linux中grep命令使用实战详解

一. grep命令介绍
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。
grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
英文注解:
grep ['grep] 搜索目标行命令· global [ˈgloʊbl] 全球的,球状的 regular 美 [ˈrɛɡjəlɚ] 有规律的,规则的, 正规军(n) expression 美 [ɪkˈsprɛʃən] 表达,表现,表情,脸色,态度
例句: It's enough to make you wet yourself, if you'll pardon the expression
linux支持三种形式的grep命令: grep , egrep ,grep -E
二. 语法格式及常用选项
依据惯例,我们还是先查看帮助,使用grep --help
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | [root@mufeng test ] # grep --help 用法: grep [选项]... PATTERN [FILE]... 在每个 FILE 或是标准输入中查找 PATTERN。 默认的 PATTERN 是一个基本正则表达式(缩写为 BRE)。 例如: grep -i 'hello world' menu.h main.c 正则表达式选择与解释: -E, --extended-regexp PATTERN 是一个可扩展的正则表达式(缩写为 ERE) -F, --fixed-strings PATTERN 是一组由断行符分隔的定长字符串。 -G, --basic-regexp PATTERN 是一个基本正则表达式(缩写为 BRE) -P, --perl-regexp PATTERN 是一个 Perl 正则表达式 -e, --regexp=PATTERN 用 PATTERN 来进行匹配操作 -f, -- file =FILE 从 FILE 中取得 PATTERN -i, --ignore- case 忽略大小写 -w, --word-regexp 强制 PATTERN 仅完全匹配字词 -x, --line-regexp 强制 PATTERN 仅完全匹配一行 -z, --null-data 一个 0 字节的数据行,但不是空行 Miscellaneous: -s, --no-messages suppress error messages - v , --invert-match select non-matching lines -V, --version display version information and exit --help display this help text and exit 输出控制: -m, --max-count=NUM NUM 次匹配后停止 -b, --byte-offset 输出的同时打印字节偏移 -n, --line-number 输出的同时打印行号 --line-buffered 每行输出清空 -H, --with-filename 为每一匹配项打印文件名 -h, --no-filename 输出时不显示文件名前缀 --label=LABEL 将LABEL 作为标准输入文件名前缀 -o, --only-matching show only the part of a line matching PATTERN -q, --quiet, --silent suppress all normal output --binary-files=TYPE assume that binary files are TYPE; TYPE is 'binary' , 'text' , or 'without-match' -a, --text equivalent to --binary-files=text -I equivalent to --binary-files=without-match -d, --directories=ACTION how to handle directories; ACTION is 'read' , 'recurse' , or 'skip' -D, --devices=ACTION how to handle devices, FIFOs and sockets; ACTION is 'read' or 'skip' -r, --recursive like --directories=recurse -R, --dereference-recursive likewise, but follow all symlinks --include=FILE_PATTERN search only files that match FILE_PATTERN --exclude=FILE_PATTERN skip files and directories matching FILE_PATTERN --exclude-from=FILE skip files matching any file pattern from FILE --exclude- dir =PATTERN directories that match PATTERN will be skipped. -L, --files-without-match print only names of FILEs containing no match -l, --files-with-matches print only names of FILEs containing matches -c, --count print only a count of matching lines per FILE -T, --initial-tab make tabs line up ( if needed) -Z, --null print 0 byte after FILE name 文件控制: -B, --before-context=NUM 打印以文本起始的NUM 行 -A, --after-context=NUM 打印以文本结尾的NUM 行 -C, --context=NUM 打印输出文本NUM 行 -NUM same as --context=NUM --group-separator=SEP use SEP as a group separator --no-group-separator use empty string as a group separator --color[=WHEN], --colour[=WHEN] use markers to highlight the matching strings; WHEN is 'always' , 'never' , or 'auto' -U, --binary do not strip CR characters at EOL (MSDOS /Windows ) -u, --unix-byte-offsets report offsets as if CRs were not there (MSDOS /Windows ) |
为了更直观一些,我们把常用的参数用表格来展示:
| 参数 | 描述 |
|---|---|
| -i | 忽略大小写 |
| -E | 启用POSTIX扩展正则表达式 |
| -P | 启用perl正则 |
| -o | 只输出正则表达式的匹配的内容 |
| -w | 整字匹配 |
| -v | 取反,也就是不匹配的 |
| -n | 输出行号 |
有了具体的参数之后,我们再来看实战案例:
三. 参考案例
3.1 搜索文件中以root开头的文件
以root开头的文件,可以用 ^root 比如查看/etc/passwd 中以root开头的文件,操作如下:
?| 1 2 | [root@mufenggrow ~] # grep ^root /etc/passwd root:x:0:0:root: /root : /bin/bash |
3.2 搜索文件中出现的root
搜某个单词,我们直接在grep后面跟上单词名字即可:
案例一: 搜索/etc/passwd中的root用户
?| 1 2 3 4 | [root@mufenggrow ~] # grep "root" /etc/passwd root:x:0:0:root: /root : /bin/bash operator:x:11:0:operator: /root : /sbin/nologin [root@mufenggrow ~] # |
案例二: 从多个文件中搜索root
?| 1 2 3 4 5 6 7 8 | root@mufenggrow ~] # echo root >> a.txt [root@mufenggrow ~] # echo root >> b.txt [root@mufenggrow ~] # grep "root" /etc/passwd a.txt b.txt /etc/passwd :root:x:0:0:root: /root : /bin/bash /etc/passwd :operator:x:11:0:operator: /root : /sbin/nologin a.txt:root b.txt:root [root@mufenggrow ~] # |
3.3 搜索除了匹配行之外的行
此处使用-v 参数,比如取反
案例一: 统计文件的行数且不包含空行
空行的表示方法: ^$
?| 1 2 3 4 5 6 7 8 9 10 11 12 | [root@mufenggrow ~] # cp /etc/passwd ./ ## 源文件一共35行 [root@mufenggrow ~] # cat /etc/passwd |wc -l 35 ## 追加空行进去 [root@mufenggrow ~] # echo "" >> /etc/passwd [root@mufenggrow ~] # cat /etc/passwd |wc -l 36 ## 去掉空行测试 [root@mufenggrow ~] # grep -v ^$ /etc/passwd |wc -l 35 [root@mufenggrow ~] # |
有时候我们修改了配置文件,文件中包含大量的# ,我们想去掉#查看内容,就可以使用
?| 1 2 | [root@mufenggrow ~] # grep -v ^# passwd |wc -l 35 |
3.4 匹配的部分使用颜色显示
这里可以使用 --color=auto,我们来查看一下包含root的行,并高亮显示要查找的root。
?| 1 2 3 4 | [root@mufenggrow ~] # grep root /etc/passwd --color=auto root:x:0:0:root: /root : /bin/bash operator:x:11:0:operator: /root : /sbin/nologin [root@mufenggrow ~] # |
这样显示,效果不明显,我们看下图:
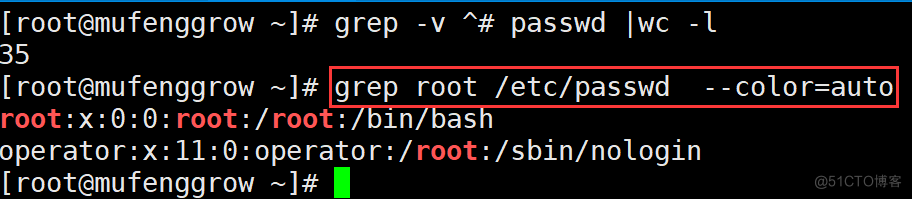
可以看到,所有的root都是红色表示的。
3.5 只输出文件中匹配到的地方
比如我们要查询root,但我不想显示包含root的行,而是只显示要查询的内容:
此时需要使用 -o 参数,代码如下
?| 1 2 3 4 5 | [root@mufenggrow ~] # grep -o root /etc/passwd root root root root |
要注意,如果一行中有10个root,这里就显示10个,而不是只显示一个,所以3.4的案例中我们查询的时候,包含root的有两行,但有4个root,在3.5案例中,显示了所有的root。
3.6 输出包含匹配字符串的行,并显示所在的行数
此处可以使用-n 参数, -n 会在一行的前面加上 行号: 比如“4:”
我们来看下代码示例:
?| 1 2 3 | [root@mufenggrow ~] # grep -n "root" passwd 1:root:x:0:0:root: /root : /bin/bash 11:operator:x:11:0:operator: /root : /sbin/nologin |
我们要统计一个文件一共有多少行,也可以使用-n 参数
?| 1 2 | root@mufenggrow ~] # grep -n "" passwd |awk -F : '{print $1}' |tail -n 1 35 |
3.7 统计文件或者文本中包含匹配字符串的行数
此时可以用-c参数:
?| 1 2 | [root@mufenggrow ~] # grep -c "root" passwd 2 |
包含root的有两行, 如果我们要统计文本的行数:
?| 1 2 | [root@mufenggrow ~] # grep -c "$" passwd 35 |
相当于查找 $的行数,可以看到一共有35个$符号,也就是35行。
总结
grep命令在日常工作中,应用的比较广泛,一定要认真学习,记熟记牢常用参数。
到此这篇关于linux中grep命令使用实战详解的文章就介绍到这了,更多相关linux grep命令内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.51cto.com/zmedu/6063987
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。