
MySQL死锁使用详解及检测和避免方法

目录
- 前言
- 锁的释放与阻塞
- 死锁的发生和检测
- 查看锁信息(日志)
- 死锁的避免
前言
上一篇博客我们知道的Mysql事务的隔离机制和实现,以及锁的详细解析
链接: MySQL脏读幻读不可重复读及事务的隔离级别和MVCC、LBCC实现
在我们使用锁的时候,有一个问题是需要注意和避免的,我们知道,排它锁有互斥的特性。一个事务或者说一个线程持有锁的时候,会阻止其他的线程获取锁,这个时候会造成阻塞等待,如果循环等待,会有可能造成死锁。
这个问题我们需要从几个方面来分析,一个是锁为什么不释放,第二个是被阻塞了怎么办,第三个死锁是怎么发生的,怎么避免。
锁的释放与阻塞
回顾:锁什么时候释放?
事务结束(commit,rollback)﹔
客户端连接断开。
如果一个事务一直未释放锁,其他事务会被阻塞多久?会不会永远等待下去?
如果是,在并发访问比较高的情况下,如果大量事务因无法立即获得所需的锁而挂起,会占用大量计算机资源,造成严重性能问题,甚至拖跨数据库。
线上怕不怕这个错?
[Err] 1205 - Lock wait timeout exceeded; try restarting transaction
MySQL有一个参数来控制获取锁的等待时间,默认是50秒。
show VARIABLES like "innodb_lock_wait_timeout";
对于死锁,是无论等多久都不能获取到锁的,这种情况,也需要等待50秒钟吗?那不是白白浪费了50秒钟的时间吗?
死锁的发生和检测
演示一下,开两个会话:
方便对时间线的提现,这里用图片,有兴趣的可以跟着模仿一下
栗子一:

栗子二:
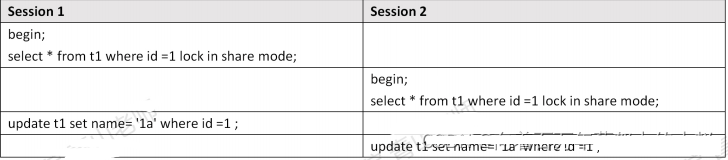
在第一个事务中,检测到了死锁,马上退出了,第二个事务获得了锁,不需要等待50秒:
[Err] 1213 - Deadlock found when trying to get lock; try restarting transaction
为什么可以直接检测到呢?是因为死锁的发生需要满足一定的条件,对于我们程序员来说,有明确的条件,意味着能判定,所以在发生死锁时,InnoDB一般都能通过算法(wait-for graph)自动检测到。
那么死锁需要满足什么条件?死锁的产生条件,因为锁本身是互斥的:
- (1)同一时刻只能有一个事务持有这把锁;
- (2)其他的事务需要在这个事务释放锁之后才能获取锁,而不可以强行剥夺;
- (3)当多个事务形成等待环路的时候,即发生死锁。
理发店有两个总监。一个负责剪头的Tony老师,一个负责洗头的Kelvin老师。Tony老师不能同时给两个人剪头,这个就叫互斥。
Tony在给别人在剪头的时候,你不能让他停下来帮你剪头,这个叫不能强行剥夺。
如果Tony的客户对Kelvin说:你不帮我洗头我怎么剪头? Kelvin 的客户对Tony说:你不帮我剪头我怎么洗头?这个就叫形成等待环路。
实际上,发生死锁的情况非常多,但是都满足以上3个条件。
这个也是表锁是不会发生死锁的原因,因为表锁的资源都是一次性获取的。
如果锁一直没有释放,就有可能造成大量阻塞或者发生死锁,造成系统吞吐量下降,这时候就要查看是哪些事务持有了锁。
查看锁信息(日志)
首先,SHow STATUS命令中,包括了一些行锁的信息:
show status like "innodb_row_lock_%";
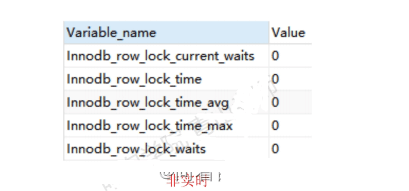
lnnodb_row_lock_current_waits:当前正在等待锁定的数量;
lnnodb_row_lock_time :从系统启动到现在锁定的总时间长度,单位ms;
Innodb_row_lock_time_avg :每次等待所花平均时间;
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花的时间;
lnnodb_row_lock_waits :从系统启动到现在总共等待的次数。
SHOW命令是一个概要信息。InnoDB还提供了三张表来分析事务与锁的情况:
select * from information_schema.INNODB_TRX; --当前运行的所有事务﹐还有具体的语句

select* from information_schema.INNODB_LOCKS; --当前出现的锁

select * from information_schema.INNODB_LOCK_WAITS; --锁等待的对应关系

更加详细的锁信息,开启标准监控和锁监控:
额外的监控肯定会消耗额外的性能
set GLOBAL innodb_status_output=ON; set GLOBAL innodb_status_output_locks=ON;
通过分析锁日志,找出持有锁的事务之后呢?
如果一个事务长时间持有锁不释放,可以kill事务对应的线程ID,也就是INNODB_TRX表中的trx_mysql_thread_id,例如执行kill 4,kill 7, kill 8。
当然,死锁的问题不能每次都靠kill线程来解决,这是治标不治本的行为。我们应该尽量在应用端,也就是在编码的过程中避免。
有哪些可以避免死锁的方法呢?
死锁的避免
- 1、在程序中,操作多张表时,尽量以相同的顺序来访问(避免形成等待环路)
- 2、批量操作单张表数据的时候,先对数据进行排序(避免形成等待环路);
- 3、申请足够级别的锁,如果要操作数据,就申请排它锁;
- 4、尽量使用索引访问数据,避免没有where条件的操作,避免锁表;
- 5、如果可以,大事务化成小事务;
- 6、使用等值查询而不是范围查询查询数据,命中记录,避免间隙锁对并发的影响。
到此这篇关于MySQL死锁使用详解及检测和避免方法的文章就介绍到这了,更多相关MySQL死锁 内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文地址:https://blog.csdn.net/weixin_44688973/article/details/125563264
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









