
MySql索引提高查询速度常用方法代码示例

1.前言
在web开发中,业务模版,业务逻辑(包括缓存、连接池)和数据库这三个部分,数据库在其中负责执行sql查询并返回查询结果,是影响网站速度最重要的性能瓶颈。本文主要针对mysql数据库,在淘宝的去ioe(i 代表ibm的缩写,即去ibm的存储设备和小型机;o是代表oracle的缩写,去oracle数据库,采用mysql和hadoop代替;e是代表emc2,去emc2的设备性,用pc server代替emc2),大量使用mysql集群!而优化数据的重要一步就是索引的建立,对于mysql出现的慢查询,可以用索引提升查询速度。索引用于快速找出在某个列中有一特定值的行,不使用索引,mysql将全表扫描,从第一条记录开始,然后读完整个表直到找出相关的行。
2.mysql索引类型及创建
索引相关知识:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | pri主键约束; uni唯一约束; mul可以重复。 查看索引 mysql> show index from tblname; mysql> show keys from tblname; · table 表的名称。 · non_unique 如果索引不能包括重复词,则为0。如果可以,则为1。 · key_name 索引的名称。 · seq_in_index 索引中的列序列号,从1开始。 · column_name 列名称。 · collation 列以什么方式存储在索引中。在mysql中,有值‘a'(升序)或 null (无分类)。 · cardinality 索引中唯一值的数目的估计值。通过运行analyze table 或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,mysql使用该索引的机 会就越大。 · sub_part 如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为 null 。 · packed 指示关键字如何被压缩。如果没有被压缩,则为 null 。 · null 如果列含有 null ,则含有yes。如果没有,则该列含有 no 。 · index_type 用过的索引方法(btree, fulltext, hash, rtree)。 · comment |
1).主键索引
它是一种特殊的唯一索引,不允许为空。一般建表时同时创建主键索引:
?| 1 2 3 4 5 6 | create table user ( id int unsigned not null auto_increment, name varchar (50) not null , email varchar (40) not null , primary key (id) ); |
2).普通索引
这是最基本的索引,没有任何限制:
?| 1 2 3 | create index idx_email on user ( email(20) ); create index idx_name on user ( name (20)); |
mysql 支持索引前缀,一般姓名不超过20字符,所以建立索引限定20长度,节省索引文件大小
3).唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,列值的组合必须唯一。
?| 1 2 3 | create unique index idx_email on user ( email ); |
4).组合索引
?| 1 2 3 4 5 6 | create table sb_man( id int primary key auto_increment, new_name char (30) not null , old_name char (30) not null , index name (new_name,old_name) );# name 索引是一个对new_name和old_name的索引。查询方法: select * from sb_man where new_name= 'yu' ; select * from sb_man where new_name= 'yu' and old_name= 'yu1' ;提示:>>>>>> 组合索引是最左前缀创建, 所以不能用如下sqlselect * from sb_man where old_name= 'yu1' ; <<<< 错误 |
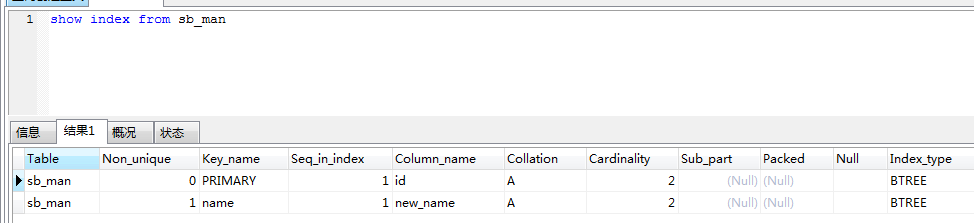
3.什么时候用索引
1.索引引用
在索引列上,除了上面提到的有序查找之外,数据库利用各种各样的快速定位技术,能够大大提高查询效率。特别是当数据量非常大,查询涉及多个表时,使用索引往往能使查询速度加快成千上万倍。
例如,有2个未索引的表t1、t2、分别只包含列c1、c2 每个表分别含有1000行数据组成,值为111的数值,然后设置三张表,不同的几个值,
(这里我是用pymysql 执行 while 创建的数据)
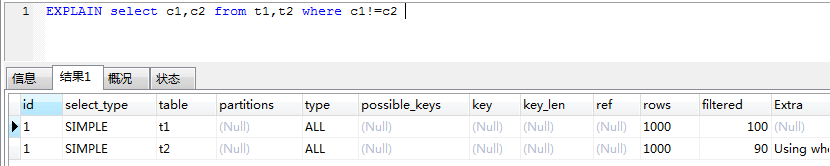
查找对应值相等行的查询如下所示。
在无索引的情况下处理此查询,必须寻找3个表所有的组合,以便得出与where子句相配的那些行。
select c1,c2 from t1,t2 where c1!=c2
结果 查询过程>>
查询过程>>
2.创建索引
在执行create table语句时可以创建索引,也可以单独用create index或alter table来为表增加索引。
1.alter table
alter table用来创建普通索引、unique索引或primary key索引
删除索引: alter table tab_name drop {index|key} index_name;
alter table t1 drop index idx_c1;
添加索引: alter table t1 add index idx_c1(c1);
alter table t2 add index idx_c2(c2);
查询结果 虽然感觉没什么卵用。。。但是索引查询就是如此了。。。
虽然感觉没什么卵用。。。但是索引查询就是如此了。。。

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持服务器之家。
原文链接:https://www.cnblogs.com/pyyu/p/7265406.html
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








