Linux服务器出现异常和卡顿排查思路和步骤

前言
Linux 服务器出现异常和卡顿的原因有很多,以下是一些常见的原因:
1、CPU 占用率过高:当 CPU 占用率过高时,系统的响应速度会变慢,甚至出现卡顿现象。常见的原因包括进程的死循环、CPU 密集型的任务等。
2、内存使用过高:当内存使用过高时,系统会使用交换分区(swap),这会导致系统的响应速度变慢,甚至出现卡顿现象。常见的原因包括内存泄漏、进程使用过多的内存等。
3、网络带宽不足:当网络带宽不足时,网络传输速度会变慢,甚至出现卡顿现象。常见的原因包括网络拥塞、网络带宽不足等。
4、硬盘 I/O 过高:当硬盘 I/O 过高时,系统的响应速度会变慢,甚至出现卡顿现象。常见的原因包括硬盘读写速度慢、文件系统损坏等。
5、进程数过多:当系统中运行的进程数过多时,会导致系统资源的竞争,从而导致系统的响应速度变慢,甚至出现卡顿现象。
6、系统配置不当:当系统配置不当时,也会导致系统出现异常和卡顿现象。常见的原因包括系统内核参数设置不当、硬件配置不足、网络配置不当等。
针对这些问题,可以通过一些常见的命令进行分析和调优,如 top、ps等,从而找出问题的根源并进行针对性的优化。
一、查看内存使用情况
显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存
free -h
持续观察内存使用情况,3s输出一次
free -h -s 3

主要关注free剩余的内存空间即可。
jar包大小和占用服务器运行内存之间没有直接的关系,即使java -jar指定了堆内存大小free -h也不会直接体现。
服务器运行内存是指Java程序在服务器运行时占用的内存大小。
Java程序运行时,JVM会将jar包中的类和资源加载到内存中,jar包大小可能会影响程序启动时间和内存使用情况。
二、查看磁盘使用情况
当存放日志、jar包文件、数据库备份文件过多也会导致系统性能下降,系统崩溃
df -h
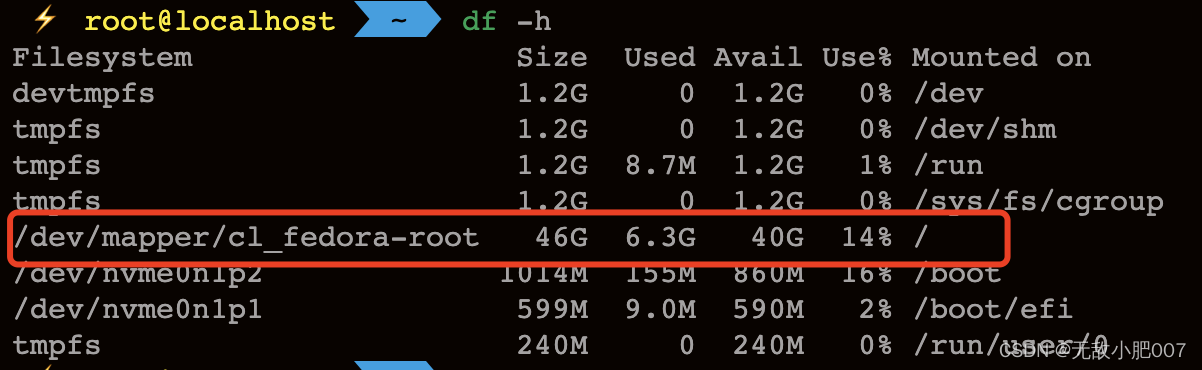
看根目录的使用情况。
三、top命令
一言不合就top,常用参数
- top -p 8080,8081 单独监控进程ID的状态
- top -c 显示完整的命令行
不加参数也可以进入top后使用内部命令:
1 – 数字1 按数字“1”可监控每个逻辑CPU的状况 f/F – 添加或删除top中的显示字段 K – 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。 u – 搜索某一用户得进程 n – 设置在进程列表所显示进程的数量 s – 改变画面更新周期,单位时秒 P – 排序【%cpu】以 CPU 占用率大小的顺序排列进程列表 c – 切换显示命令名称和完整命令行。 o或者O:改变显示项目的顺序 l – 关闭或开启第一部分第一行 切换显示平均负载和启动时间信息。 t – 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示切换显示进程和CPU状态信息。 m – 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示切换显示内存信息。 N – 排序【PID】以PID的大小的顺序排列表示进程列表 M – 排序【内存占用率】以大小的顺序排列进程列表 T – 排序【根据时间/累计时间进行】 i:忽略闲置和僵死进程。这是一个开关式命令。 S:切换到累计模式。 h – 显示帮助 q – 退出 top W:将当前设置写入~/.toprc文件中。 b – 打开/关闭运行线程【R状态】的加亮效果 x – 打开/关闭运行线程【R状态】排序列的加亮效果 ”shift + >”或”shift + < :可以向右或左改变排序列
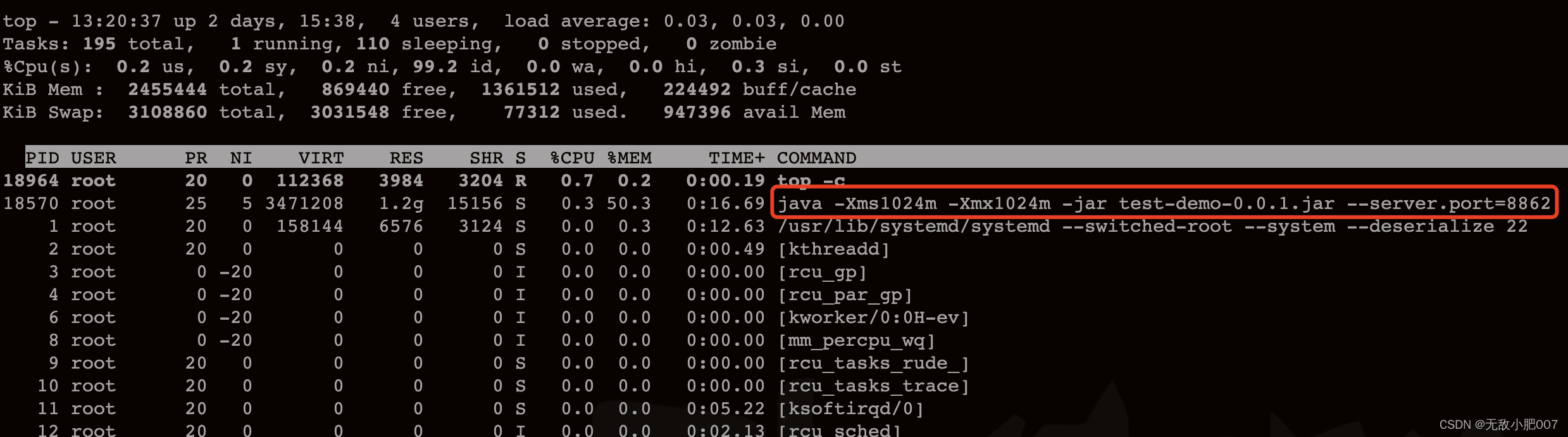
从top命令返回的数据中可以得到(按行)
- 系统时间-开机时长-登录人数-平均负载(1、5、15分钟内的负载,当此值超过CPU的数量就表示系统负载比较高了,可以通过停止或者优化占cpu资源的进程,或者增加硬件如cpu、内存、磁盘等)
- 总进程数-运行-休眠-停止-僵尸进程
- us:用户空间占用CPU的百分比,即应用程序的CPU使用率。
sy:内核空间占用CPU的百分比,即系统内核的CPU使用率。
ni:NICE值较高的进程占用CPU的百分比。
id:空闲CPU的百分比。
wa:等待I/O操作完成的CPU时间百分比。
hi:处理硬件中断的CPU时间百分比。
si:处理软件中断的CPU时间百分比。
- 内存总量-使用中的内存-空闲内存-缓存的内存量
- 交换区总量-使用的交换区总量-空闲交换区总量-缓冲的交换区总量
系统内存和交换空间(swap)是相互关联的,当系统内存不足时,操作系统会将一些不常用的内存数据移动到交换空间中,以释放物理内存,从而保证系统的正常运行。因此,可以将交换空间看作是一种扩展内存的方式,用于帮助系统更好地管理内存资源。由此可以观察此值,如果不断变化时,就是系统内存不足了。
- PID:进程 ID,用于唯一标识一个进程。USER:进程所属的用户,PR:进程的优先级,数值越小优先级越高,NI:进程的 nice 值,数值越小优先级越高,VIRT:虚拟内存大小,单位为 KB(千字节),包括进程使用的代码段、数据段、堆栈段以及共享库等占用的内存大小,RES:驻留内存大小,单位为 KB(千字节),指进程当前驻留在内存中的物理内存大小,也就是进程实际占用的内存大小,SHR:共享内存大小,单位为 KB(千字节),指进程使用的共享内存大小。S:进程状态,包括运行(R)、睡眠(S)、停止(T)、僵尸(Z)等状态,%CPU:进程占用 CPU 的比例,表示进程在 CPU 时间片中占用的时间比例,%MEM:进程占用物理内存的比例,表示进程占用物理内存大小与总内存大小的比例,TIME+:进程占用 CPU 的时间,包括用户态和内核态的 CPU 时间,COMMAND:进程的命令行信息,表示进程所执行的命令及其参数。
相关命令
查看CPU核心数 cat /proc/cpuinfo|grep processor|wc -l
3.1 jmap分析堆内存配置信息和使用情况
jmap -heap 命令输出的信息主要分为两部分,一部分是 Heap Configuration,表示 Java 进程的堆内存配置信息;另一部分是 Heap Usage,表示 Java 进程的堆内存使用情况。
1、top命令找到占用内存(RES列)高的Java进程PID。
RES(Resident Set Size)是指进程当前驻留在内存中的物理内存大小,也就是进程实际占用的内存大小。RES 包括了进程代码段、数据段、堆栈段以及共享库等占用的内存大小。RES 的大小可以反映一个进程的内存占用情况,通常来说,一个进程的 RES 越大,就表示它占用的内存越多。
2、查看分析heap内存使用情况
jmap -heap PID
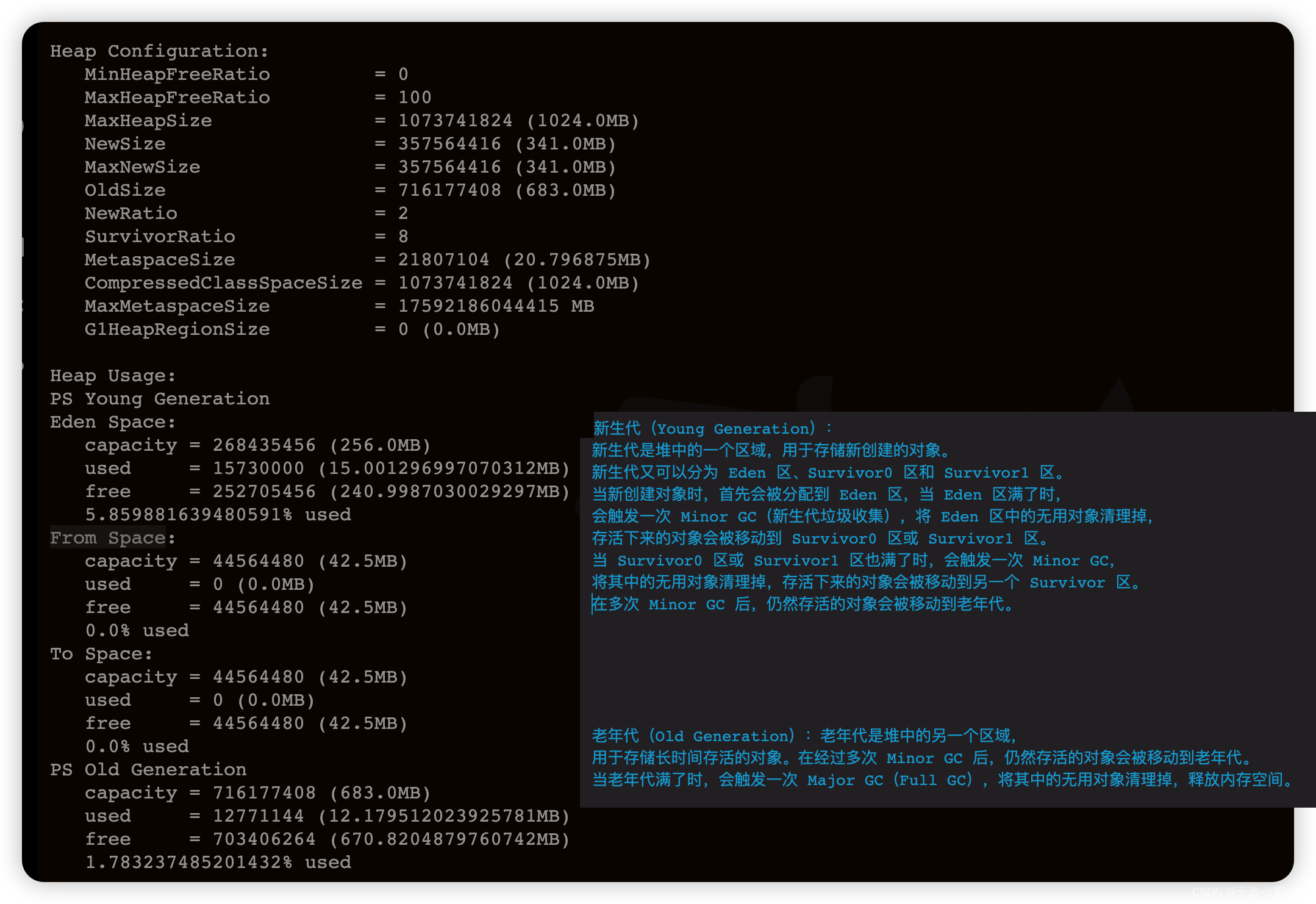
Heap Configuration 堆配置
-MinHeapFreeRatio:最小堆空闲比例。如果堆的空闲比例低于此值,则会尝试进行垃圾回收。
-MaxHeapFreeRatio:最大堆空闲比例。如果堆的空闲比例高于此值,则会尝试释放一些内存。
-MaxHeapSize:堆的最大大小。当堆的大小达到此值时,就不会再进行自动扩展。
-NewSize:新生代大小。
-MaxNewSize:新生代最大大小。
-OldSize:老年代大小。
-NewRatio:新生代和老年代的比例。例如,NewRatio=2 表示新生代和老年代的比例为 1:2。
-SurvivorRatio:Eden 区和 Survivor 区的比例。例如,SurvivorRatio=8 表示 Eden 区和 Survivor 区的比例为 8:1。
-MetaspaceSize:元空间大小。
-CompressedClassSpaceSize:压缩类空间大小。
-MaxMetaspaceSize:元空间最大大小。
-G1HeapRegionSize: G1 收集器的堆区域大小。
Heap Usage
-PS Young Generation:新生代内存使用情况。
-Eden Space:Eden 区内存使用情况。
-Survivor Space:Survivor 区内存使用情况。
-PS Old Generation:老年代内存使用情况。
对于 Heap Usage,我们可以看到各个区域的容量、已使用大小、空闲大小、使用占比等,这些信息可以帮助我们了解 Java 进程的内存使用情况,从而进行性能调优或故障排查。
3.2 jstack分析线程的执行情况
通过分析 jstack PID 命令输出的结果,可以了解 Java 进程中每个线程的执行情况,包括线程的状态、调用栈信息、锁信息和监视器信息等,从而快速定位线程相关的性能问题,如死锁、死循环、线程阻塞等问题。jstack 命令还可以用于分析线上问题,提供诊断线上问题的线索,帮助开发人员更快地定位问题并解决问题。
1、top命令找到占用CPU高的进程PID
2、jstack PID
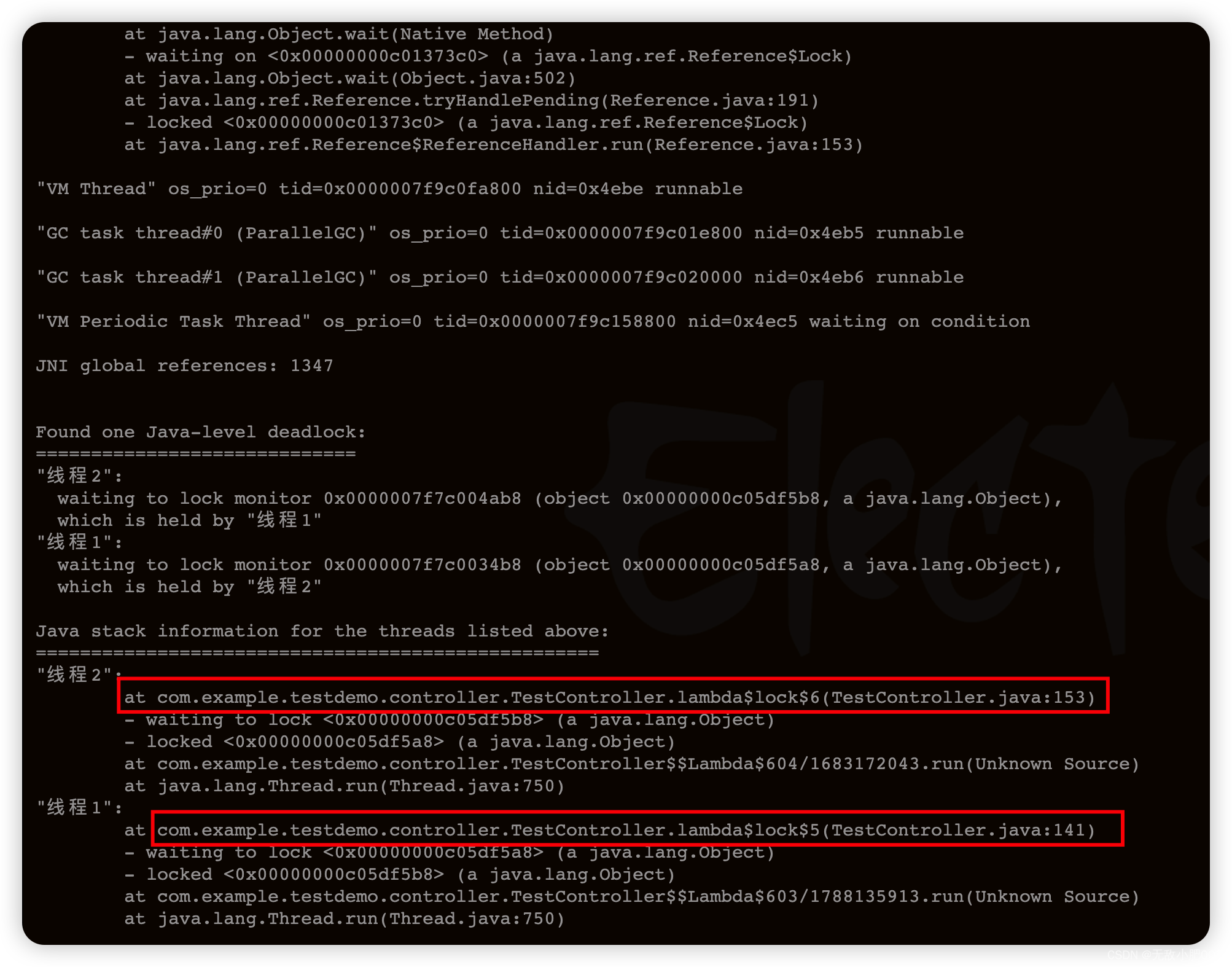
会打印以下信息:
- Java 线程的状态信息,包括线程 ID、线程名称、线程状态等。
- Java 线程堆栈信息,包括每个线程的调用栈信息,即线程当前正在执行的方法及其所在的类、行号等信息。
- Java线程锁信息,包括每个线程持有的锁信息,以及等待获取锁的线程信息。
- Java线程的监视器信息,包括每个线程持有的监视器信息,以及等待获取监视器的线程信息等。
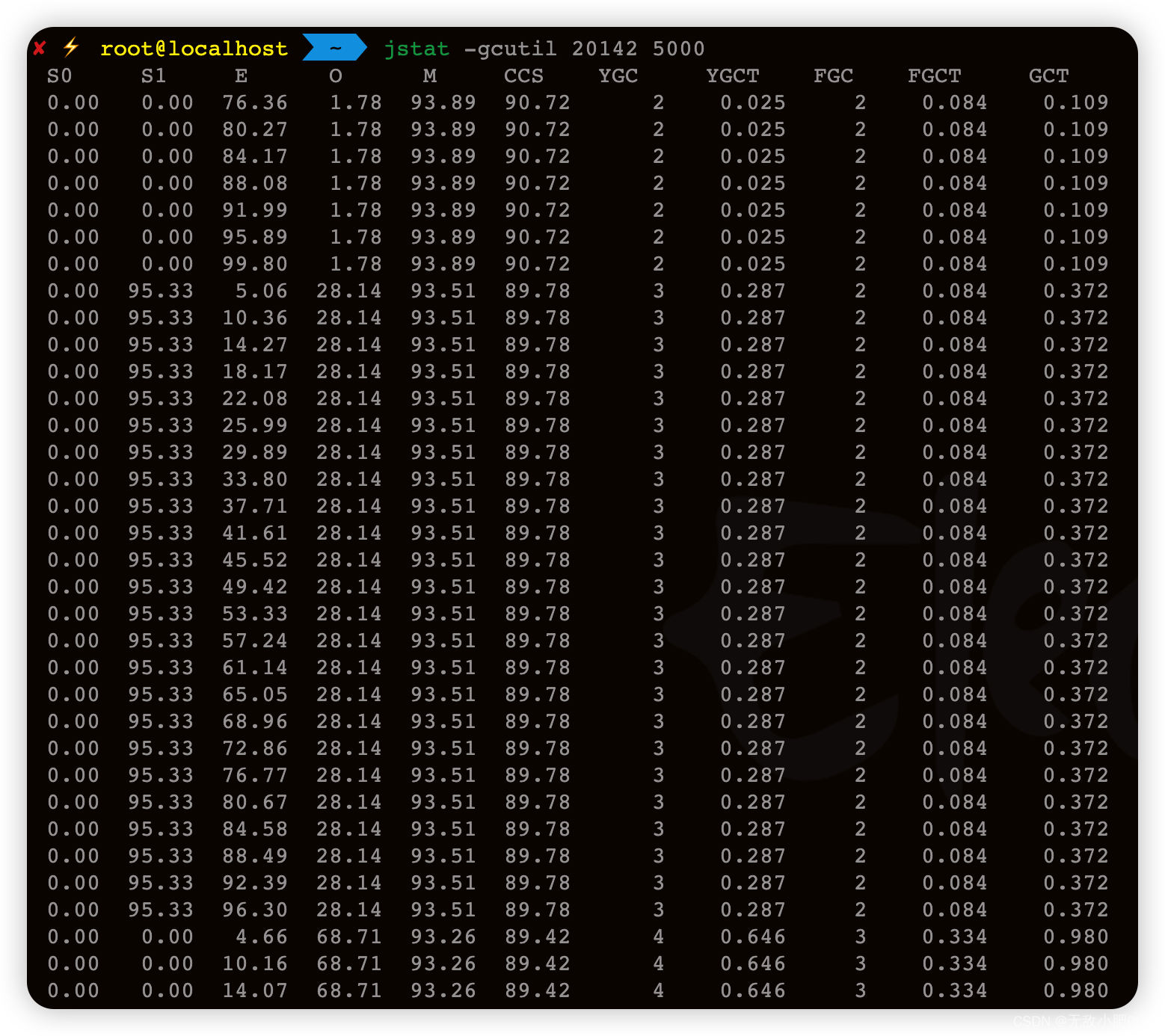
3.3 jstat查看各个区域占堆百分比
jstat -gcutil PID 5000
通过分析 jstat -gcutil PID 输出的结果,可以了解 Java 进程中不同区域的内存使用情况,以及 GC 操作的次数和时间,从而优化程序的内存使用和 GC 性能。
S0:表示 Survivor 区 0 的使用情况,即 Survivor 区 0 中已使用的比例。
S1:表示 Survivor 区 1 的使用情况,即 Survivor 区 1 中已使用的比例。
E:表示 Eden 区的使用情况,即 Eden 区中已使用的比例。
O:表示 Old 区的使用情况,即 Old 区中已使用的比例。
M:表示 Metaspace 区的使用情况,即 Metaspace 区中已使用的比例。
CCS:表示 Compressed Class Space 区的使用情况,即 Compressed Class Space 区中已使用的比例。
YGC:表示 Young GC 的次数,即 Young GC 已执行的次数。
YGCT:表示 Young GC 的总时间,即 Young GC 已执行的总时间。
FGC:表示 Full GC 的次数,即 Full GC 已执行的次数。
FGCT:表示 Full GC 的总时间,即 Full GC 已执行的总时间。
GCT:表示 GC 的总时间,即 GC 已执行的总时间。
四、其他指令
1、查看java进程内存占用
top -o %MEM -b -n 1 | grep java | awk '{print "PID: "$1" \t 虚拟内存: "$5" \t 物理内存: "$6" \t 共享内存: "$7" \t CPU使用率: "$9"% \t 内存使用率: "$10"%"}'
2、监控java线程数
ps -eLf | grep java | wc -l
3、查看占用端口
netstat -ntlp
4、列出所有进程信息(ps -aux 和 ps -ef 命令的主要区别在于输出信息的详细程度不同,前者输出的信息更加详细,后者输出的信息更加简略。)
ps -ef 和 ps -aux
总结
Linux服务器出现异常和卡顿有硬件和软件的原因,硬件没问题的情况可以通过top命令、jps命令、jmap分析堆内存配置信息和使用情况、jstack分析线程的执行情况、 jstat查看各区域占堆百分比和服务日志去排查问题。
到此这篇关于Linux服务器出现异常和卡顿排查思路和步骤的文章就介绍到这了,更多相关内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文地址:https://blog.csdn.net/weixin_45549188/article/details/129629486
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。