
防止MySQL重复插入数据的三种方法

新建表格
?| 1 2 3 4 5 6 7 | create table `person` ( `id` int not null comment '主键' , ` name ` varchar (64) character set utf8 collate utf8_bin null default null comment '姓名' , `age` int null default null comment '年龄' , `address` varchar (512) character set utf8 collate utf8_bin null default null comment '地址' , primary key (`id`) using btree ) engine = innodb character set = utf8 collate = utf8_bin row_format = dynamic ; |
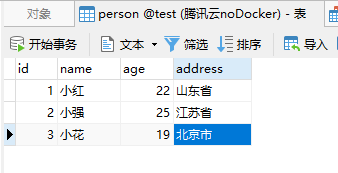
添加三条数据如下:
我们这边可以根据插入方式进行规避:
1. insert ignore
insert ignore 会自动忽略数据库已经存在的数据(根据主键或者唯一索引判断),如果没有数据就插入数据,如果有数据就跳过插入这条数据。
?| 1 2 | --插入sql如下: insert ignore into person (id, name ,age,address) values (3, '那谁' ,23, '甘肃省' ),(4, '我的天' ,25, '浙江省' ); |
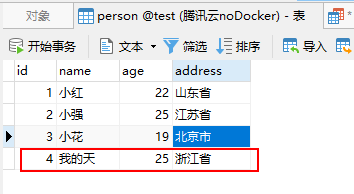
再次查看数据库就会发现仅插入id为4的数据,由于数据库中存在id为3的数据所以被忽略。
2. replace into
replace into 首先尝试插入数据到表中, 1. 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。 2. 否则,直接插入新数据。
?| 1 2 | --插入sql如下: replace into person (id, name ,age,address) values (3, '那谁' ,23, '甘肃省' ),(4, '我的天' ,25, '浙江省' ); |
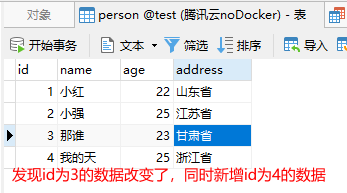
首先我们将表中数据恢复,然后进行插入操作后发现id为3的数据发生了改变同时新增了id为4的数据。
3. insert on duplicate key update
insert on duplicate key update 如果在insert into语句的末尾指定了on duplicate key update + 字段更新,则会在出现重复数据(根据主键或者唯一索引判断)的时候按照后面字段更新的描述对该信息进行更新操作。
?| 1 2 | --插入sql如下: insert into person (id, name ,age,address) values (3, '那谁' ,23, '甘肃省' ) on duplicate key update name = '那谁' , age=23, address= '甘肃省' ; |
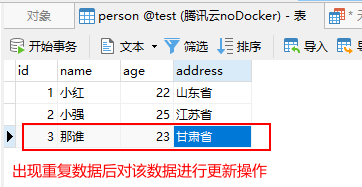
首先我们将表中数据恢复,然后在进行插入操作时,发现id为3的数据发生了改变,进行了更新操作。
我们可以根据自己的业务需求进行方法的选择。
以上就是防止mysql重复插入数据的三种方法的详细内容,更多关于防止mysql重复插入数据的资料请关注服务器之家其它相关文章!
原文链接:http://www.zhouzhaodong.xyz/archives/mysql%E6%8F%92%E5%85%A5%E6%96%B9%E6%B3%95?utm_source=tuicool&utm_medium=referral
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








