
mysql创建索引的3种方法实例

1、使用CREATE INDEX创建,语法如下:
?| 1 | CREATE INDEX indexName ON tableName (columnName(length)); |
2、使用ALTER语句创建,语法如下:
?| 1 | ALTER TABLE tableName ADD INDEX indexName(columnName); |
ALTER语句创建索引,下面提供一个设置索引长度的例子:
?| 1 2 3 | ALTER TABLE t_user_action_log ADD INDEX ip_address_idx (ip_address(16)); SHOW INDEX FROM t_user_action_log; |
3、建表的时候创建索引
?| 1 2 3 4 5 | CREATE TABLE tableName( id INT NOT NULL , columnName columnType, INDEX [indexName] (columnName(length)) ); |
示例:
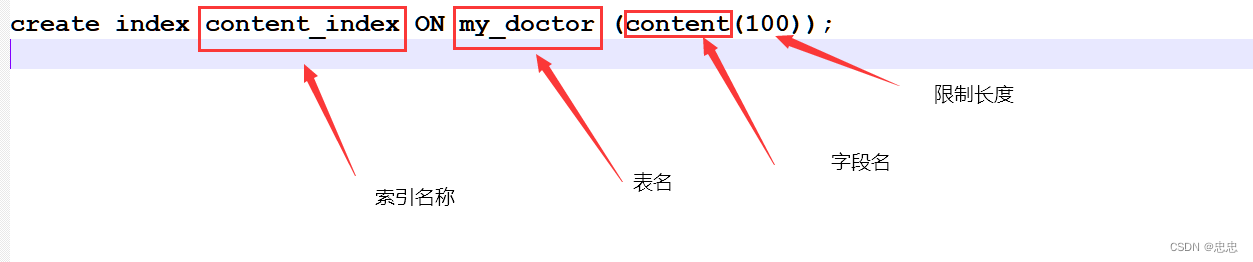
补充:MySql 创建索引原则
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
总结
到此这篇关于mysql创建索引的3种方法的文章就介绍到这了,更多相关mysql创建索引内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.csdn.net/qiannz/article/details/125271012
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








