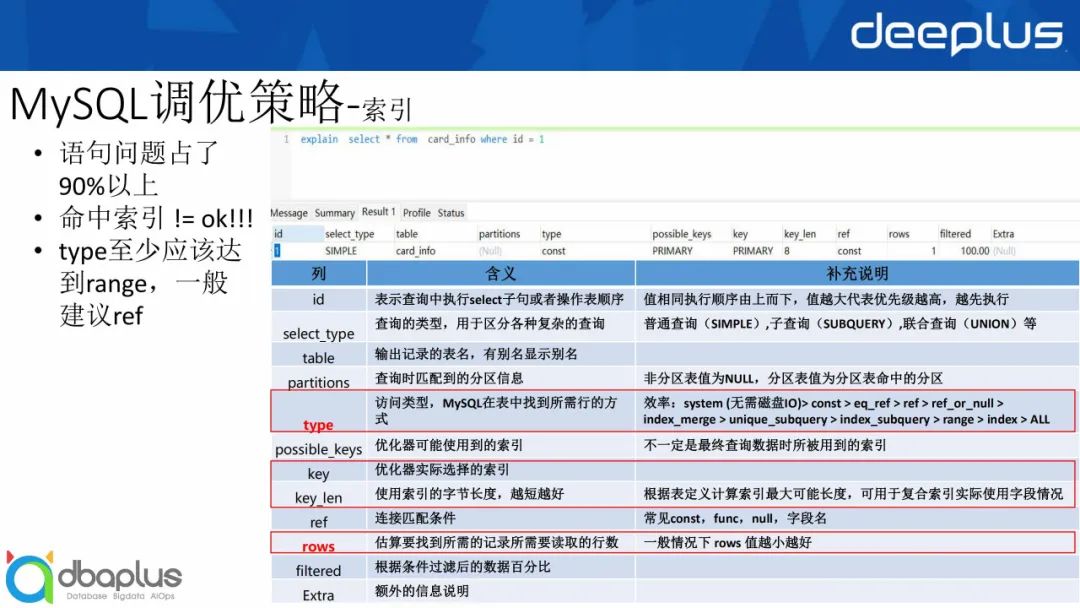
1)一般建议大家查看执行计划,从我目前的分析来看,语句问题占90%以上;
2)命中索引并不等于ok;
3)执行计划最少应该达到范围扫,一般建议达到ref程度。
对于MySQL的执行计划,有 id、select_type、table等列,其中我一般会关注表中的type,它表示访问类型,决定了MySQL在表中找到所需要行的方式。
我在上图右方列出了效率情况:
system (无需磁盘IO)> const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
接下来查看key还有key_len的值,使用索引的字节长度越短越好,可以根据表定义大概计算出索引的最大可能长度,可用于复合索引的实际使用字段情况。
之后查看rows,一般情况下建议rows值越小越好。其他例如filtered和Extra等也是比较关键的信息,这里不再赘述,大家可以参考上图中的表格。
2、分库分表
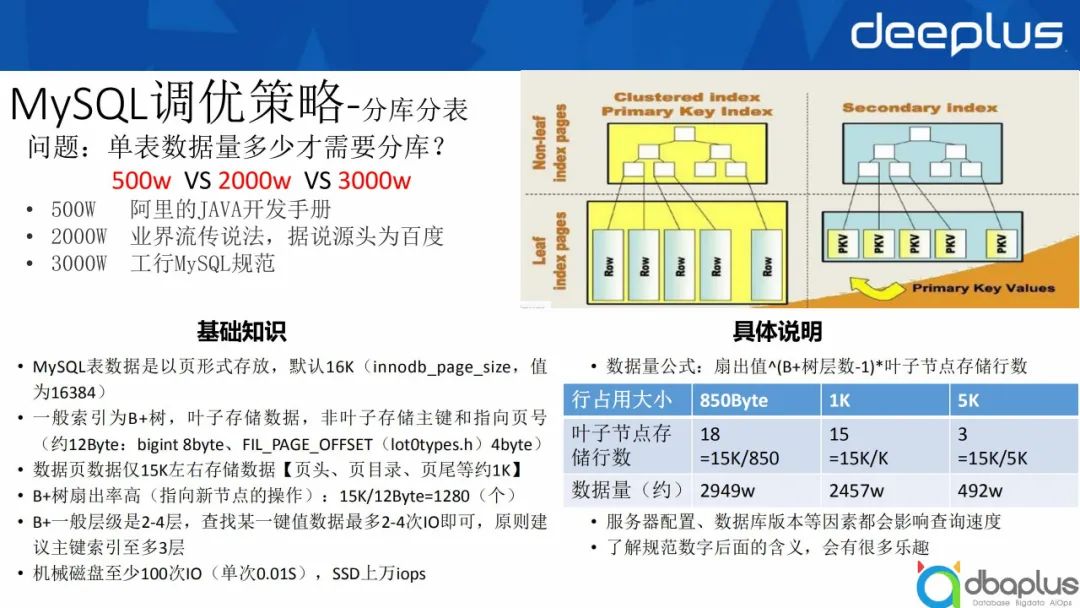
针对分库分表,首先要关注一个问题,单表数据量达到多少才需要进行分库?
阿里手册中写到数据量达到500万进行分库分表。业界的说法是数据量达到2,000万进行分库分表。其源头是百度的一个DBA进行压测后,觉得压到2,000万没问题,但是超过2,000万后性能会出现问题,所以业界流传的数据量界限是2,000万。
对于工行来说,MySQL规范建议数据量达3,000万进行分库分表。
MySQL索引分为两种,一种是聚簇索引,即主键索引,索引和数据保持在一起。另一种是secondary Index,即辅助索引。
下面简单介绍一些基础知识:
- MySQL的表数据是以页形式存放,默认16k,innodb_page_size值是16384,除以1024正好是16k。
- 一般索引为B+树,叶子存储数据,非叶子存储主键和指向页号,一般是12byte,因为使用bigint会占8字节,同时lot0types.h中源代码有一个指针FIL_PAGE_OFFSET,占了4字节,所以非叶子存储大约存储12字节。
- 数据页数据仅有15k左右可以存储数据,因为页头、页目录和页尾也会占1k的空间。
- B+树扇出率较高,15k除以12byte,它每一个节点可以指向1280个叶子。B+树一般的建议层级是2~4层,保证查找某一键值,最多2~4次IO即可。主键索引一般也都在3层左右。
- 这里还涉及到一个iops知识,因为大家之前用机械硬盘,一般进行一次io操作需要0.01秒,而现在大家普遍常见的SSD都是上万的ops,MySQL的访问效率比以前高很多。
针对以上基础知识,作以下具体说明:
数据量=扇出值^(B+树层数-1)*叶子节点存储行数
例如我们行的行占用大小约为850Byte字节,每个叶子节点可以存储18行,数据量为2,900万左右,这也是3,000万的分库分表界限的来源。百度行占用大小是1K,每个叶子节点存储15行数据,数据量为2400万左右,所以业界才有2,000万这一说法。阿里同理,经过计算强调数据量超过500万进行分库分表。
我们要了解规范数字背后的含义,这样很多问题就会迎刃而解。除此之外,服务器配置、数据库版本等因素也会影响查询速度。
3、锁问题

MySQL官方对锁有较详细的介绍,一般常见类型是读锁和写锁。读锁包含两种锁:记录锁和间隙锁。我们工行用READ-COMMITTED规避间隙锁。
大家通过mysql.err看日志表现,可以看到有lock_mode X和locks rec but not gap,这是记录锁的含义。
这里需要关注以下两点:
1)锁竞争
5.7版本中我们从locks、locks_waits表查看锁,但是8.0版本从infomation_spchema迁至performance_schema。下面举一个例子进行说明。
事务1是start transaction,更新同一个id=1的值,事务也对它进行更新,50秒后,它会抛一个1205错误,直接显示锁等待超时。我们建议一个锁等待超时的时间是5~10秒,从而避免对事务造成较大影响。
2)死锁检测
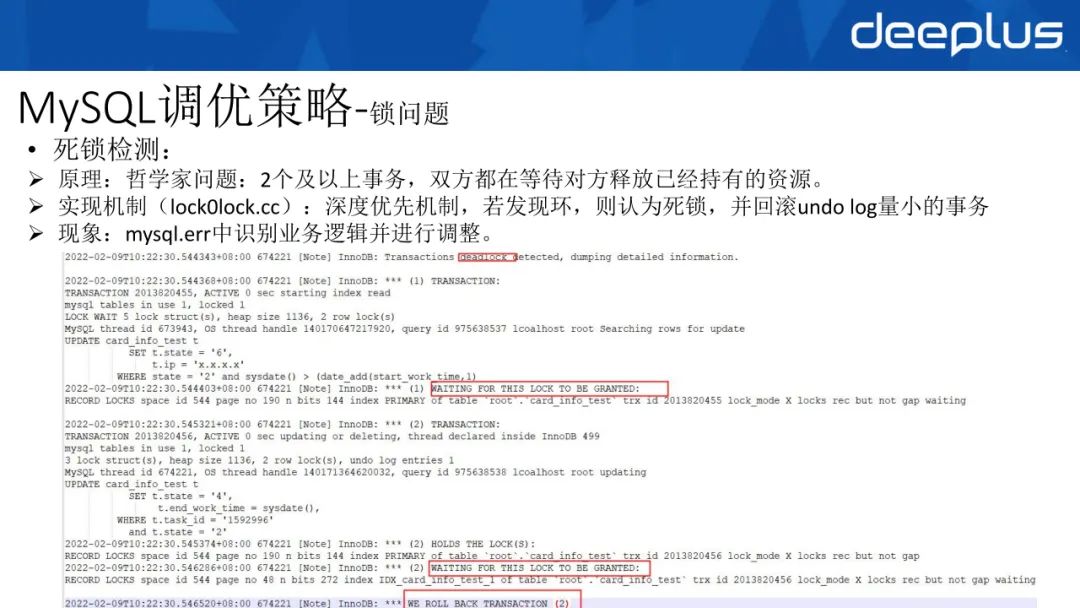
死锁检测本质是哲学家的问题:2个及以上事务,双方都在等待对方释放已经持有的资源,最后造成等待循环,形成死锁。
针对MySQL实现机制,大家看lock0lock.cc,它本质是进行深度优先机制,如果发现环,则认为是一个死锁,同时回滚undo log量小的事务。
如果大家查看mysql.err,可以发现它第一步有一个deadlock detected,然后事务1会等待另外一个记录锁去释放,事务2也会等待事务1的记录锁去释放,最后因为事务2回滚量较小,所以回滚了事务2。
4、Google Trends & DB-Engines
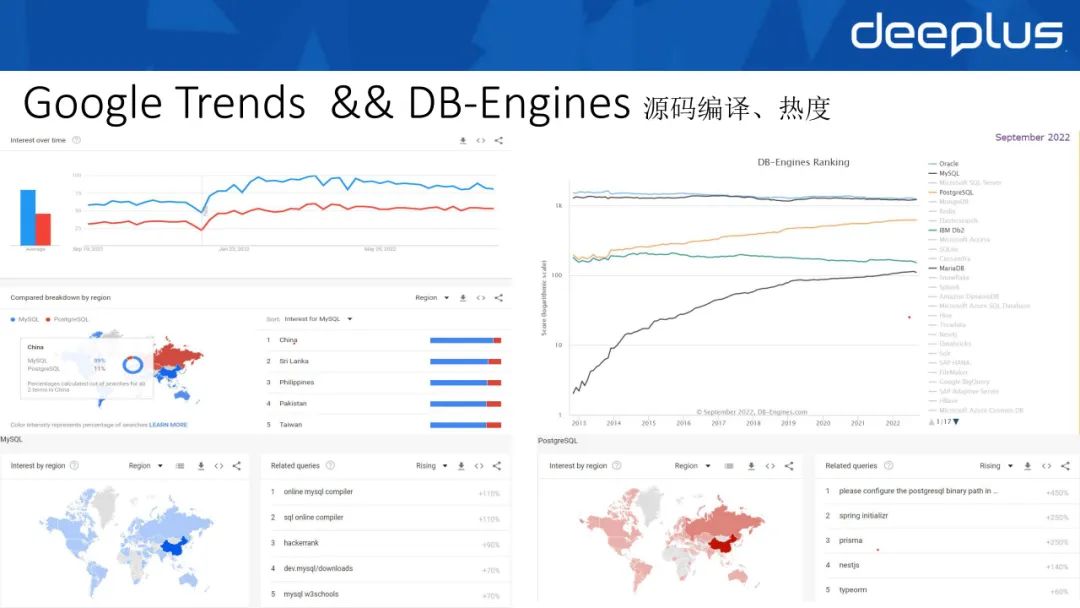
MySQL和PostgreSQL这两个数据库都很好,但是对于我们国家来说,在Google Trends上MySQL的热度更高一点,占比大概是89%,PostgreSQL占比是11%左右。我们搜索关键字时,最多的是怎么编译MySQL,这说明我国对源码的掌握和编译有较为热切的需求。从DB-Engines Rank中可以看到MySQL和Oracle一直不相上下,PostgreSQL的热度也在逐步上升。
四、MySQL性能管控体系
接下来分享我们行的性能管控体系。
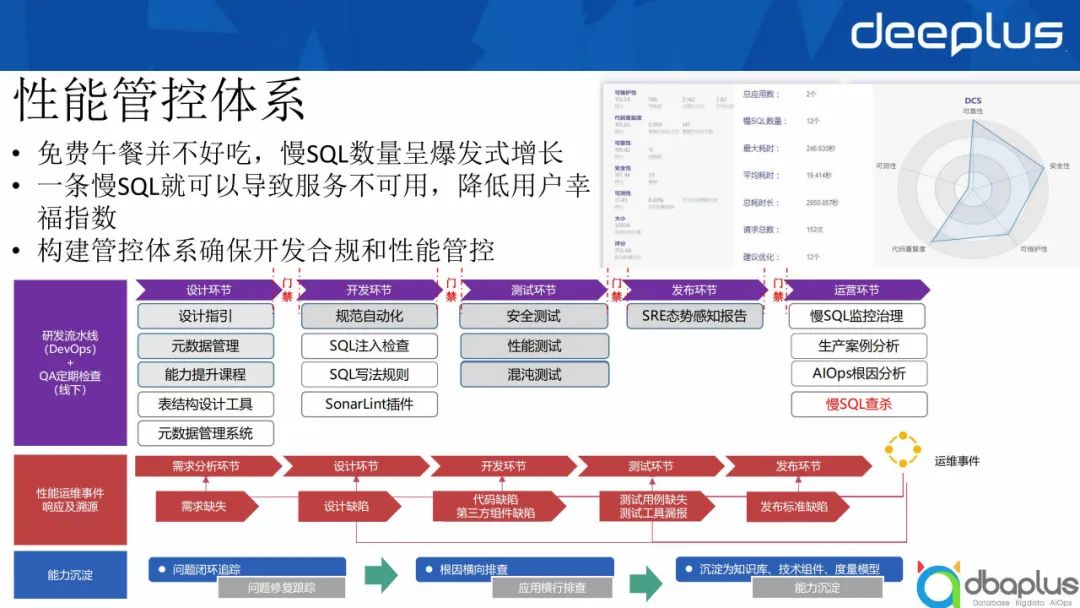
“免费的午餐并不好吃”,随着MySQL的广泛应用,大家并不注意开发规范,这会导致慢SQL数量呈爆发式增长。一条慢SQL就可以导致服务不可用,降低用户幸福指数。我们为此构建管控体系确保开发合规和性能管控。
1、性能管控体系
1)研发流水线 (DevOps) + QA定期检查 (线下)
首先我们通过研发流水线(DevOos)和QA定期检查对整个研发环节进行处理。具体可分为以下环节:
- 设计环节
在设计环节,我们建立了设计指引,做了一些元数据管理,并设置了能力提升课程提升大家的数据库使用能力。我们也会推动一些表结构设计工具和元数据管理系统,限定大家局面处理问题,同时我们在这一环节设置了门禁。
- 开发环节
这一环节我们将一些规范做到自动化,包括SQL注入检查和SQL写法的规则。SonarQube有SonarLint插件可以做服务器端的同步,这也有利于在开发环节做性能管控。
- 测试环节
这一环节我们通过安全测试、性能测试和混沌测试进行性能管控。
- 发布环节
发布环节会由我们的SRE发布一些态势感知报告,从技术以及安全等层面对业务提出针对性建议及后续整改措施。
- 运营环节
在这一环节我们首先会进行慢SQL的监控治理,逐步减少大事务数据;大家可以看到上图某部门有2个应用,慢SQL数量12个,最大耗时246秒,平均耗时11.414秒。
其次,我们会进行生产案例分析,将相关规则沉淀到知识库,并将技术组件放入技术模型。除此之外,我们还会做一些AIOps根因分析。
最后我们会进行一些慢SQL的监控和查杀,将大事务提前扼杀,避免其对系统产生影响。
2)性能运维事件响应及溯源
我们会针对每一个问题反省并溯源,看到底是哪一环节出现问题,哪些环节可以进行优化。例如判断:语句是否因为没有限定时间范围的存在需求缺失情况?设计功能是否考虑到大表关联这种设计缺陷?开发环节是否存在代码缺陷?
检查开发环节后我们会检查测试环节是否有测试用例缺失、测试工具漏报等缺陷,最后检查发布环节是否有发布标准等缺陷。
3)能力沉淀
最后我们会进行能力沉淀,例如问题闭环追踪、根因横向排查,最后沉淀为知识库、技术组件、度量模型。
2、MySQL开发规范
1)设计原则

在设计方面,我们有以下三大原则:
① 复用原则
在系统架构时,应考虑将相同或类似作用的信息使用同一套数据结构来存储。例如:通用参数表、通用字典表。
② 前瞻性原则
设计应基于完整的产品定义和业务要素,而非当前具体功能需求设计表结构;
设计应基于完整的生命周期和业务流程设计表结构。如:事件类表,可以适当增加种类、状态字段以便后续扩展。
③ 元数据原则
列名应遵循统一的数据标准,即同一类型字段应对应同一个元数据;字段类型和长度应相同,如同一产品线下所有表的机构编号应该对应同一个元数据;
常用的字段应建立应用级的标准定义,指明元数据,确定字段命名。如所有表 的“最新维护时间”字段都统一命名为last_modify_time,这样能够确保我们后续在数据库挖掘以及做知识图谱时,可以将整个链路串起来。
2)典型规范示例

① 操作:方法论
方法论是万物之基石,例如每个表我们必须要建立一个主键,如果不显示设置主键,会自动生成一个rowid(6 byte)作为隐藏主键,且所有表共用此空间,造成性能下降。
② 量化:精细化的理性思维
我们建议扫描命中比原则上应该是100:1,事物大小方面我们行的要求是10万,业界一般一万即可。
③ 避坑:规避 MySQL Bug
大表truncate改为drop + create table,这在5.7中效果非常明显,但是在8.0中公司已经对其进行了修改优化。
针对以上规范,我们要让开发人员潜移默化地知其然也知其所以然,避免出现一些问题。
3、质量门禁自动化
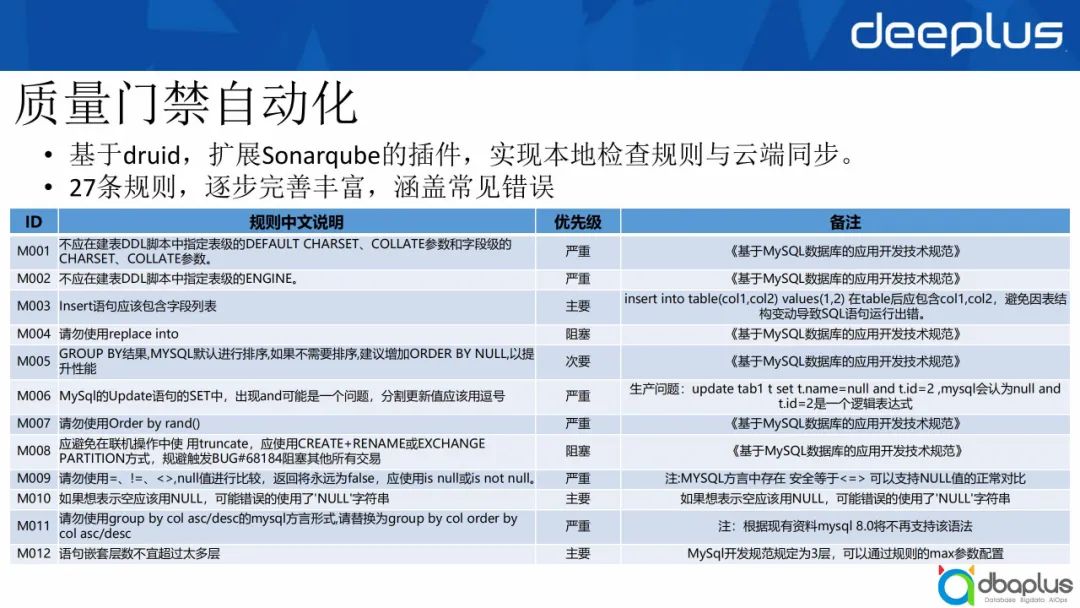
我们基于druid,扩展了Sonarqube插件,实现本地检查规则和云端云同步。
我们之前大概定了27条规则,其中包含了常见的一些错误,例如有人在update语句的set关键字后面,误将分隔符逗号(“,”)写成“and”,导致出现预期之外的结果。
4、大事务查杀

大事务的相关问题主要有以下几点:
- binlog的写入、传输、回放缓慢问题。之前我曾看到一个应用,备库24小时都未完成回放,万一主库出问题,都没办法回切,只能等备库处理完后再回切;
- 交易写入堵塞;
- 在主库故障博弈的情况下,到底切还是不切?
- 我们行以及业界都采用了自动查杀方式。
- 在show engine innodb status中,我们可以进行监控,如果一个事物没有结束,会提示这个事务更新的记录数;
- 超过什么样的阈值时,我们可以进行自动kill。对于联机以及批量来说,阈值是不一样的,所以我们自动执行kill时,必须规避一刀切的问题。
我们当时做过两步操作,第一步是将交易的联机库跟批量库进行区分。对于联机库,超过三秒以上的交易可以进行自动查杀;对于批量库,通过小范围试点,然后做到全面推广。
后续我们应该会将MySQL的主动同步做到不降级,去掉降级时间,但这一点依赖于我们治理完善、大事务不存在的情况。
五、未来展望
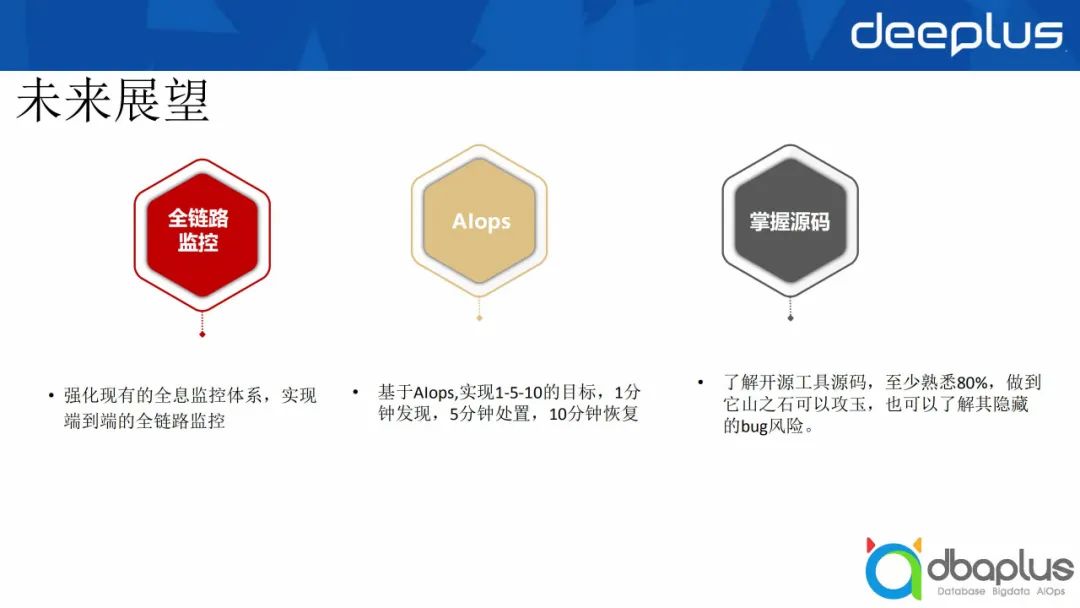
1、全链路监控
希望可以做到全套端到端的全链路监控,这样可以快速定位哪个节点出了什么问题。
2、进一步发展AIOps
希望进一步发展AIOps,实现业界所说的1-5-10目标,1分钟发现,5分钟处置,10分钟恢复。
3、掌握源码
最后希望各位可以掌握一些开源组件的源码,做到“他山之石,可以攻玉”,了解其中隐藏的bug风险,有利于我们后续对开源组件进行维护。
Q&A
Q1:贵司在MySQL调优过程中,会用到相关辅助工具吗?老师能简单分享一下吗?
A1:没有用到辅助工具,我们更多还是通过explain直接查看执行计划,然后进行一些分析。
Q2:MySQL规范已经在贵司普及了吗?落地一整套规范需要多长时间?
A2:我们大概从17年开始建立MySQL规范,因为我们当时引入MySQL5.7时,必须建立方法论这套基石。我们建立规范后,在SonarQube上建立检查组件,进而做到门禁,实现规范的落地。在只有规范,没有落地的情况下,我们很难把控,所以必须要通过硬性方式进行把控。
Q3:贵司是采用什么方式对MySQL进行监控的?
A3:包括两种层面,第一层面,我们在MyBatis上做了扩展,会对语句进行审核,判断语句是否有问题。第二层面,对MySQL的performance schema 和Information schema相关表进行监控,查找并处理其中的慢SQL。
Q4:老师,自动查杀的准确率能达到多高?
A4:自动查杀的准确率其实可以达到100%。大事务很容易就可以监控出来,但很多时候不敢查杀,我们把联机跟批量分离完以后,对联机大事务查杀的准确率就相当于是100%了。
Q5:老师能推荐个好用的开发工具吗?比如Workbench?这块总行有要求吗?
A5:业界其实有很多工具,例如收费的Navicat、免费的MySQL Workbench等,我一般会用Workbench多一点,因为我们行引入软件受到管控,必须要进行登记处理。
作者介绍:
魏亚东 :工商银行软件开发中心三级经理,资深架构师,杭州研发部数据库专家团队牵头人和开发中心安全团队成员,负责技术管理、数据库、安全相关工作;
2009年加入中国工商银行软件开发中心,致力于推动管理创新、效能提升,提供全面技术管控,推动自动化实施,实现业务价值的高质量快速交付;同时作为技术专家,为生产安全提供技术支持;负责过教培、预付费等SaaS产品和数字生态基座(组装式应用程序Composable Applications)等。
原文地址:https://mp.weixin.qq.com/s/vNomB2yHj8ung8qvLMIRoQ
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









