
详解MySQL实时同步到Oracle解决方案

1 需求概述
将mysql5.6生产库多张表的数据实时同步到oracle11g数据仓库,mysql历史数据700g,平均每天产生50g左右日志文件,mysql日志空间50g,超过后滚动删除日志文件。整个同步过程不可影响mysql业务操作。
2 技术原理
采用灵蜂数据集成软件beedi将mysql数据实时同步到oracle,通过etl全量同步历史数据,通过日志解析方式实时同步增量数据。
受限于日志空间,如果将所有历史数据一次性同步,需要的时间会超过一天,全量同步过程产生的日志会被删除,造成实时日志解析任务数据缺失,所以需要分批同步历史数据,基本操作如下:
a 全量同步部分表。
b 在实时日志解析任务中添加已全量同步完成的表并启动任务,当mysql和oracle两端对应表数据一致时,停止日志解析任务。
重复上面a和b步骤,直到所有表都加入实时日志解析任务。
3 mysql环境配置
3.1 创建用户
在主库创建同步用户,以用户sync为例,创建用户及权限分配语句如下:
3.2 启用binlog
查询主库日志开启状态及日志记录格式:
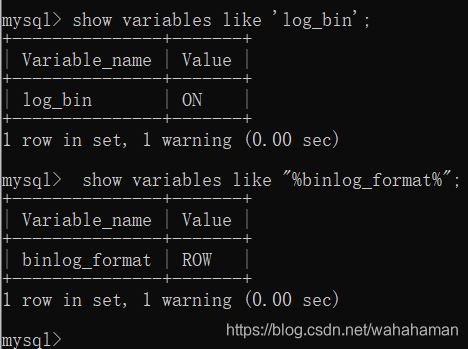
如果日志状态为off或日志记录格式不为row,则编辑my.ini文件,设置以下项目内容:
log-bin="xxxxxx" --开启日志
binlog_format="row" --日志记录格式
4 beedi同步操作
4.1 配置全量同步任务
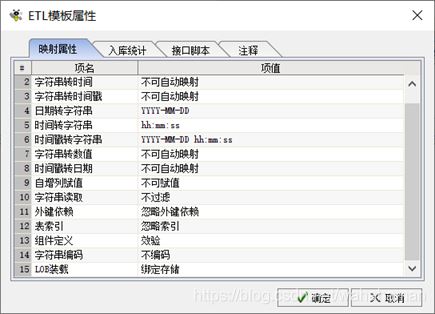
在beedi中新建etl作业,在【etl模板属性】对话框的【映射属性】中设置【lob装载】为绑定存储。
【lob装载】用于指定oracle lob数据载入方式,定位存储通过定位lob指针更新lob内容,绑定存储通过参数绑定方式更新lob内容。
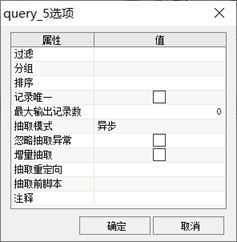
为优化数据抽取性能,建议在抽取组件的【选项】对话框中设置【异步】抽取模式。
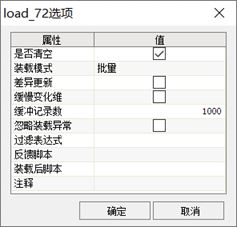
为优化数据加载性能,建议在装载组件的【选项】对话框中选择【批量】装载模式。
全量同步任务配置完成如下
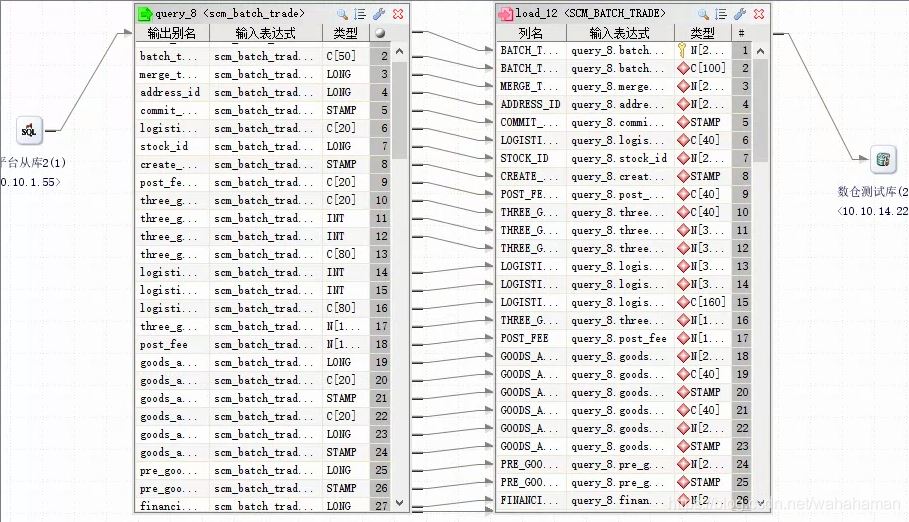
按照以上方式,创建多个etl作业,其中每个etl作业对应一张同步表。
4.2 配置实时日志解析任务
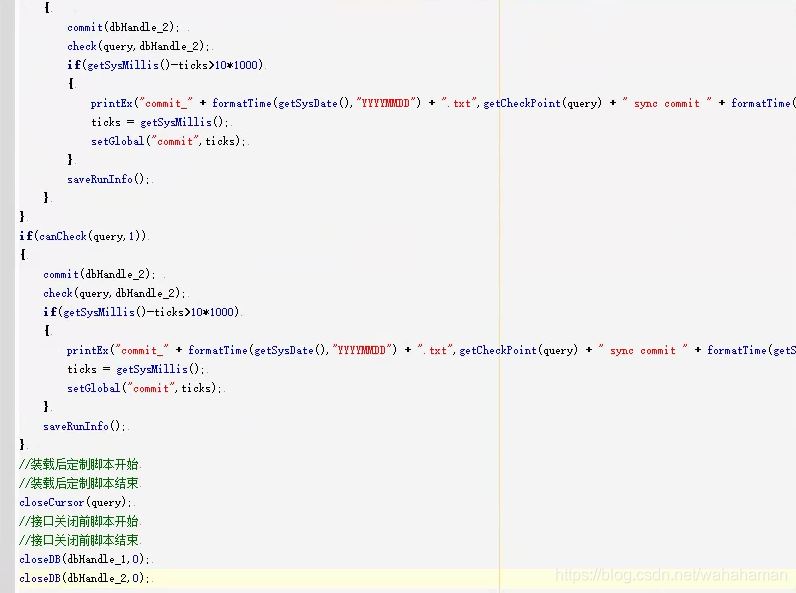
实时解析任务使用一个脚本作业,在其中指定所有要同步的表,脚本代码如下
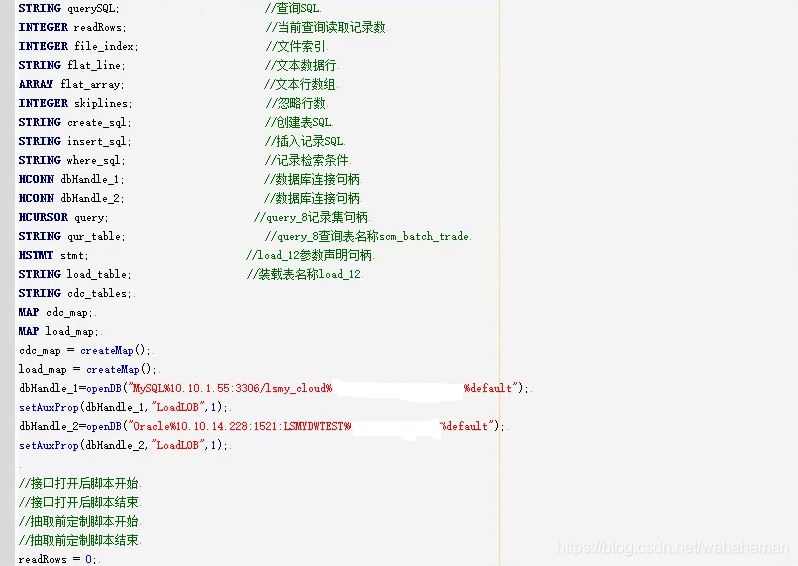
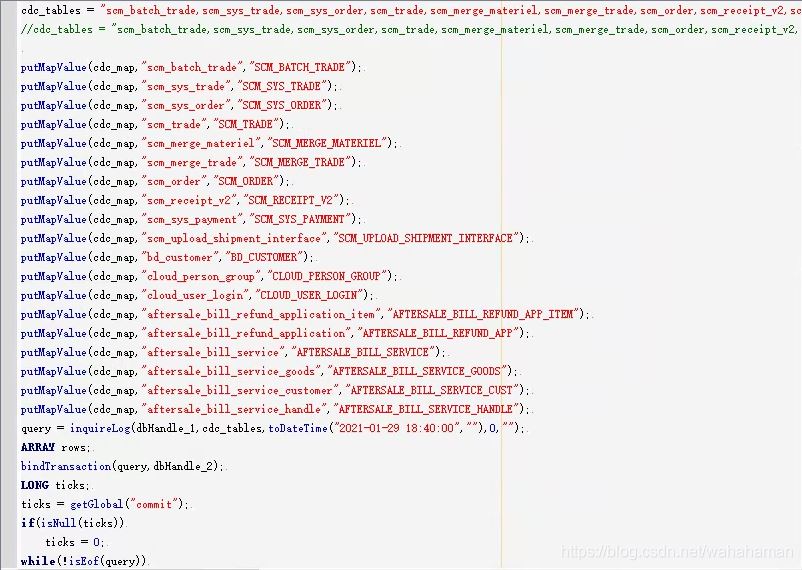
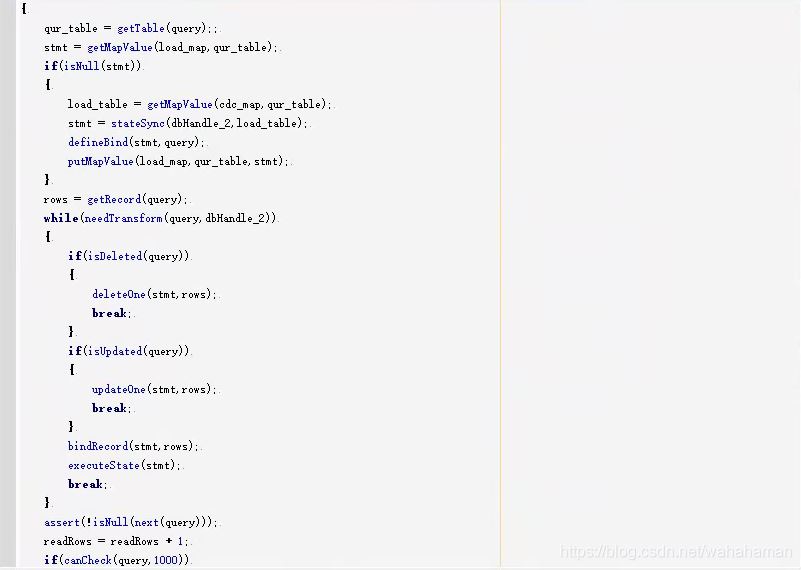
4.3 执行全量同步任务
选中要执行的全量同步作业,点击工具栏【启动】按钮,可以同时启动多个全量同步作业,只要生产库资源及beedi所在机器资源充足。
4.4 执行实时日志解析任务
当所有全量同步作业运行结束后,编辑实时任务脚本,在变量cdc_tables中指定已经全量同步完成的表;在inquirelog函数参数中设置日志捕获起始点,可将最先运行的全量同步作业的启动时间指定为日志捕获起始点,日志捕获点只需在任务初次执行时设置一次,以后任务运行将自动管理日志捕获点。
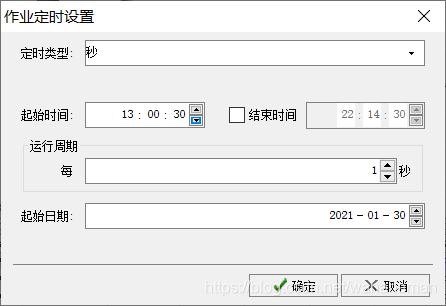
在【调度窗口】通过快捷菜单【添加】把将要执行的实时日志解析作业载入,选中调度窗口的实时作业,点击工具栏【定时】按钮,设置按秒定时,运行周期1秒。
实时任务运行后,在日志窗口输出mysql数据库日志解析信息,包含每分钟读取的日志记录,最近解析日志时间点。

4.5 添加更多同步表
当实时任务对应的作业状态频繁出现定时图标时,表明任务进入实时状态,此时mysql源表和oracle目标表数据一致,停止实时日志解析任务,配置运行其它表的全量同步任务(参考4.1和4.3)。当全量任务结束后,编辑实时日志解析任务,增加已全量同步完成的其他表,启动实时任务(参考4.2和4.4)。
5 效验同步数据一致性
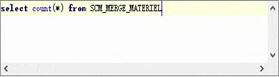
依次在源库和目标库执行 select count(*) from [表] 比较表记录数是否相等。
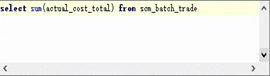
依次在源库和目标库执行 select sum([数值列]) from [表] 比较指定字段算术和是否相等。
到此这篇关于详解mysql实时同步到oracle解决方案的文章就介绍到这了,更多相关mysql实时同步到oracle内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.csdn.net/wahahaman/article/details/113821037
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









