
SQL 中 HAVING 常见的使用方法

HAVING 子句
始终要记得 SQL是一种基于“面向集合”思想设计的语言 。
1. 寻找缺失的编号
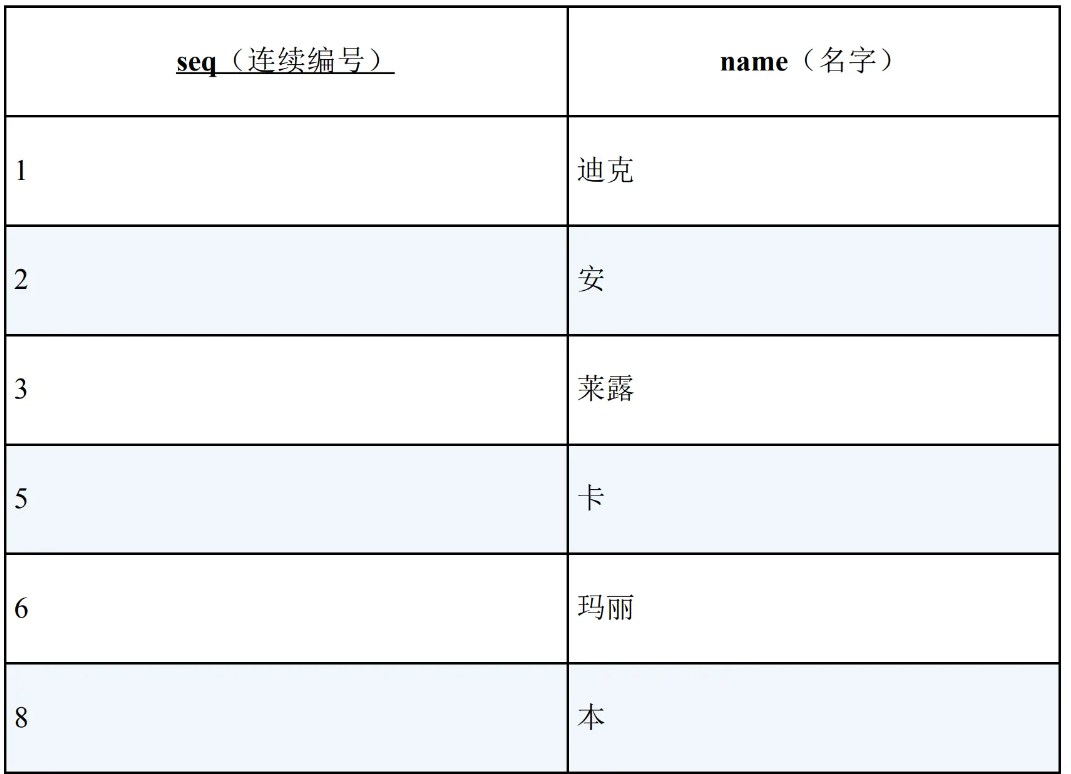
查询这张表里是否存在数据缺失。当前这张表的编号并不是连续的,缺少了 4 和 7(这里给出的列是有序的,实际情景下很有可能是无序的)。
?| 1 2 3 4 | -- 如果有查询结果,说明存在缺失的编号 SELECT 1 AS gap FROM SeqTbl HAVING COUNT (*) <> MAX (seq); |
如果这个查询结果有 1 行,说明存在缺失的编号;如果 1 行都没有,说明不存在缺失的编号。这是因为,如果用 COUNT(*) 统计出来的行数等于“连续编号”列的最大值,就说明编号从开始到最后是连续递增的,中间没有缺失。如果有缺失,COUNT(*) 会小于 MAX(seq) ,这样 HAVING 子句就变成真了。这个解法只需要 3 行代码,十分优雅。
上面的 SQL 语句里没有 GROUP BY 子句,此时整张表会被聚合为一行。这种情况下 HAVING 子句也是可以使用的。在以前的 SQL 标准里,HAVING 子句必须和 GROUP BY 子句一起使用,所以到现在也有人会有这样的误解。但是,按照现在的 SQL 标准来说, HAVING 子句是可以单独使用的 。不过这种情况下,就不能在 SELECT 子句里引用原来的表里的列了,要么就得像示例里一样使用常量,要么就得像 SELECT COUNT(*) 这样使用聚合函数。
也可以认为是对空字段进行了 GROUP BY 操作,只不过省略了 GROUP BY 子句。如果使用窗口函数时不指定 PARTITION BY 子句,就是把整个表当作一个分区来处理的,思路与这里也是一样的。
2. 查询缺少编号的最小值
?| 1 2 3 4 | -- 查询缺失编号的最小值 SELECT MIN (seq + 1) AS gap FROM SeqTbl WHERE (seq+ 1) NOT IN ( SELECT seq FROM SeqTbl); |
要注意!
- 如果表里没有编号 1,那么缺失编号的最小值应该是 1,但是这两条 SQL 语句都不能得出正确的结果
- 如果表里包含 NULL ,那么这条 SQL 语句也不能得出正确的结果
3. 求众数

| 1 2 3 4 5 | -- 求众数的SQL:使用极值函数 SELECT income, COUNT (*) AS cnt FROM Graduates GROUP BY income HAVING COUNT (*) >= ( SELECT MAX (cnt) FROM ( SELECT COUNT (*) AS cnt FROM Graduates GROUP BY income) TMP ) ; |
这里使用MAX极值函数而不是ALL谓词是因为极值函数可以避免Null值带来的问题。详细内容可以看 一文详解SQL 中的三值逻辑 这篇文章。
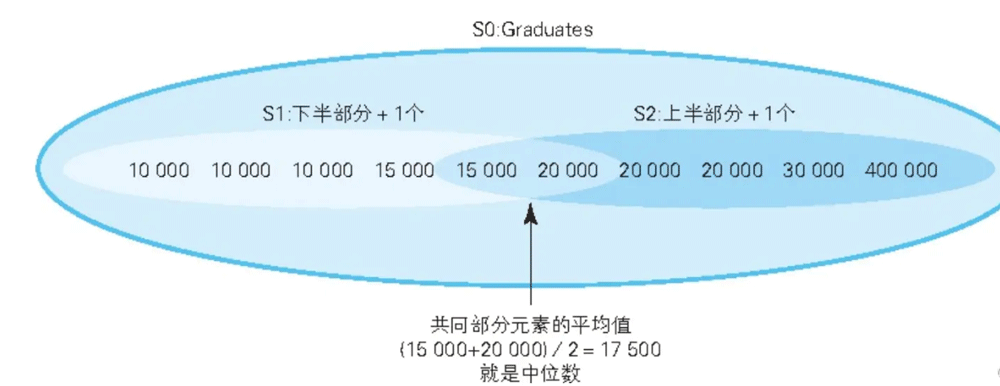
4. 求中位数
将集合里的元素按照大小分为上半部分和下半部分两个子集,同时让这 2 个子集共同拥有集合正中间的元素。
这样,共同部分的元素的平均值就是中位数:
| 1 2 3 4 5 6 7 8 9 10 11 12 | -- 求中位数的SQL 语句:在HAVING 子句中使用非等值自连接 SELECT AVG ( DISTINCT income) -- 这里一定要去重后 再求平均 FROM ( SELECT T1.income FROM Graduates T1, Graduates T2 GROUP BY T1.income -- S1 的条件 小于等于T2的数量大于等于全部的一半 HAVING SUM ( CASE WHEN T2.income >= T1.income THEN 1 ELSE 0 END ) >= COUNT (*) / 2 -- S2 的条件 大于等于T2的数量大于等于全部的一半 AND SUM ( CASE WHEN T2.income <= T1.income THEN 1 ELSE 0 END ) >= COUNT (*) / 2 -- 同时满足 小于等于T2的数量大于等于全部的一半 且 大于等于T2的数量大于等于全部的一半 即说明T2在前后两部分的中间的交集中 ) TMP; |
5. 查询不包含 NULL 的集合
COUNT 函数的使用方法有 COUNT(*) 和 COUNT( 列名 ) 两种,
它们的区别有两个:
- 第一个是性能上的区别;第二个是 COUNT(*) 可以用于 NULL ,而 COUNT( 列名 ) 与其他聚合函数一样,要先排除掉NULL 的行再进行统计。
- 第二个区别也可以这么理解:COUNT(*) 查询的是所有行的数目,而 COUNT( 列名 ) 查询的则不一定是。
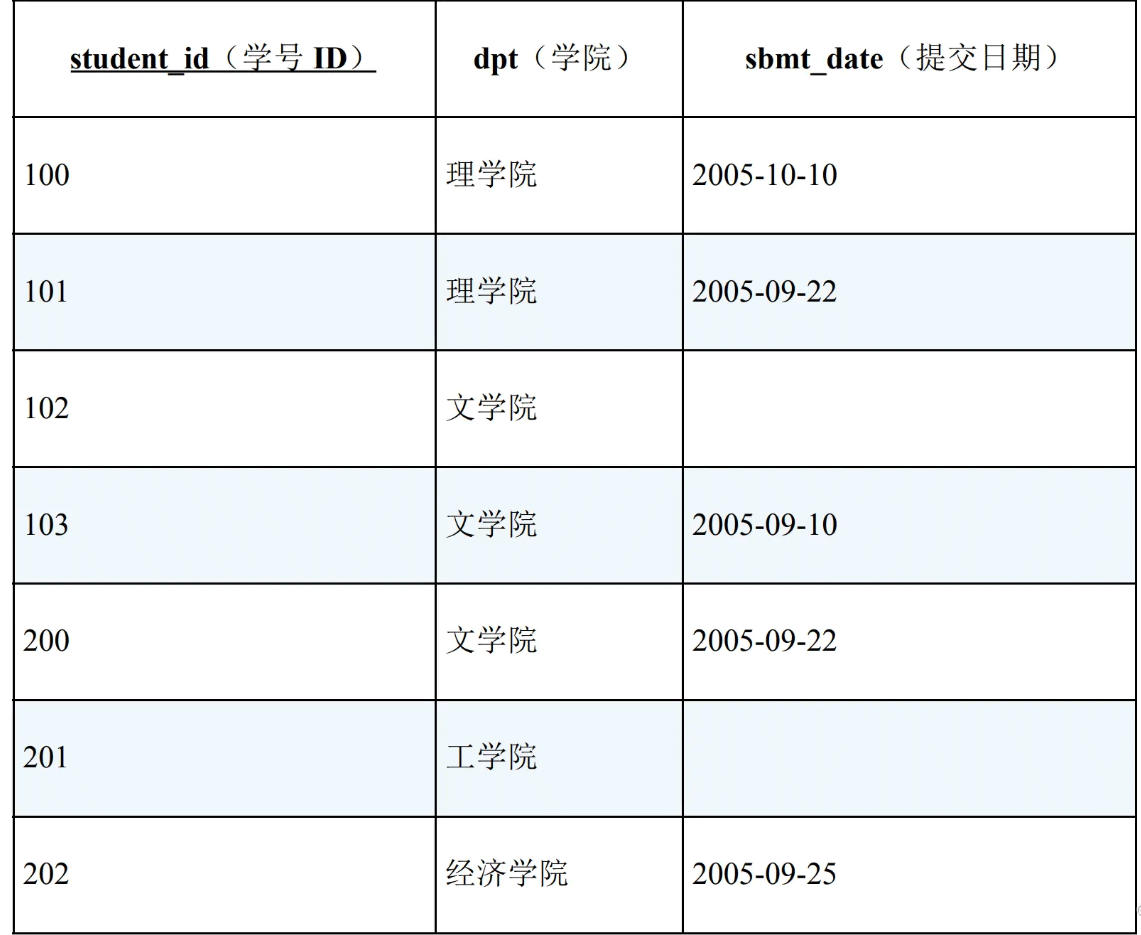
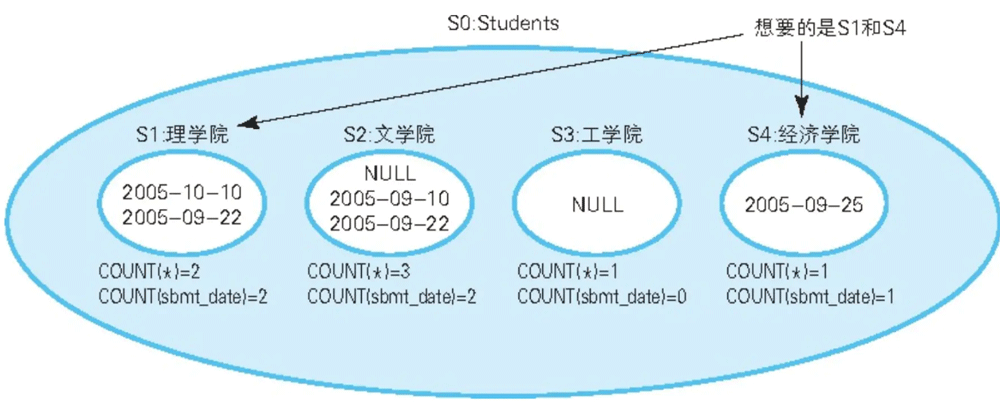
现在需要查找哪些学院的学生全部都提交了报告(即理学院、经济学院)。
| 1 2 3 4 | SELECT dpt FROM Students GROUP BY dpt HAVING COUNT (*) = COUNT (sbmt_date); |
同样可以使用case表达式
?| 1 2 3 4 | SELECT dpt FROM Students GROUP BY dpt HAVING COUNT (*) = SUM ( CASE WHEN sbmt_date IS NOT NULL THEN 1 ELSE 0 END ); |
在这里,CASE 表达式的作用相当于进行判断的函数,用来判断各个元素(= 行)是否属于满足了某种条件的集合。这样的函数我们称为特征函数(characteristic function),或者从定义了集合的角度来将它称为定义函数
6. 关系除法运算
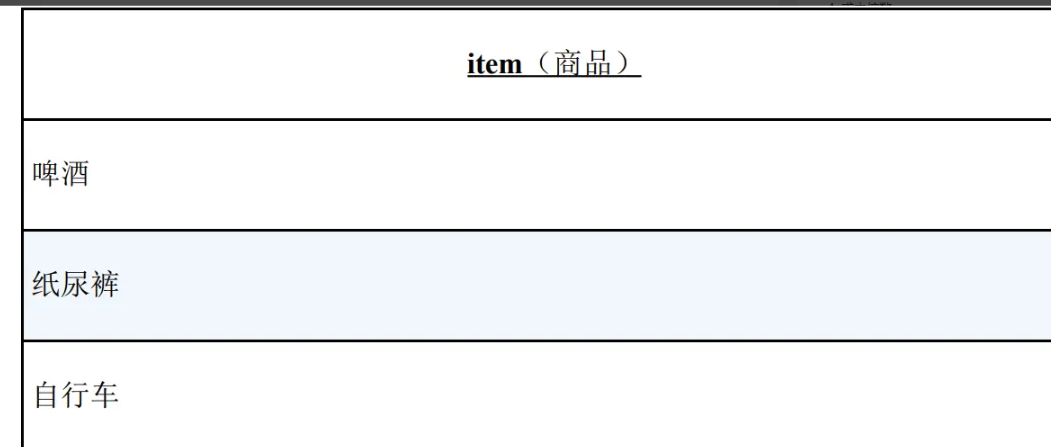
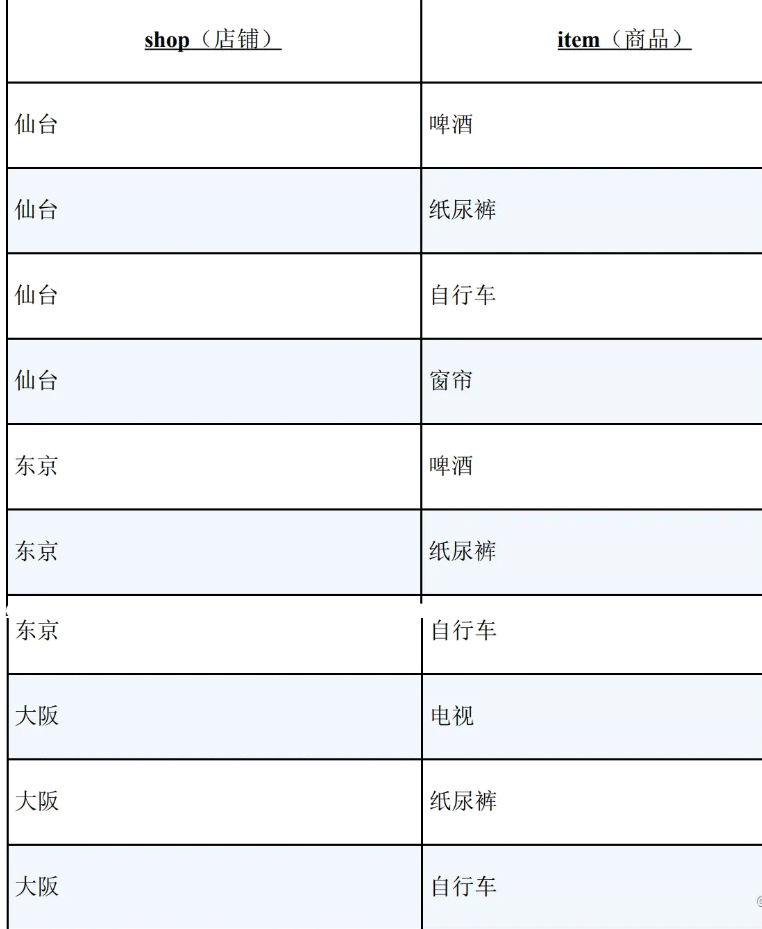
现在需要查询囊括了表 Items 中所有商品的店铺(仙台店和东京店)。
?| 1 2 3 4 5 | SELECT SI.shop FROM ShopItems SI, Items I WHERE SI.item = I.item GROUP BY SI.shop HAVING COUNT (SI.item) = ( SELECT COUNT (item) FROM Items) |
同样也可以写出 只包含 Items 中所有商品的店铺(东京店)
?| 1 2 3 4 5 6 | SELECT SI.shop FROM ShopItems SI LEFT OUTER JOIN Items I ON SI.item=I.item GROUP BY SI.shop HAVING COUNT (SI.item) = ( SELECT COUNT (item) FROM Items) -- 条件1 AND COUNT (I.item) = ( SELECT COUNT (item) FROM Items); -- 条件2 |
总结
到此这篇关于SQL 中 HAVING 常见的使用方法的文章就介绍到这了,更多相关SQL HAVING内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://juejin.cn/post/7144313078627172360
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








