
解析MySQL join查询的原理

MySQL用Nested-Loop Join算法实现join查询
区分驱动表和被驱动表,以驱动表的结果集为循环的基础,访问被驱动表过滤数据,然后合并结果,驱动表在外循环、被驱动表在内循环。
如果还有第三张参与join查询的表,则以合并的结果为驱动表,第三张表作为被驱动表,以此类推。
left join中的左表是驱动表、右表是被驱动表,right join刚好相反。
Nested-Loop Join有三种实现
SNLJ
Simple Nested-Loop Join
假设A是驱动表,B是被驱动表。
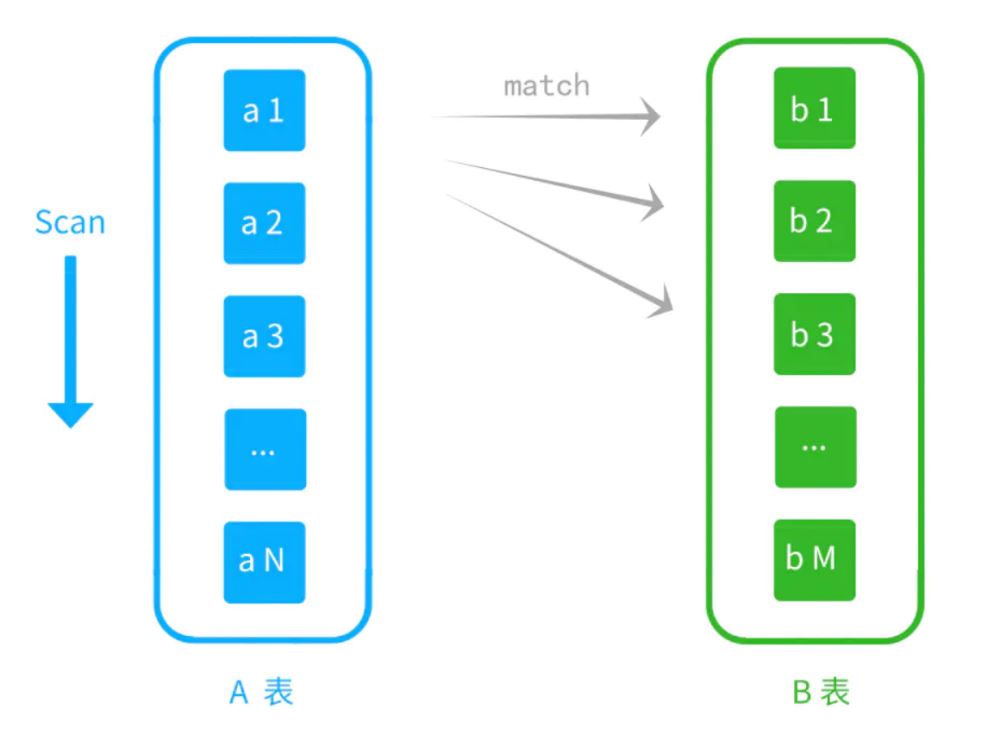
这里会扫描A表,用A的结果集作为外循环,
每循环一次,会扫描B表一遍(遍历内循环)
A表有N行,B表有M行。
SNLJ的开销如下(最大情况下):
扫描A表1次;
扫描B表N次。
总共读取记录数:N + N * M。
为了专注于理解Nested-Loop Join,这里不讨论带where子句的情况,以下相同。
BNLJ
Block Nested-Loop Join
假设A是驱动表,B是被驱动表。
用来join的字段在被驱动表没有建立索引
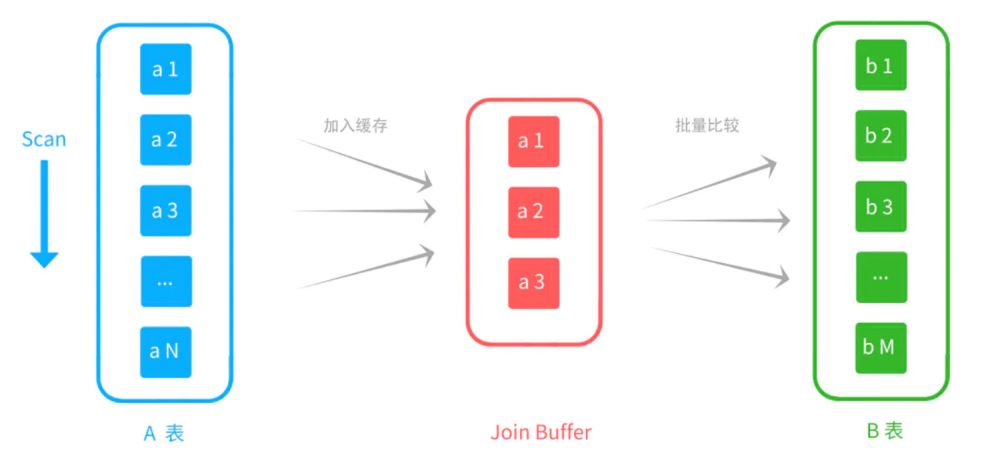
Join Buffer
MySQL会将驱动表结果集中(多条记录)用来join的字段缓存到Join Buffer,
Join Buffer的特点是只需要扫描被驱动表一次,就能得到Join Buffer中所有记录的匹配结果,
减少扫描的次数。
Join Buffer默认大小256k,会生成n-1个Join Buffer缓冲区,n为参与join查询的表数量。
A表有N行,B表有M行。
BNLJ的开销如下(最大情况下):
扫描A表1次;
扫描B表X次;
X的大小取决于N、join字段的大小、Join Buffer的大小,通常X<<N。
INLJ
Index Nested-Loop Join
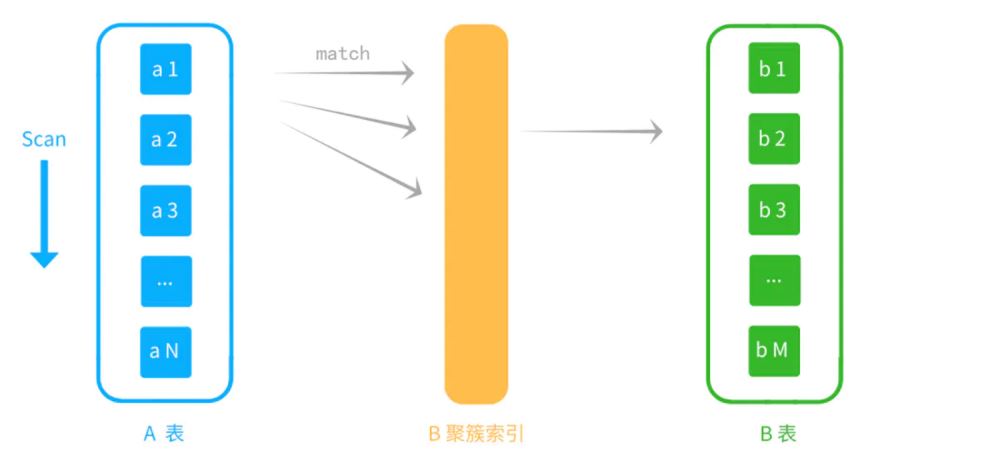
假设A是驱动表,B是被驱动表。
用来join的字段在被驱动表建立了索引
聚集索引
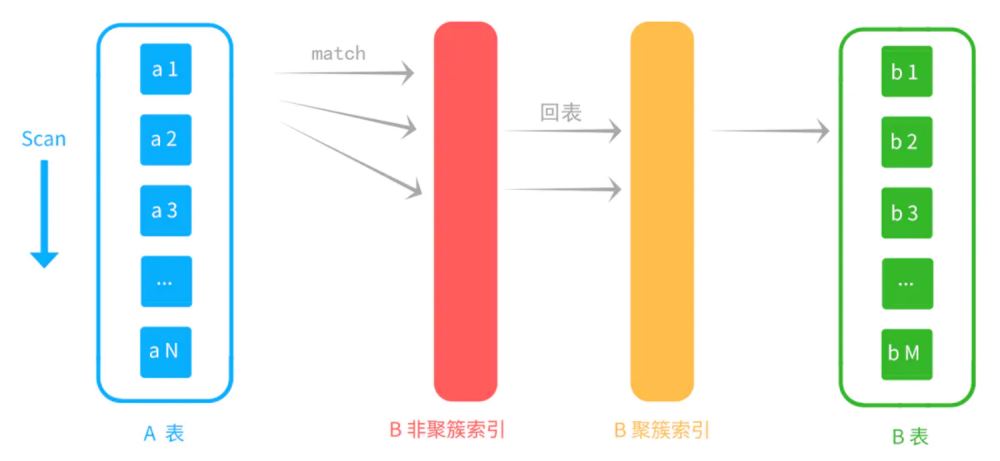
非聚集索引
在这里我们假设您已对MySQL的索引结构有了一定的了解,
如果没有的话,可以去看下:通过B+Tree平衡多叉树理解InnoDB引擎的聚集和非聚集索引
这里会扫描A表,用A的结果集作为外循环,
然后通过B表的索引来检索,不会遍历B表。
A表有N行,B表有M行。
INLJ的开销如下(最大情况下):
扫描A表1次;
通过B表索引检索N次,成本比扫描B表N次会低很多;
回表:先找到非聚集索引,再找到聚集索引,会多一次磁盘IO。
NLJ优先级
INLJ>BNLJ>SNLJ
如何优化join查询效率
尽量将小表作为驱动表,大表作为被驱动表;
为参加join的字段在被驱动表建立聚集索引,其次是非聚集索引;
尽可能减少join的字段数量,或者使用长度比较小的字段来join,这样Join Buffer一次可以缓存更多条记录。
inner join时,MySQL会自动将小表作为驱动表,大表作为被驱动表。
扫描整张表是成本非常高的操作。
到此这篇关于MySQL join查询的原理的文章就介绍到这了,更多相关MySQL join查询内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.csdn.net/qq_35549286/article/details/122690332
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








