
MySQL查询性能优化七种方式索引潜水

前言:
有读者可能会一脸懵?
啥是索引潜水?
你给起的名字的吗?有没有索引蛙泳?
这个名字还真不是我起的,今天要讲的知识点就叫索引潜水(Index dive) 。
先要从一件怪事说起:
我先造点数据复现一下问题,创建一张用户表:
?| 1 2 3 4 5 6 7 | CREATE TABLE ` user ` ( `id` bigint (20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID' , ` name ` varchar (100) NOT NULL DEFAULT '' COMMENT '姓名' , `age` int (11) NOT NULL DEFAULT 0 COMMENT '年龄' , PRIMARY KEY (`id`), KEY `idx_age` (`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; |
通过一批用户年龄,查询该年龄的用户信息,并查看一下SQL执行计划:
?| 1 2 | explain select * from user where age in (1,2,3,4,5,6,7,8,9); |

where条件中有9个参数,重点关注一下执行计划中的预估扫描行数为279行。
到这里没什么问题,预估的非常准,实际就是279行。
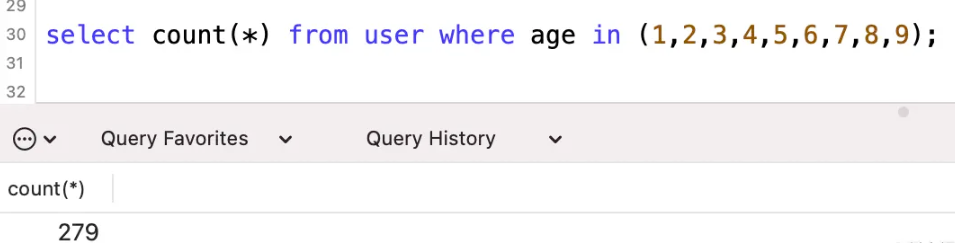
但是,问题来了,当我们在where条件中,再加一个参数,变成了10个参数,预估扫描行数本应该增加,结果却大大减少了。
?| 1 2 | explain select * from user where age in (1,2,3,4,5,6,7,8,9,10); |

一下子减少到了30行,可是实际行数是多少呢?
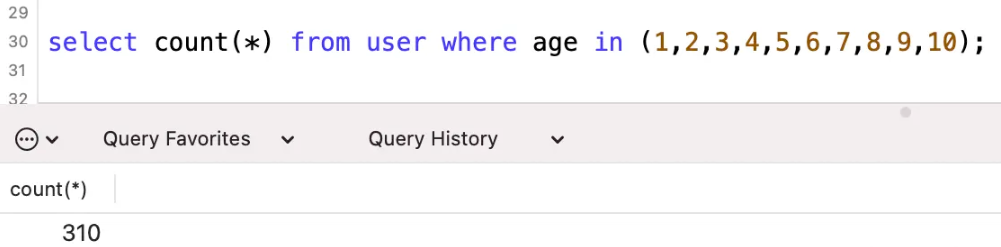
实际是310行,预估扫描行数是30行,真是错到姥姥家了。
MySQL咋回事啊,到底还能不能预估?
不能预估的话,换其他人!
大家肯定也是满脸疑惑,直到我去官网上看到了一个词语,索引潜水(Index dive) 。
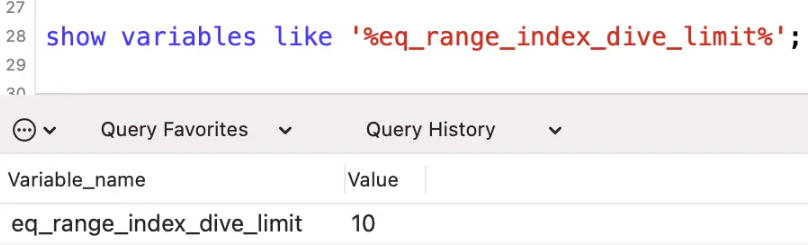
跟这个词语相关的,还有一个配置参数 eq_range_index_dive_limit。
MySQL5.7.3之前的版本,这个值默认是10,之后的版本,这个值默认是200。
可以使用命令查看一下这个值的大小:
?| 1 | show variables like '%eq_range_index_dive_limit%' ; |
当然,我们也可以手动修改这个值的大小:
?| 1 | set eq_range_index_dive_limit=200; |
这个 eq_range_index_dive_limit 配置的作用就是:
当where语句in条件中参数个数小于这个值的时候,MySQL就采用索引潜水(Index dive) 的方式预估扫描行数,非常准确。
当where语句in条件中参数个数大于等于这个值的时候,MySQL就采用另一种方式索引统计(Index statistics) 预估扫描行数,误差较大。
MySQL为什么要这么做呢?
都用索引潜水(Index dive) 的方式预估扫描行数,不好吗?
其实这是基于成本的考虑,索引潜水估算成本较高,适合小数据量。索引统计估算成本较低,适合大数据量。
一般情况下,我们的where语句的in条件的参数不会太多,适合使用索引潜水预估扫描行数。
建议还在使用MySQL5.7.3之前版本的同学们,手动修改一下索引潜水的配置参数,改成合适的数值。
如果你们项目中in条件最多有500个参数,就把配置参数改成501。
这样MySQL预估扫描行数更准确,可以选择更合适的索引。
到此这篇关于MySQL查询性能优化七种方式索引潜水的文章就介绍到这了,更多相关MySQL查询优化内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://juejin.cn/post/7128043063661821966
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








