
MySQL使用索引优化性能

1.索引问题
索引是数据库优化中最常用也是最重要的手段之一,通过索引通常可以帮助用户解决大多数 的SQL性能问题。本章节将对MySQL中的索引的分类、存储、使用方法做详细的介绍。
2.索引的存储分类
MyISAM存储引擎的表数据和索引是自动分开存储的,各自是独立的一个文件;InnoDB存储引擎的表数据和索引是存储在同一个表空间里面,但可以有多个文件组成。MySQL中索引的存储类型目前只有两种(BTREE和HASH),具体和表的存储引擎相关:MyISAM和InnoDB存储引擎都只支持BTREE索引;MEMORY/HEAP存储引擎可以支持HASH和BTREE索引。MySQL目前不支持函数索引,但是能对列的前面某一部分进索引,例如上章节库存表goods_stock.LotNO批次字段,可以只取Model的前4个字符进行索引,这个特性可以大大缩小索引文件的大小,我们在设计表结构的时候也可以对文本列根据此特性进行灵活设计。下面是创建前缀索引的一个例子:
?| 1 | EXPLAIN SELECT * FROM goods_stock WHERE LotNO LIKE '2021%' ; |

| 1 2 | -- 创建前缀索引 CREATE INDEX idx_stock_2 ON goods_stock (LotNO(4)); |

3.如何使用索引
索引用于快速找出在某个列中有一特定值的行。对相关列使用索引是提高SELECT操作性能的最佳途径。查询要使用索引最主要的条件是查询条件中需要使用索引关键字,如果是多列索引,那么只有查询条件使用了多列关键字最左边的前缀时,才可以使用索引,否则将不能使用索引。
3.1使用索引
在MySQL中,下列几种情况下有可能使用到索引。
对于创建的多列索引,只要查询的条件中用到了最左边的列,索引一般就会被使用, 举例说明如下:
?| 1 2 | -- 首先在库存表goods_stock按Model,Brand的顺序创建一个复合索引 CREATE INDEX idx_stock_1 ON goods_stock (Model,Brand); |
然后按Model进行表查询,具体命令如下:
?| 1 | EXPLAIN SELECT * FROM goods_stock WHERE Model= 'LM358DT' ; |

可以发现即便where条件中不是用Model与Brand字段的组合条件,索引仍然能用到,这就是索引的前缀特性(按照索引列顺序查询)。但是如果只按Brand条件查询表,那么索引就不会被用到,具体如下:
?| 1 | EXPLAIN SELECT * FROM goods_stock WHERE Brand= 'TI' ; |

对于使用like的查询,后面如果是常量并且只有%号不在第一个字符,索引才可能会被使用,来看下面两个执行计划:
?| 1 | EXPLAIN SELECT * FROM goods_stock WHERE Model LIKE '%LM358' ; |

| 1 | EXPLAIN SELECT * FROM goods_stock WHERE Model LIKE 'LM358%' ; |

可以发现第一个SQL没有使用索引,而第二个SQL就能够使用索引,区别就在于“%”的位置不同,前者把“%”放到第一位就不能用到索引,而后者没有放到第一位就使用了索引。另外,如果如果like后面跟的是一个列的名字,那么索引也不会被使用。如果对大的文本进行搜索,使用全文索引而不要使用like ‘%...%’。
如果列名是索引,使用column_name is null时候将会使用索引。如下例中查询LotNO为null的记录时候就会用到索引:
?| 1 | EXPLAIN SELECT * FROM goods_stock WHERE LotNO IS NULL ; |

3.2存在索引但不使用索引
在下列情况下,虽然存在索引,但是MySQL并不会使用相应的索引。
如果MySQL估计使用索引比全表扫描更慢,则不使用索引。例如如果列 key_part1 均匀分布在 1 和 100 之间,下列查询中使用索引就不是很好:
?| 1 | SELECT * FROM table_name where key_part1 > 1 and key_part1 < 90; |
如果使用MEMORY/HEAP表并且where条件中不使用“=”进行索引列,那么不会用到索引。HEAP表只有在“=”的条件下才会使用索引。
用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及到的索引都不会被用到,例如:
| 1 | SHOW INDEX FROM goods_stock; |

通过命令可以看到goods_stock库存表有两个索引,然后我们再执行如下语句看是否使用索引:
?| 1 | EXPLAIN SELECT * FROM goods_stock WHERE LotNO= '20200821' OR PackageUnit= '包' ; |

可见虽然在LotNO这个列上存在索引idx_stock_2,但是这个SQL语句并没有用到这个索引,原因就是or中有一个条件中的列没有索引。
如果列类型是字符串,那么一定记得在where条件中把字符常量值用引号引起来,否则即便这个列上有索引,MySQL也不会用到的,因为MySQL默认把输入的常量值进行转换以后才进行检索,请看如下例子:
?| 1 | DESC goods_stock; |
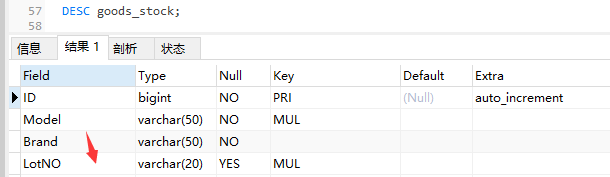
通过DESC命令我们可以看到goods_stock库存表中的LotNO字段是字符型,如果我们在SQL语句中的LotNO字段加入一个数值型为20200821的条件值,因此即便在LotNO上有索引,MySQL也不能正确地用上索引,而是继续进行全表扫描,具体如下:
?| 1 | EXPLAIN SELECT * FROM goods_stock WHERE LotNO=20200821; |

4.查看索引使用情况
如果索引正在工作,Handler_read_key的值将很高,这个值代表了一个行被索引值读的次数,很低的值表明增加索引得到的性能改善不高,因为索引并不经常使用。Handler_read_rnd_next的值高则意味着查询运行低效,并且应该建立索引补救。这个值的含义是在数据文件中读下一行的请求数。如果正进行大量的表扫描,Handler_read_rnd_next的值较高,则通常说明表索引不正确或写入的查询没有利用索引。可以先刷新状态再查询,具体如下:
?| 1 2 | FLUSH STATUS; SHOW STATUS LIKE 'Handler_read%' ; |
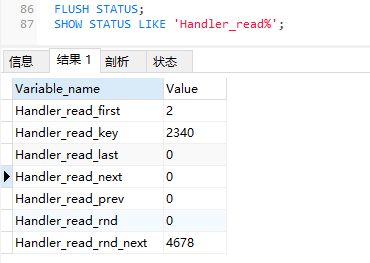
参数解释如下:
- Handler_read_first:此选项表明SQL是在做一个全索引扫描,注意是全部,而不是部分,所以说如果存在WHERE语句,这个选项是不会变的。
- Handler_read_key:此选项数值如果很高,MySQL高效的使用了索引,一切运转良好。
- Handler_read_next:此选项表明在进行索引扫描时,按照索引从数据文件里取数据的次数。
- Handler_read_prev:此选项表明在进行索引扫描时,按照索引倒序从数据文件里取数据的次数,一般就是ORDER BY … DESC。
- Handler_read_rnd:就是查询直接操作了数据文件,很多时候表现为没有使用索引或者文件排序。
- Handler_read_rnd_next:此选项值较高时候,则通常说明表索引不正确或写入的查询没有利用索引。
5.两个简单实用的优化方法
对于大多数开发人员来说,可能只希望掌握一些简单实用的优化方法,对于更多更复杂的优化,更倾向于交给专业DBA来做。本小节将向大家介绍两个简单适用的优化方法。
5.1定期分析表和检查表
分析表的语法如下:
?| 1 | ANALYZE [ LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... |
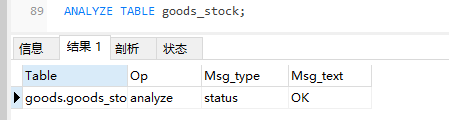
本语句用于分析和存储表的关键字分布,分析的结果将可以使得系统得到准确的统计信息,使得SQL能够生成正确的执行计划。如果用户感觉实际执行计划并不是预期的执行计划,执行一次分析表可能会解决问题。在分析期间,使用一个读取锁定对表进行锁定。这对于MyISAM, BDB和InnoDB表有作用。对于MyISAM表,本语句与使用myisamchk -a相当,下例中对goods_stock表做了表分析:
?| 1 | ANALYZE TABLE goods_stock; |
检查表的语法如下:
?| 1 | CHECK TABLE tbl_name [, tbl_name] ... [ option ] ... option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED} |
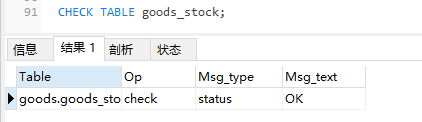
检查表的作用是检查一个或多个表是否有错误。CHECK TABLE对MyISAM和InnoDB表有作用。对于MyISAM表,关键字统计数据被更新,例如:
?| 1 | CHECK TABLE goods_stock; |
CHECK TABLE也可以检查视图是否有错误,比如在视图定义中被引用的表已不存在,举例如下:
(1)首先我们创建一个表。
?| 1 2 3 4 | CREATE TABLE test ( ID INT (11) ); |
(2)再创建一个视图。
?| 1 | CREATE VIEW test_view AS SELECT * FROM test; |
(3)然后CHECK一下该视图,发现没有问题。
?| 1 | CHECK TABLE test_view; |
(4)现在删除掉视图依赖的表。
?| 1 | DROP TABLE test; |
(5)再来CHECK一下刚才的视图,发现报错了。
?| 1 | CHECK TABLE test_view; |

5.2定期优化表
优化表的语法如下:
?| 1 | OPTIMIZE [ LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... |
如果已经删除了表的一大部分,或者如果已经对含有可变长度行的表(含有VARCHAR、BLOB或TEXT列的表)进行了很多更改,则应使用OPTIMIZE TABLE 命令来进行表优化。这个命令可以将表中的空间碎片进行合并,并且可以消除由于删除或者更新造成的空间浪费,但OPTIMIZE TABLE命令只对MyISAM、BDB和InnoDB表起作用。以下例子显示了优化goods_stock库存表的过程:
?| 1 2 | -- 先查看下goods_stock库存表是什么表类型 SHOW TABLE STATUS LIKE 'goods_stock%' ; |

| 1 | OPTIMIZE TABLE goods_stock; |

注意:ANALYZE、CHECK、OPTIMIZE执行期间将对表进行锁定,因此一定注意要在数据库不繁忙的情况下执行相关的操作。
到此这篇关于MySQL使用索引优化性能的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持服务器之家。
原文链接:https://www.cnblogs.com/wzk153/p/14545621.html
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








