
准线上事故之MySQL优化器索引选错

1 背景
最近组里来了许多新的小伙伴,大家在一起聊聊技术,有小兄弟提到了MySQL的优化器的内部策略,想起了之前在公司出现的一个线上问题,今天借着这个机会,在这里分享下过程和结论。排查的过程中,也是学习的过程,下面把排查的过程和分析记录下来,以供大家参考。
2 过程和分析
2.1 问题发现
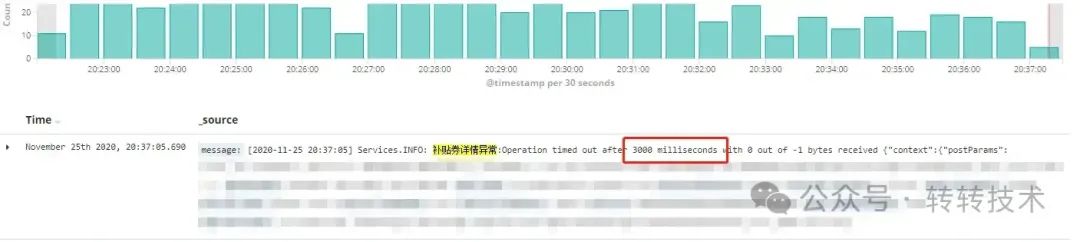
20年的某个下午,突然收到大量慢查询的告警,同时业务运营在群里反馈红包相关页面加载慢,怀疑系统出问题了,问题发到群里之后,经过日志定位和代码review多重确认,有一条sql成了重点怀疑对象,最终确定的原因是MySQL查询过程中,优化器没有选择最优的索引导致的。
 图片
图片
需要说明的是,这里使用的MySQL版本是5.7版本。存储引擎是默认的InnoDB
2.2 问题定位
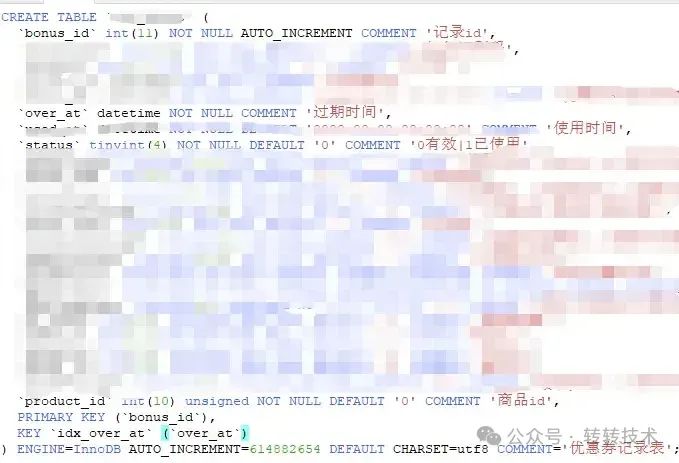
涉及到的表如下:
 图片
图片
问题sql如下:
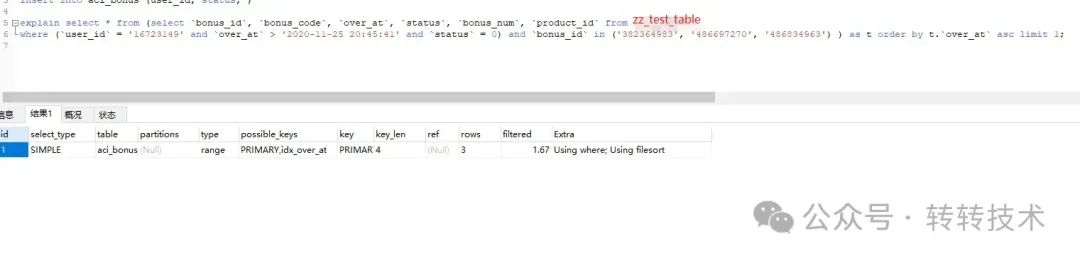
select `bonus_id`, `bonus_code`, `over_at`, `status`, `bonus_num`, `product_id` from `zz_test_table`
where `user_id` = '16723149' and `over_at` > '2020-11-25 20:45:41' and `status` = 0
and `bonus_id` in ('382364983', '486697270', '486834963') order by `over_at` asc limit 1;
该sql就涉及一张表zz_test_table(真实表名已被隐藏),表里面有两个索引,一个是over_at字段对应的idx_over_at索引,另一个就是bonus_id字段对应的主键索引。
可以看到,sql其实并不复杂,但是执行结果竟然耗费3秒以上,对于一个面向app用户的接口,3秒以上的响应简直无法接受,如果对业务影响严重点的话,甚至于都需要写事故报告了。
果断祭出explain大法 先来看看原始的查询情况,如下图:
 图片
图片
可以看到mysql并没有命中主键索引,而是命中的idx_over_at索引,预估行数为41314647行,这里大家就不要纠结了,为什么这么大的表,历史原因了,后面已经优化掉了。
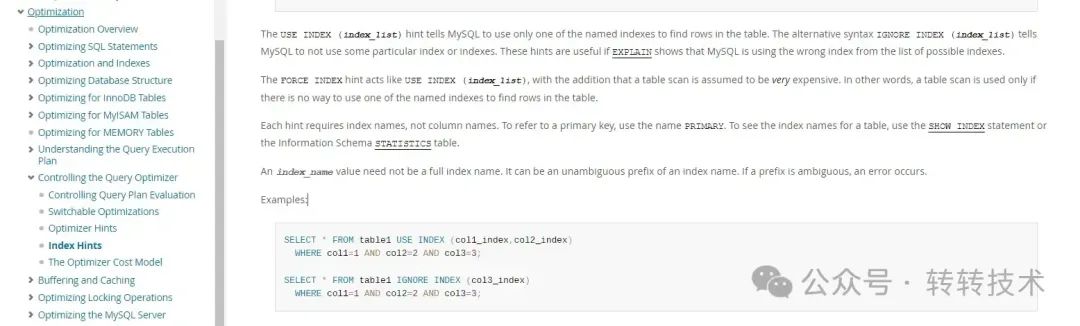
MySQL官方文档中有描述,我们可以直接强制指定优化器使用我们指定的索引。
 图片
图片
强制指定使用主键索引试试
 图片
图片
发现使用强制索引之后,sql执行0.103秒就返回了。
问题定位到这里,好像已经比较清楚了,就是MySQL优化器没有正确选择索引导致的呗。
MySQL:我可不背这个锅,你们自己好好反省下。
MySQL说的有道理,为啥好端端的线上会出现3秒的慢查询呢,这个情况之前为什么没有呢,我们先不管人家MySQL优化器的问题,先来分析下,为什么走了idx_over_at索引之后,3秒都没返回数据呢?
那么idx_over_at索引本身是不是有问题呢?,果然,经过排查,是因为有个小兄弟上线的代码有bug,over_at字段被大量写成同一个值,导致我们原本比较均匀的over_at字段存在了大量重复值,索引检索行数指数上升,已经基本类似全表扫描。
还了MySQL清白之后,我们继续来定位下,为什么优化器不使用更高效率的主键索引呢?在这个过程中,我们又发现一些奇怪的现象。
2.3 问题延伸
奇怪现象一:
 图片
图片
惊奇的事情发生了,limit 由1 变更为3之后,走了主键索引。
奇怪现象二:
 图片
图片
惊奇的事情又发生了,order by 把主键ID加上之后,也走了主键索引。
奇怪现象三:
 图片
图片
惊奇的事情继续发生,套了一层子查询,也走了主键索引。
2.4 问题分析
MySQL:是不是很懵逼,如果碰到此类情况,请问阁下应该如何应对?
得,超出理解范畴了,没办法去翻文档吧。MySql5.7官方文档
 图片
图片
相对来说,官方的文档关于优化器的说明较为分散,想要快速上手的小伙伴,可以考虑观看阿里云藏经阁出版的深入MySQL实战一书。
附书中关于mysql执行的过程图
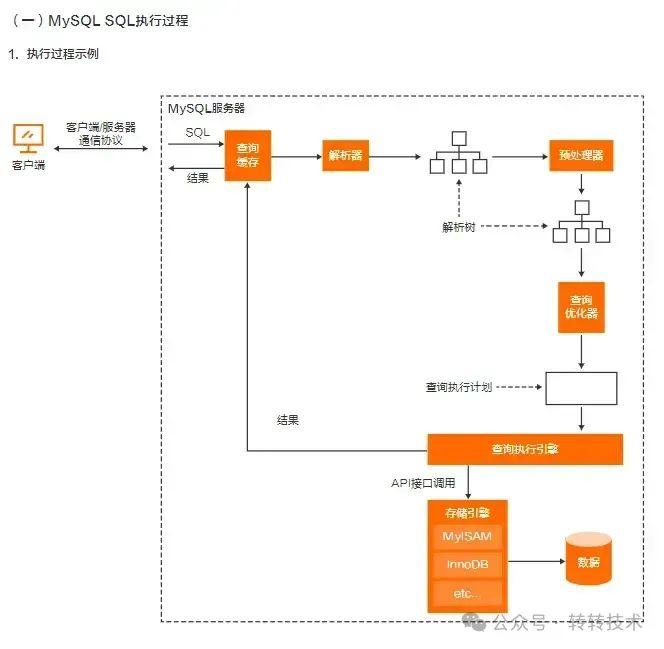 图片
图片
再来看书中关于优化器的执行过程图
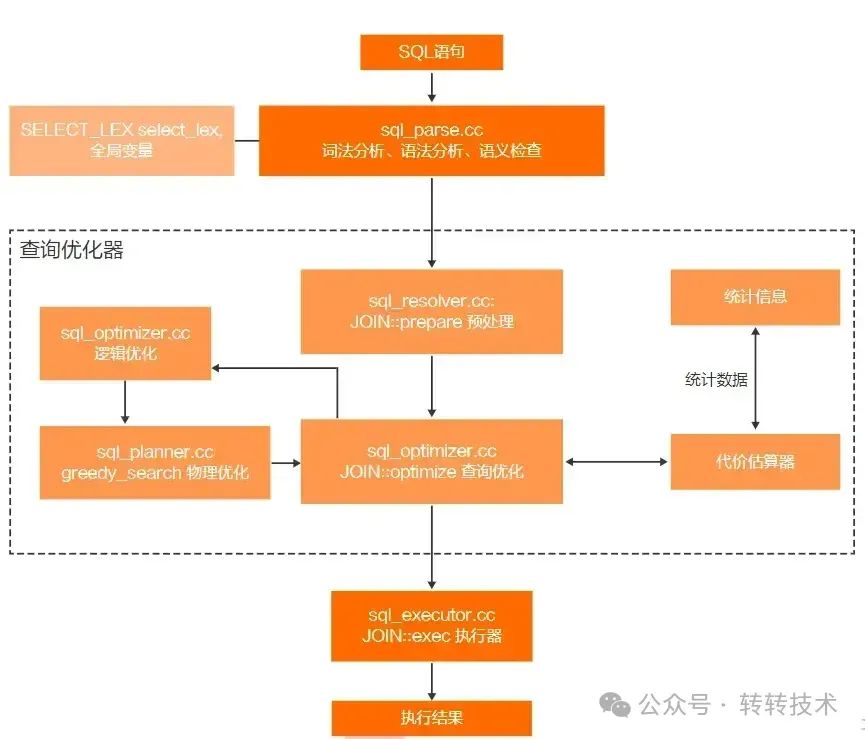 图片
图片
从以上资料中,我们得出了一些结论,基于这些结论,最后我们可以思考一些解决办法:
- 在MySQL里面,优化器的优化依据是执行成本,它的本质是CBO【Cost-based Optimizer,基于成本的优化器】,也就是说执行计划的生成是基于成本的。
- MySQL优化器工作的前提是了解数据,工作的目的是解析SQL,生成执行计划。但是优化器并没有想象中的那么完善,执行成本主要基于行数去决定,但是扫描行数并不是唯一的执行策略,优化器同时会结合是否使用临时表、是否排序、查询数量等因素进行综合判断。
- 总的来说,我们上面出现的三种奇怪现象都可以用上面优化器的判断标准去解释,子查询(临时表)、order by(排序) 、limit(查询数量)。
这里我考虑使用优化器的trace工具来详细分析下limit 1 和 limit 3为什么走了不同索引。由于trace会影响性能,我们把部分数据还原到本地进行测试,两次执行sql分别如下:
trace分析LIMIT 3
set optimizer_trace="enabled=on";
select `bonus_id`, `bonus_code`, `over_at`, `status`, `bonus_num`, `product_id` from `zz_test_table` where `user_id` = '16723149' and `over_at` > '2020-11-25 20:45:41' and `status` = 0 and `bonus_id` in ('382364983', '486697270', '486834963') order by `over_at` asc limit 3
select * FROM information_schema.optimizer_trace;
set optimizer_trace="enabled=off";
LIMIT 3 分析结果
 图片
图片
具体参数解析如下:
- "range_analysis": {"table_scan": {"rows": 1446041, "cost": 695910 }} 表示全表扫描操作预估会扫描到大约1446041行数据,属于非常大的操作量,全表扫描的预计代价(时间或资源消耗)为695910。
- "potential_range_indices": 列出了查询优化器分析后认为可以使用的索引。
- PRIMARY 索引,在本次查询中是可用的。这个索引基于 bonus_id 这一列,idx_over_at 索引,也在本次查询中是可用的。
trace分析LIMIT 1
set optimizer_trace="enabled=on";
select `bonus_id`, `bonus_code`, `over_at`, `status`, `bonus_num`, `product_id` from `zz_test_table` where `user_id` = '16723149' and `over_at` > '2020-11-25 20:45:41' and `status` = 0 and `bonus_id` in ('382364983', '486697270', '486834963') order by `over_at` asc limit 1
select * FROM information_schema.optimizer_trace;
set optimizer_trace="enabled=off";
LIMIT 1 分析结果
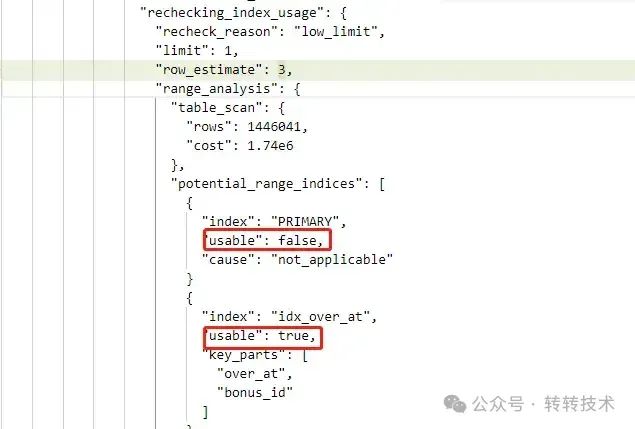 图片
图片
具体参数解析如下:
- "rechecking_index_usage": 代表查询优化器对我们的索引进行了重新检查和考虑。
- {"recheck_reason": "low_limit", "limit": 1, "row_estimate": 3,} :原因(recheck_reason)是因为 LIMIT 参数比较低(只有1),即查询只需要返回一行记录,而先前的索引选择可能返回的记录大于1(estimated 3行)。
- "range_analysis": {"table_scan": {"rows": 1446041, "cost": 1.74e6 }} 这是查询优化器对主键(通常被视作一种默认索引)进行全表扫描的预估,大约有1446041行数据,预计的成本(用时 or IO次数)是1.74e6。
- "potential_range_indices": 这列出了查询优化器考虑过的索引和它们可用性。
- PRIMARY 是第一个索引,也就是主键索引。它在这次查询中并不可用。原因 not_applicable 表示这个索引在查询时并不适用。idx_over_at 是另一个被考虑的索引,结果是可用的。
通过这段日志,我们可以知道查询优化器为了优化查询操作(特别是对 LIMIT 1的优化)做出了一系列的决策和调整,当limit 1的时候,查询优化器认为不使用主键索引的成本会更小。因为这在优化器的成本分析中是更优更快的查询方式。老实说,这里感觉MySQL有点自作聪明了。
3 解决思路
当我们认为SQL的执行计划不合理时,可以使用explain 结合 trace工具去监听整个索引的使用、以及优化器进行优化的一些过程信息,如有必要,可以通过适当的手段去干预优化器。
- 最快的解决方式应该就是强制指定主键索引了,这种方式在我们需要快速解决线上问题的时候,还是很好用的。但是需要注意的是,强制指定索引是有一定风险的,如果哪天哪个小伙伴在不清楚这里的逻辑之下,修改了索引,极有可能会发生线上事故。
- 在MySQL的官方文档以及一些其他文章有特别说到,优化器的扫描行数,会随着表的数据新增、删除、字段变更等因素,统计的行数会变的不准确。这里可以考虑使用analyze table table_name 的方式去修复。需要注意的是,这个操作一般小伙伴是没有权限的,涉及线上操作。安全起见,如果需要验证,可以考虑把备份表down到本地去进行验证。
- 通过order by 、临时表、limit 等去干扰优化器。
- 设计合理的索引,编写合适的查询语句。MySQL:你这也太泛了
4 总结
这篇文章是基于工作实际中碰到的问题,把问题产生的原因和解决思路总结了下。文中针对提到的一些索引选择差异情况我们结合了解到的优化器执行策略,使用trace工具进行了验证。优化器有一套非常复杂的算法策略,本人对于MySQL的理解深度有限,这里就不详细分析了,还需要继续学习。
另外了解到MySQL 8.0优化器对查询执行计划的选择做了进一步的改进,理想状态下,会基于估算成本选择最有效的执行计划。感兴趣的小伙伴可以去试试。
原文地址:https://mp.weixin.qq.com/s/lIBbDPlQ-lb-rlAQxmLaxA
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








