
MySQL索引事务详细解析

一、索引
1.概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针,可以对表中的一列或者多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现. (这里对于索引也只是简单了解,写了些皮毛) 更浅显易懂的来说:数据库的数据保存在硬盘,硬盘不知道具体保存在哪个位置,索引就是用来告诉硬盘数据在哪个位置.
2.作用
数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系 索引所起的作用类似书籍目录,可用于快速定位,检索数据 索引对于提高数据库的性能有很大的帮助
说明:某张表可以给一个字段或多个字段创建索引
使用查询语句时,根据索引字段来做条件查询就可能使用到索引,提高查询速度.
某些语句不能使用到索引,比如:
student(id,name,email),name创建索引
where name like ‘%哈哈%’ 和 name is null 不能使用索引
name=‘张三’ 能使用到
3.缺陷
索引需要占用一定的磁盘空间,插入/修改/删除操作,索引也需要更新,数据量越大,索引更新的时间越长 所以说:也不是索引建的越多越好
4.使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
- 数据量较大,且经常对这些列进行条件查询
- 该数据库表的插入操作,及对这些列的修改操作频率较低
- 索引会占用额外的磁盘空间
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率
反之,如果非条件查询列,或经常做插入,修改操作,或磁盘空间不足时,不考虑创建索引
5.使用
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FORGIGN KEY)时,会主动创建对应列的索引.
1.查看索引
show index from 表名;
2.创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引
create index 索引名 on 表名(字段名);
3.删除索引
drop index 索引名 on 表名;
6.案例
实现登录功能,数据库有user表,username(账号),password(密码)
从实现上看:
页面上,用户输入账号密码,Java程序接收到这个账号,这个密码数据库sql的实现,就有两种方式:
(1)根据账号+密码,条件查询
(2)根据账号查询,Java程序获取到这条数据,比较/校验密码
问题:登录功能发现很慢,如何优化?
如果sql是第一种查询方式,创建账号+密码两个字段的索引
第二种查询方式,创建账号一个字段的索引
二、事务
1.为什么使用事务
准备测试表:
?| 1 2 3 4 5 6 7 8 9 | drop table if exists accout; create table accout( id int primary key auto_increment, name varchar (20) comment '账户名称' , money decimal (11,2) comment '金额' ); insert into accout( name , money) values ( '图图' , 5000), ( '小美' , 1000); |
比如说,小美向图图借了2000元
?| 1 2 3 4 | -- 图图账户减少2000 update accout set money=money-2000 where name = '图图' ; -- 小美账户增加2000 update accout set money=money+2000 where name = '小美' ; |
假如在执行以上第一句SQL时,出现网络错误,或是数据库挂掉了,图图的账户会减少2000,但是小美的账户上就没有了增加的金额 解决方案: 使用事务来控制,保证以上两句SQL要么全部执行成功,要么全部执行失败.
2.事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败. 在不同的环境中,都可以有事务.对应在数据库中,就是数据库事务.
3.使用
(1)开启事务:start transaction;
(2)执行多条SQL语句
(3)回滚或提交:rollback/commit
说明:rollback即是全部失败,commit即是全部成功
?| 1 2 3 4 5 6 | start transaction ; -- 图图账户减少2000 update accout set money=money-2000 where name = '图图' ; -- 小美账户增加2000 update accout set money=money+2000 where name = '小美' ; commit ; |
4.特性
存在acid四大特性(原子性,持久性,一致性,隔离性)
1.原子性:对应一组操作(主要是更新),要么全部成功,要么全部失败
2.一致性:一个事务里边,多次查询到的数据都是一样的
3.隔离性:不同事务,查询/修改的数据,是互相隔离开的 一个事务,没有提交或者回滚前,修改的数据,只有自己看得到
4.持久性:事务提交,会持久化到硬盘中
关于第三点和第四点这里做出图像解释:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | mysql> drop table if exists accout; mysql> create table accout( -> id int primary key auto_increment, -> name varchar (20) comment '账户名称' , -> money decimal (11,2) comment '金额' -> ); mysql> insert into accout( name , money) values -> ( '图图' , 5000), -> ( '小美' ,1000); mysql> update accout set money=money-2000 where name = '图图' ; mysql> update accout set money=money+2000 where name = '小美' ; |
在MySQL中执行上述操作之后没有进行commit结果显示为:
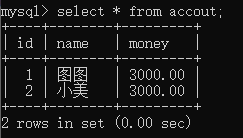
但是在客户端连接MySQL服务器直接查看表格数据并没有变化:
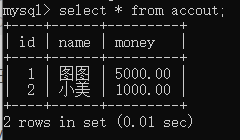
只有在commit完成之后才会客户端才会显示:

到此这篇关于MySQL索引事务详细解析的文章就介绍到这了,更多相关MySQL 索引事务内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.csdn.net/m0_51405559/article/details/122201172
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









