
MySQL学习之分组查询的用法详解

目录
- 为什么要分组
- 逐级分组
- 逐级分组对 SELECT 子句的要求
- 对分组结果集再次做汇总计算
- GROUP_CONCAT 函数
- GROUP BY 子句的执行顺序
该章节来开始学习分组查询,上一章节我们学习了聚合函数,默认统计的是全表范围内的数据,配合上 WHERE 就能够缩小统计的范围了。但是这并不能满足我们的要求,比如说我们按照之前的数据表查询每个部门的平均底薪是多少?这样的记录就需要针对部门编号进行分组了。根据分组的情况统计分组内的最大值、最小值、平均值等等。如此就能够满足刚刚提到的 “查询每个部门的平均底薪” 这样的需求了,另外,“分组查询” 是 SQL 中很重要的一个语法,大家一定要好好掌握它。
为什么要分组
上面也提到,聚合函数默认是对全表范围内的数据做统计,在一些特定的场景下不太适用,就比如 对数据分别进行统计的 场景。
由于聚合函数的这样的局限性,也就产生了分组的概念,于是就有了分组的语法。
分组的语法是通过 “GROUP BY” 来实现的。
"GROUP BY" 子句的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后再针对每个小区域分别进行数据汇总处理
分组语句演示案例:(计算每一个部门的平均底薪)
SELECT deptno, AVG(sal) FROM t_emp GROUP BY deptno; -- 利用 GROUP BY 子句将 deptno 进行分组,在利用 AVG() 聚合函数计算各个 deptno(部门) 的平均月薪
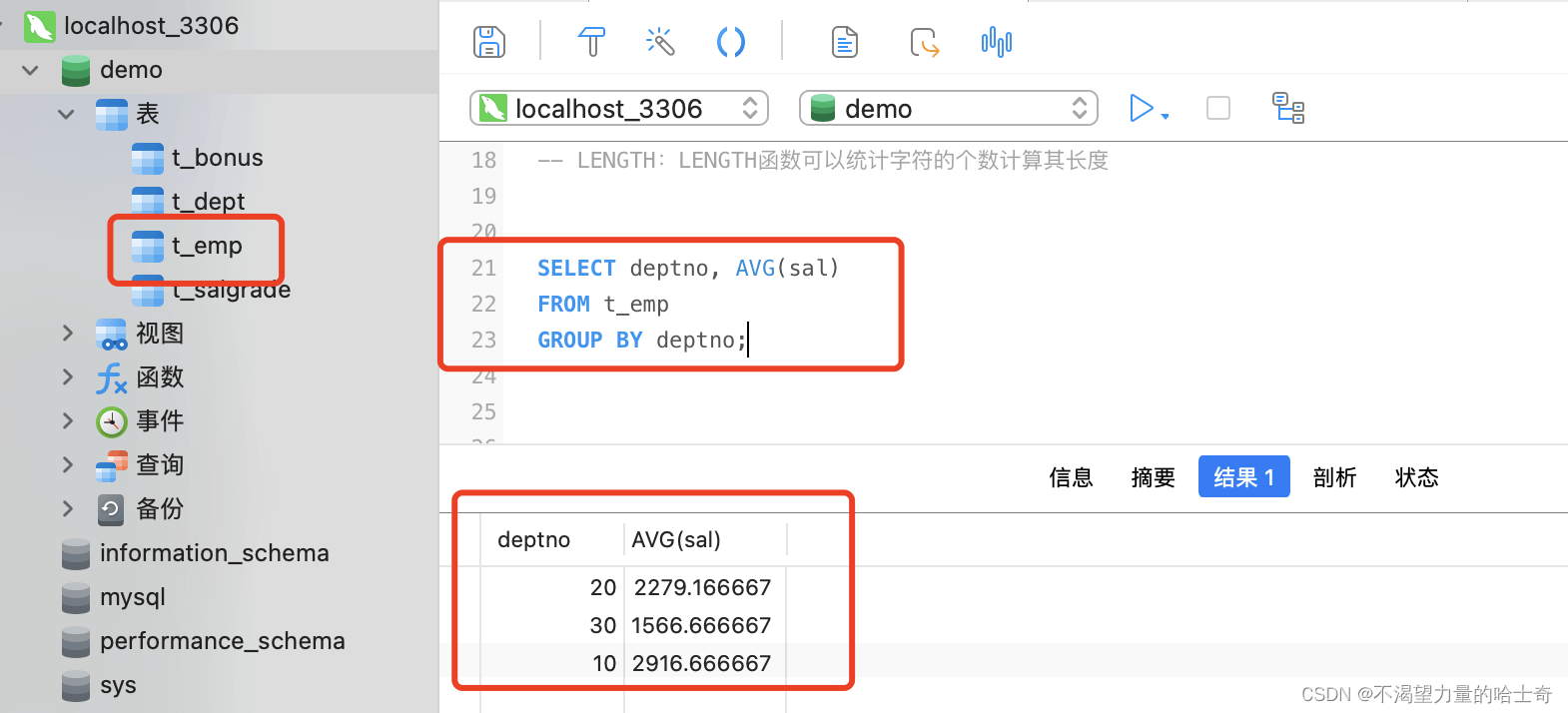
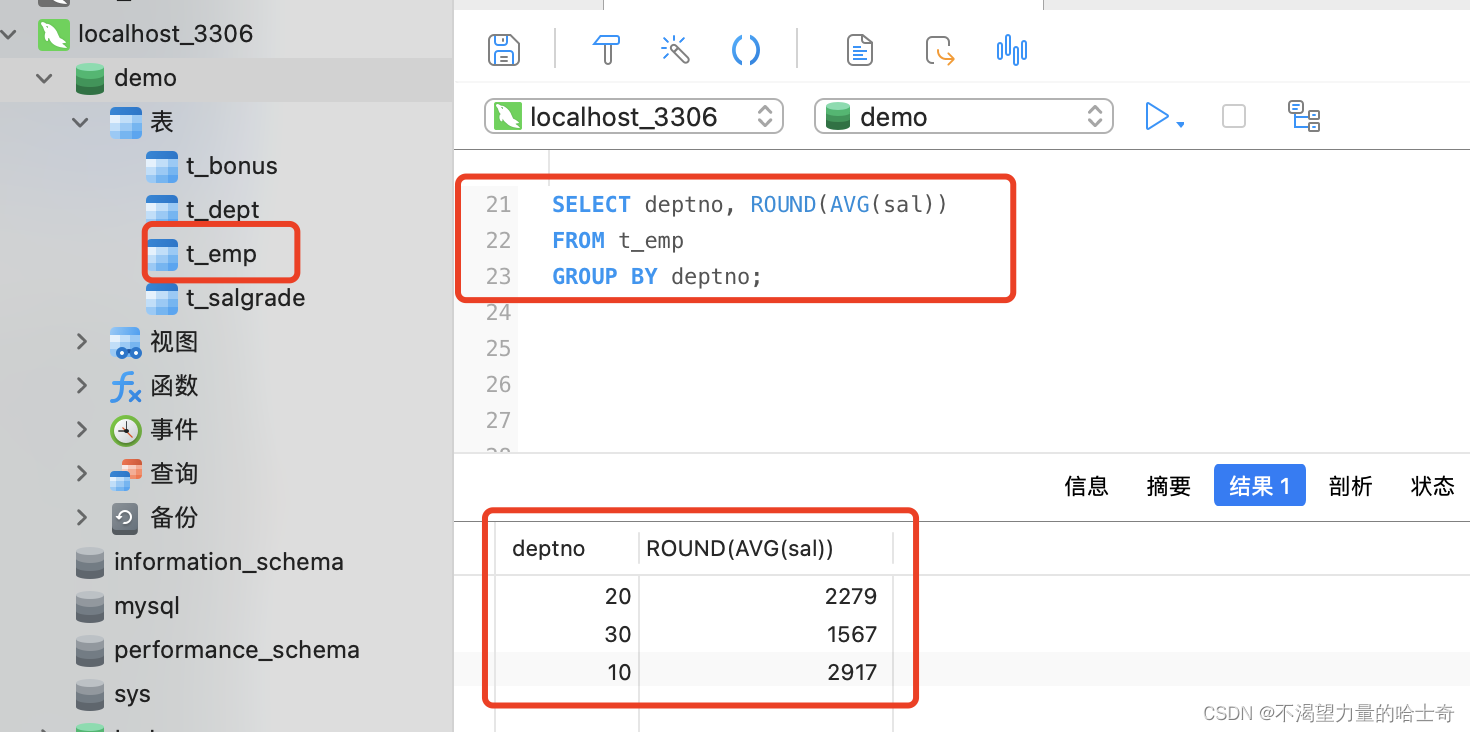
这里的小数,可能看着不太舒服,我们可以使用 ROUND() 函数将 平均工资四舍五入变成整数。
SELECT deptno, ROUND(AVG(sal)) FROM t_emp GROUP BY deptno;
逐级分组
有的时候仅有大的分组还不够,还需要在大的分组里面划分出晓得分组,然后再执行统计计算,于是就有了逐级分组。
什么是逐级分组? MySQL 数据库支持多列分组条件,执行的时候按照多列去依次执行,这就是逐级分组。
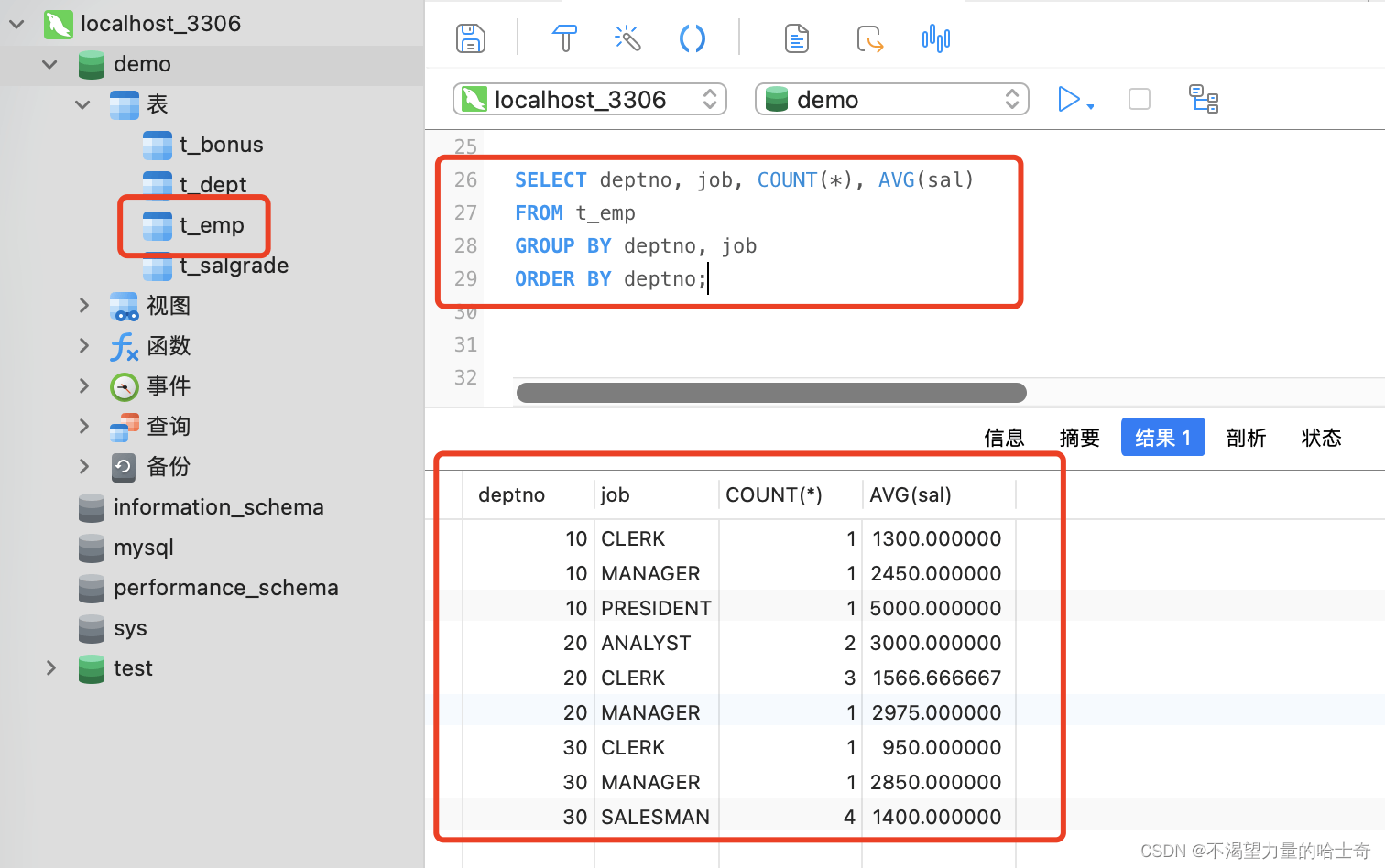
示例如下:(查询每个部门里,每种职位的人员数量和平均工资。)
SELECT deptno, job, COUNT(*), AVG(sal) FROM t_emp GROUP BY deptno, job ORDER BY deptno; -- 首先要按照部门对员工进行分组,在部门里,还要按照职务去分组; 就是 "GROUP BY deptno, job" -- 然后再用 聚合函数的 AVG 计算平均的月薪; 就是 "SELECT deptno, job, COUNT(*), AVG(sal)" -- 最后按照 deptno(部门编号) 排序,使用 ORDER BY 进行升序排序。
逐级分组对 SELECT 子句的要求
查询语句中如果包含有 “GROUP BY” 子句,那么 “SELECT” 子句中的内容就必须要遵守以下规定
"SELECT" 子句中可以包含聚合函数,或者 "GROUP BY" 子句的分组列,其余内容均不可以出现在 "SELECT" 子句中
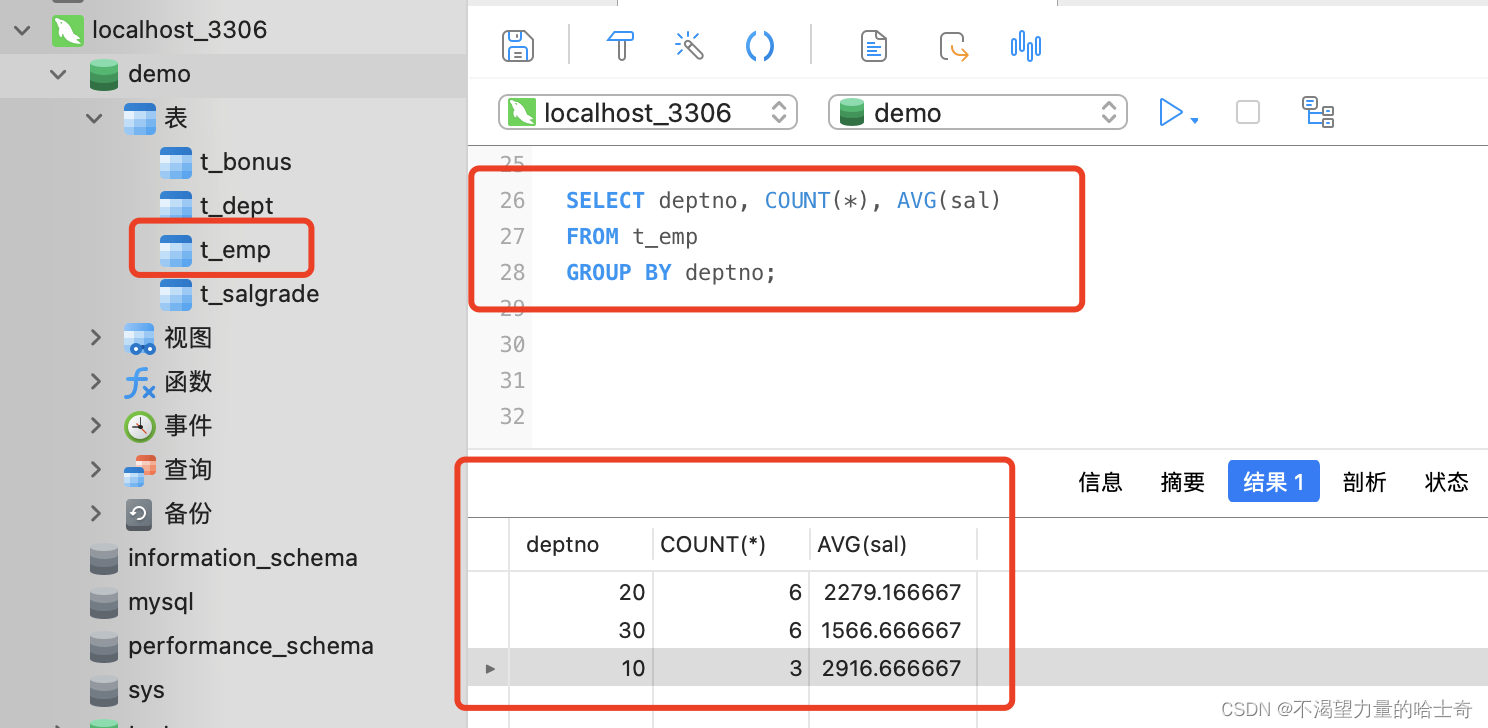
SQL 示例如下:(遵守规定示例)
SELECT deptno, COUNT(*), AVG(sal) FROM t_emp GROUP BY deptno;
SQL 示例如下:(不遵守规定示例)
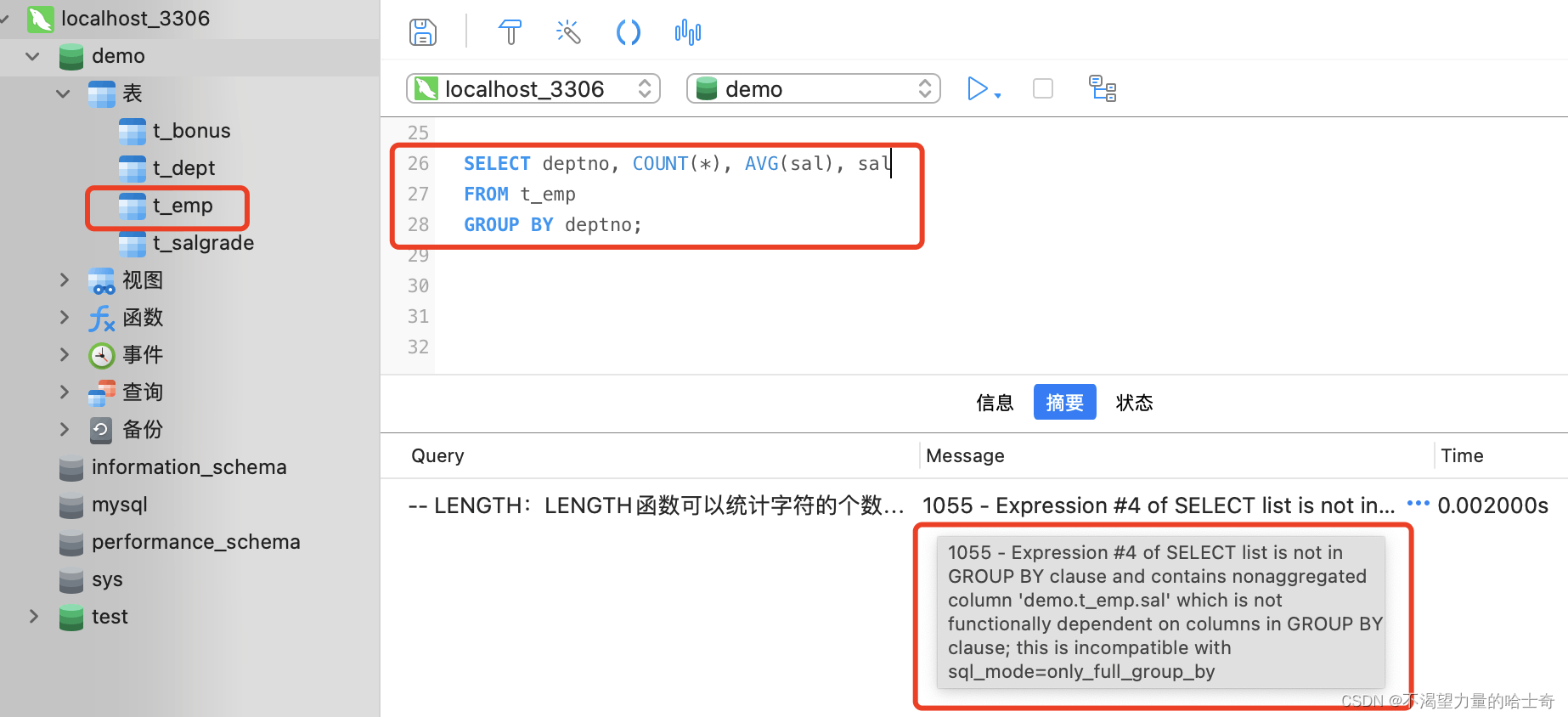
SELECT deptno, COUNT(*), AVG(sal), sal FROM t_emp GROUP BY deptno; -- 这条语句是无法执行成功的,因为在 "SELECT" 子句中,有一个 "sal" 的字段 -- 这个 "sal" 字段 没有在 GROUP BY 中去分组,本身也没有聚合函数,就是一个普通的字段 -- 造成无法执行、报错的原因是因为,"SELECT deptno, COUNT(*), AVG(sal), sal" -- 中的 "deptno、COUNT(*)、AVG(sal)" 返回的是 "GROUP BY" 一个结果集分组的同级信息; -- 而 "sal" 字段又是多条匹配记录,前后肯定是匹配不上的,所以这个 SQL 语句是无法执行成功的。 -- 同时因为标准的 SQL 规定,对表进行聚合查询的时候,只能在 SELECT 子句中写下面 3 种内容: -- 通过 GROUP BY 子句指定的聚合键、聚合函数(SUM 、AVG 等)、常量。 -- 所以在使用 SQL 语句记性数据表查询时,一定要严格遵守 SQL 的语法规定。
对分组结果集再次做汇总计算
来看一个示例:(查询 员工表中各个部门的人数,各个部门的平均月薪、最大月薪、最小月薪、按照员工号进行排序,并针对各个部门再次做一个汇总统计。)
SELECT deptno, COUNT(*), AVG(sal), MAX(sal), MIN(sal) FROM t_emp GROUP BY deptno WITH ROLLUP; -- 这里的 "WITH ROLLUP" 子句就是针对 "deptno"分组的结果集,再一次的进行汇总计算
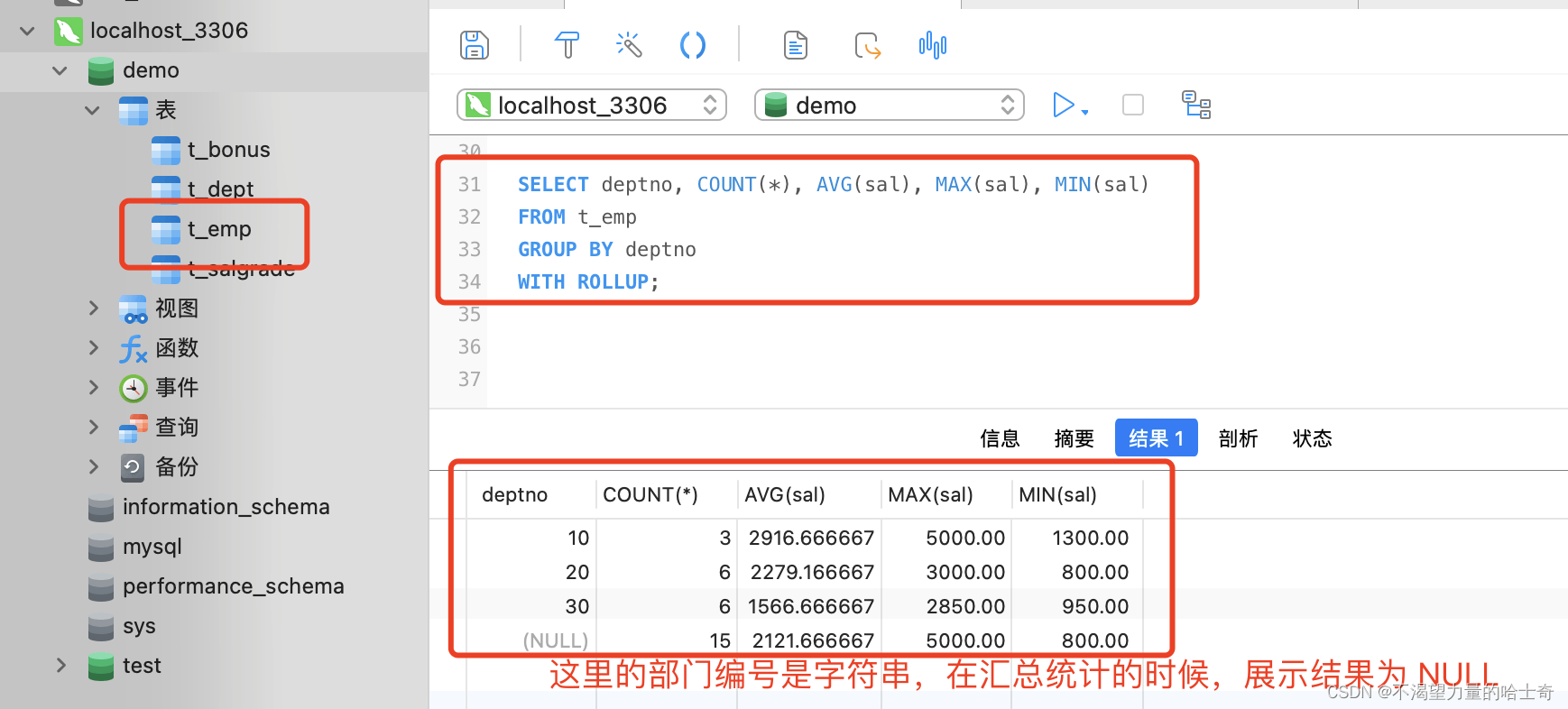
PS:该 SQL 语句主要是为了体现 "WITH ROLLUP" 关键字的效果,是对聚合函数的再次执行汇总计算。
GROUP_CONCAT 函数
上文中的 "逐级分组对 SELECT 子句的要求" 部分的时候解释了为什么会有这样的要求,就是聚合函数返回一条记录的结果与非分组字段的多条记录的结果无法匹配。
如果想要想要匹配,那就要把非分组的字段的多条记录转换成一条记录,MySQL 提供的 GROUP_CONCAT 函数就可以将分组查询中的非分组字段中的多条记录合并成一条记录。
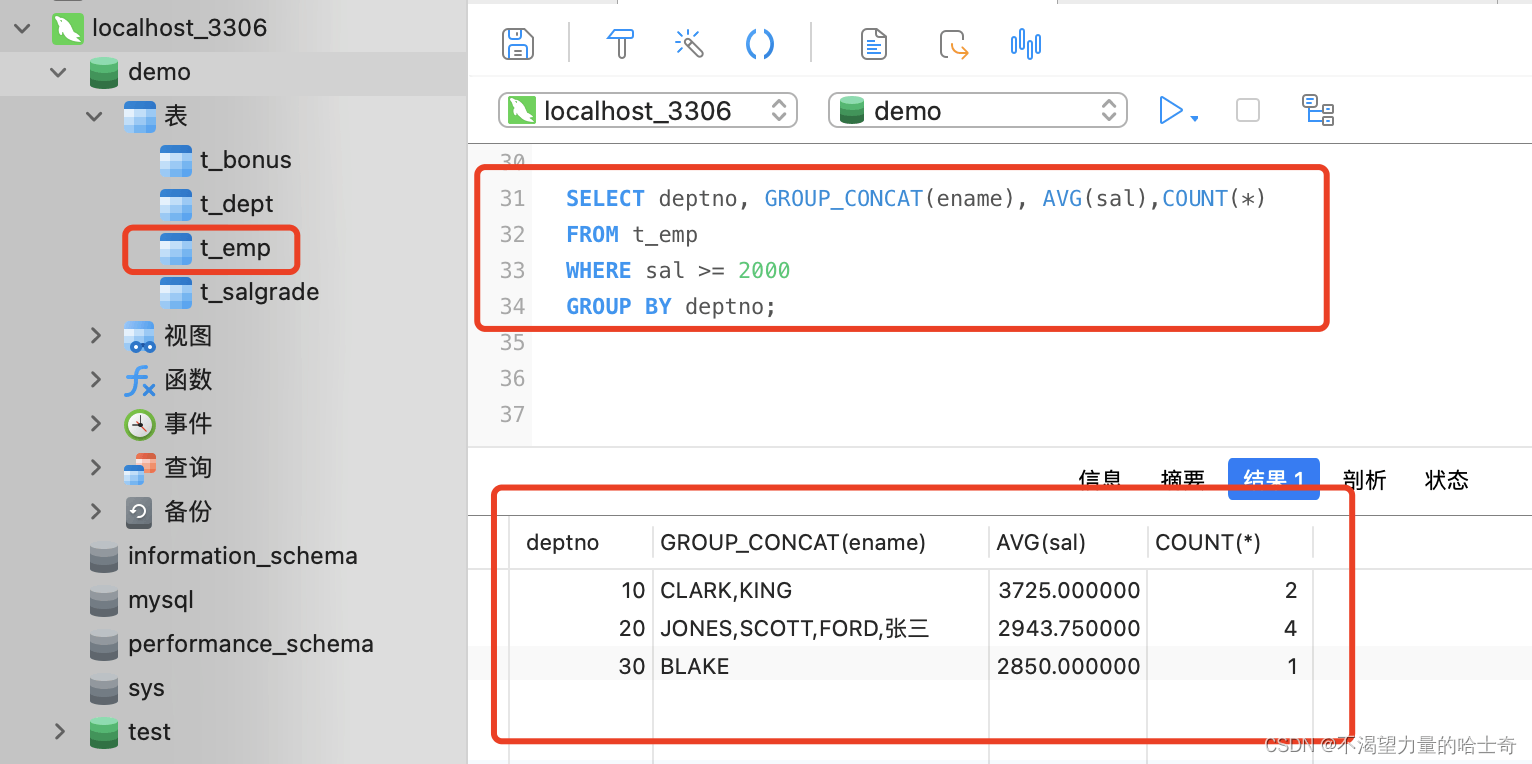
SQL 语句 "GROUP_CONCAT" 示例如下:(查询每个部门内底薪超过 2000元的人数和员工姓名,这里的员工姓名就是非分组的字段)
SELECT deptno, GROUP_CONCAT(ename), AVG(sal),COUNT(*) FROM t_emp WHERE sal >= 2000 GROUP BY deptno; -- 查询员工表,筛选条件为月薪大于等于 2000 ,以 "deptno" 为分组 -- "ename" 字段没有分组,但是我们使用 "GROUP_CONCAT" 函数将 "ename" 的多条返回记录转换为一条记录
GROUP BY 子句的执行顺序
截止到目前为止,我们所学习的所有子句,执行顺序如下:
FROM ---> WHERE ---> GROUP BY ---> SELECT ---> ORDER BY ---> LIMIT
到此这篇关于MySQL学习之分组查询的用法详解的文章就介绍到这了,更多相关MySQL分组查询内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文地址:https://blog.csdn.net/weixin_42250835/article/details/126025525
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









