
全面解析MySQL中的隔离级别

数据库并发的对同一批数据进行增删改,就可能会出现我们所说的脏写、脏读、不可重复读、幻读等一系列问题。MySQL提供了一系列机制来解决事务并发问题,比如事务隔离、锁机制、MVCC多版本并发控制机制。今天来探究一下事务隔离机制。
事务是一组SQL组成的逻辑处理单元,先来看下事务的ACID特性:
- 原子性(Atomicity) :事务是一个原子操作单元,对数据进行修改,要么全执行要么全不执行。是从执行层面上来描述的。
- 一致性(Consistent) :在事务开始和完成时,数据都必须保持一致状态。是从执行结果层面上来描述的。
- 隔离性(Isolation) :数据库系统提供一定的隔离机制,保证事务执行过程中对外部不可见,独立运行,不受外部影响。
- 持久性(Durable) :事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
并发事务的影响:
- 脏写(更新丢失:Lost Update):多个事务选择了同一行,彼此不知道对方存在,会覆盖之前事务的数据操作。
- 脏读(Dirty Reads):A事务读取了B事务未提交的数据,B事务回滚,A提交,最终结果不符合一致性原则
- 不可重读(Non-Repeatable Reads):同一个事务,相同的查询语句,执行多次结果不一致,可能是外部事务修改导致的,不符合隔离性。
- 幻读(Phantom Reads):事务A读取到了事务B提交的新增数据,不符合隔离性
事务隔离级别:
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) |
| 读未提交(Read uncommitted) | 可能 | 可能 | 可能 |
| 读已提交(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable Read) | 不可能 | 不可能 | 可能 |
| 串行化(Serializable) | 不可能 | 不可能 | 不可能 |
MySQL提供了上面四种隔离级别,隔离越严格,可能出现的问题就越少,但付出的性能代价就越大,默认的隔离级别是可重复读。下面使用客户端进行操作进行验证。
先加创建一张表和数据
?| 1 2 3 4 5 6 7 8 9 10 11 | CREATE TABLE `account` ( `id` int (11) unsigned NOT NULL AUTO_INCREMENT, `balance` int (11) DEFAULT NULL , PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; INSERT INTO `account` (`id`, `balance`) VALUES (1, 500), (2, 600), (3, 200); |
连接客户端,查看隔离级别,可以看到是可重复读:
?| 1 2 3 4 5 6 | MySQL [test]> show variables like 'tx_isolation' ; + ---------------+-----------------+ | Variable_name | Value | + ---------------+-----------------+ | tx_isolation | REPEATABLE - READ | + ---------------+-----------------+ |
读未提交测试:
AB客户端都执行set tx_isolation='read-uncommitted';设置隔离级别为读未提交。
A客户端开启事务:start transaction;查询数据:select * from account;
B客户端开启事务:start transaction;更新数据:update account set balance = balance - 100 where id = 1;此时事务未提交
A客户端再次查询数据:select * from account; 此时看到两次查询的数据已经不一样了
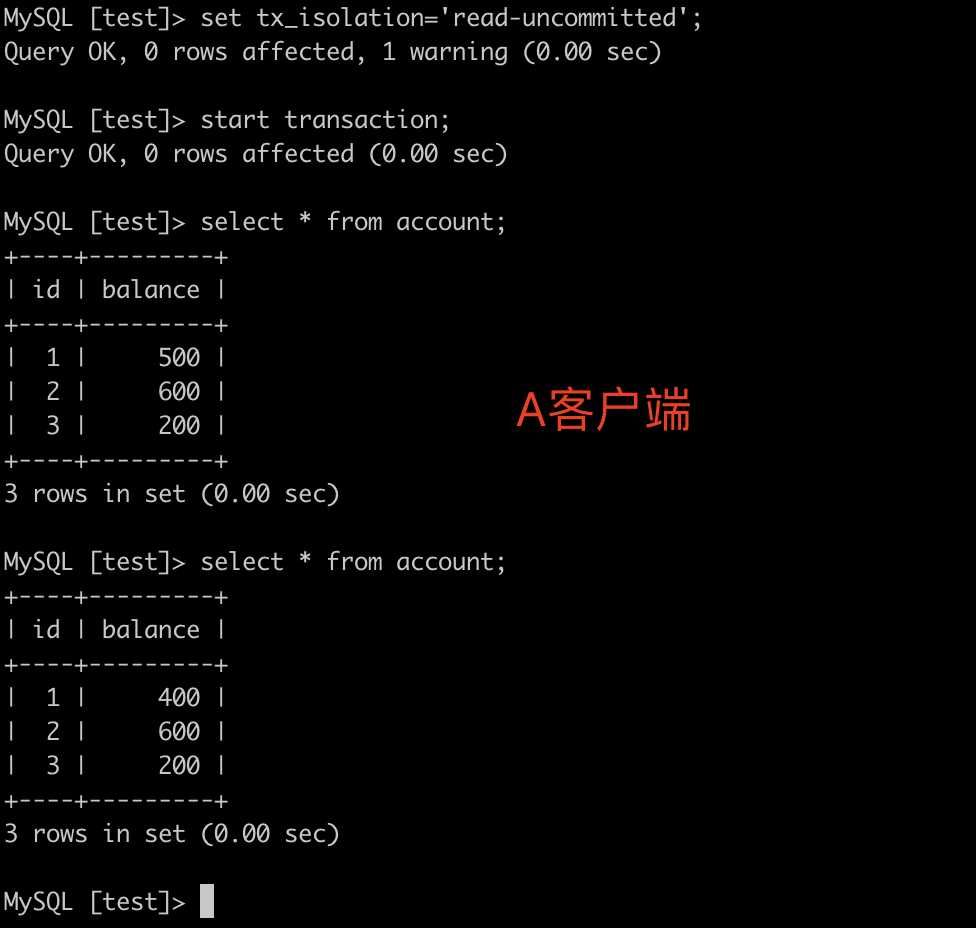
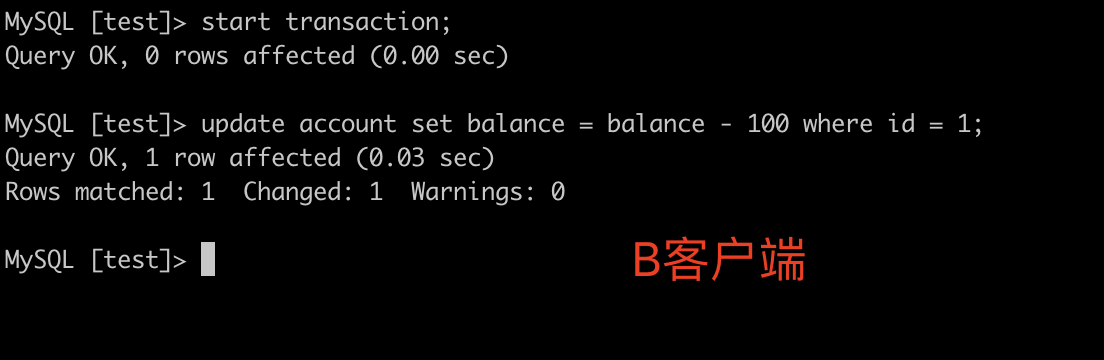
在B没提交前A就读到了B更新的数据,此时如果B回滚,那么A那边就是脏数据。这种情况就是读未提交造成的脏读。用读已提交隔离级别可以解决。
使用commit命令把AB客户端的事务提交。
读已提交测试:
AB客户端都执行 set tx_isolation='read-committed'; 设置隔离级别为读已提交。
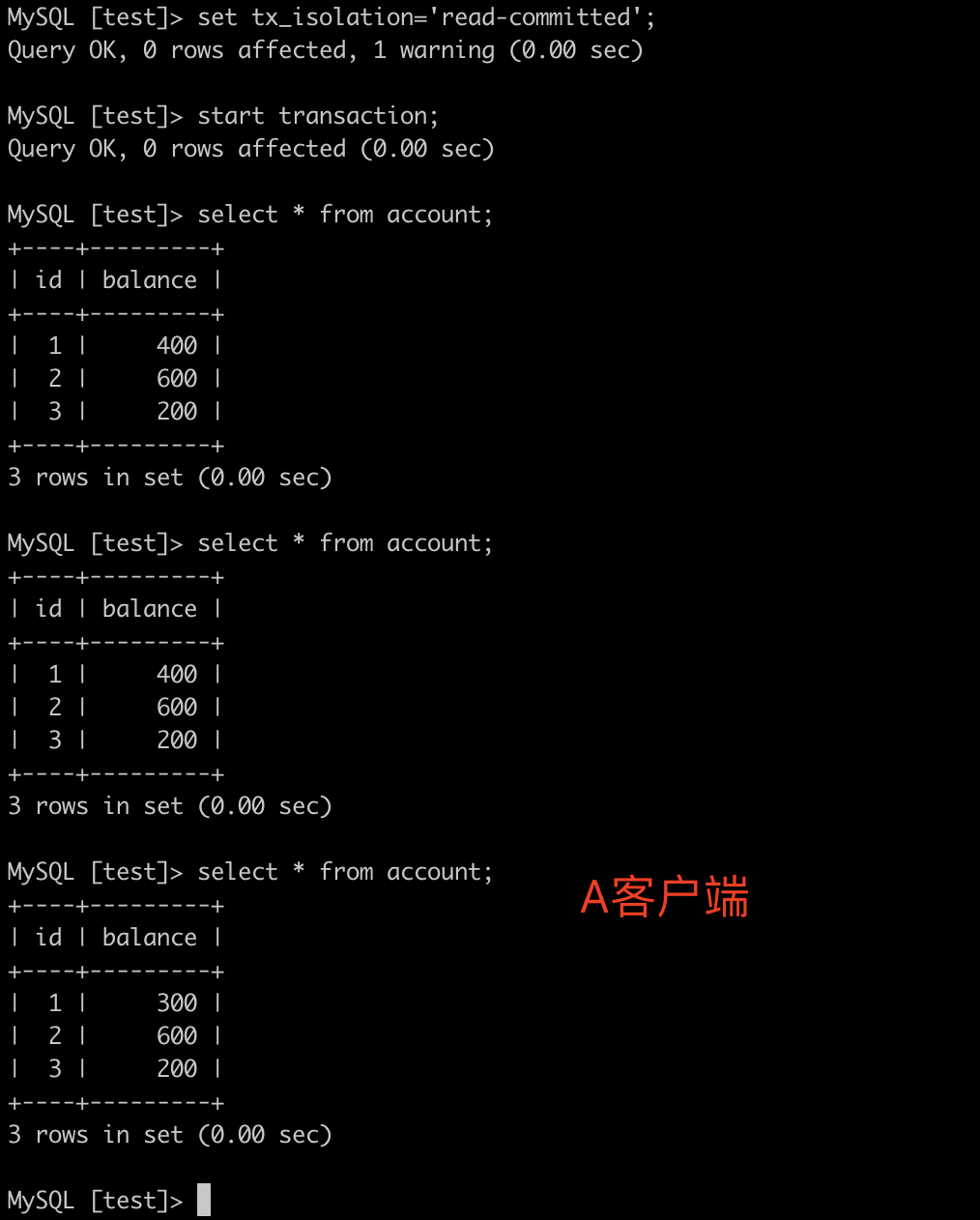
A客户端开启事务:start transaction;查询数据:select * from account;
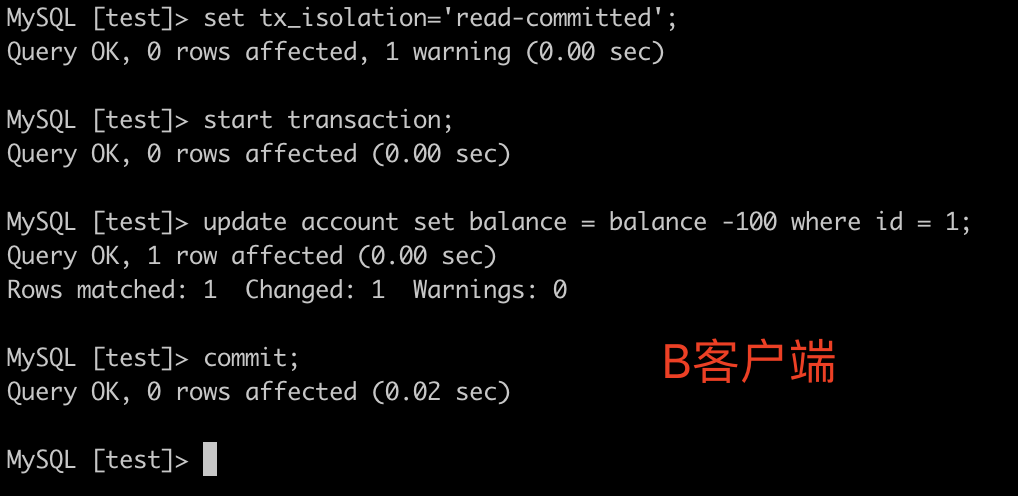
B客户端开启事务:start transaction;更新数据:update account set balance = balance - 100 where id = 1;此时事务未提交
A客户端再次查询数据:select * from account; 此时看到A客户端两次查询数据一致,未出现脏读情况
此时B客户端事务提交:commit;
A客户端再次查询数据:select * from account; 此时看到A客户端查询数据已经发生了变化,这就是不可重复读。
可重复读测试:
AB客户端都执行 set tx_isolation='repeatable-read'; 设置隔离级别为可重复读。
A客户端开启事务:start transaction;查询数据:select * from account;
B客户端开启事务:start transaction;更新数据:update account set balance = balance - 100 where id = 1; commit提交事务
A客户端再次查询数据:select * from account; 此时看到A客户端两次查询数据一致,重复读取数据一致。
A客户端执行更新语句:update account set balance = balance - 50 where id = 1;
A客户端再次查询数据:select * from account; 此时看到id=1的这条数据是B客户端更新之后的数据-50,数据的一致性没有被破坏
B客户端重新开启事务,插入一条数据:insert into account(id,balance) values (4,1000); commit提交事务;
A客户端查询,和上次结果一致
A客户端执行:update account set balance = balance - 100 where id = 4; 更新B客户端新插入的数据,能执行成功,再次查询所有数据,能插到id=4的数据,出现幻读。
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | # A客户端执行过程:# 设置隔离级别可重复度MySQL [test]> set tx_isolation= 'repeatable-read' ; Query OK, 0 rows affected, 1 warning (0.00 sec) # 开启事务 MySQL [test]> start transaction ; Query OK, 0 rows affected (0.00 sec) # 查询所有数据 MySQL [test]> select * from account; + ----+---------+ | id | balance | + ----+---------+ | 1 | 300 | | 2 | 600 | | 3 | 200 | + ----+---------+ 3 rows in set (0.00 sec) # 再次查询验证两次结果是否一致 MySQL [test]> select * from account; + ----+---------+ | id | balance | + ----+---------+ | 1 | 300 | | 2 | 600 | | 3 | 200 | + ----+---------+ 3 rows in set (0.00 sec) # 在B客户端插入数据之后,此次A客户端不能查询到 MySQL [test]> select * from account; + ----+---------+ | id | balance | + ----+---------+ | 1 | 150 | | 2 | 600 | | 3 | 200 | + ----+---------+ 3 rows in set (0.00 sec) # A客户端更新B客户端插入的数据,发现可以更新成功 MySQL [test]> update account set balance = balance + 1000 where id = 4; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 # 再次查询,能查询到数据,出现幻读 MySQL [test]> select * from account; + ----+---------+ | id | balance | + ----+---------+ | 1 | 400 | | 2 | 600 | | 3 | 200 | | 4 | 2000 | + ----+---------+ 4 rows in set (0.00 sec) # 提交事务 MySQL [test]> commit ; Query OK, 0 rows affected (0.01 sec) |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | # B客户端执行过程:设置隔离级别可重复读 MySQL [test]> set tx_isolation= 'repeatable-read' ; Query OK, 0 rows affected, 1 warning (0.00 sec) # 开启事务 MySQL [test]> start transaction ; Query OK, 0 rows affected (0.00 sec) # 更新数据,直接提交 MySQL [test]> update account set balance = balance - 100 where id = 1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 MySQL [test]> commit ; Query OK, 0 rows affected (0.01 sec) # 再次开启事务 MySQL [test]> start transaction ; Query OK, 0 rows affected (0.00 sec) # 插入一条数据 MySQL [test]> insert into account(id,balance) values (4,1000); Query OK, 1 row affected (0.01 sec) MySQL [test]> commit ; Query OK, 0 rows affected (0.00 sec) |
最后一种串行化:set tx_isolation='serializable';可自行验证,能解决上面所有问题,但是一般不会用到的,保证一致性的同时带来的是性能大幅度下降,并发性极低,默认是可重复读。
通过隔离级别在一定程度上能处理事务并发的问题,除此之外还有其他的手段,后续会再次探究。
以上就是全面解析MySQL中的隔离级别的详细内容,更多关于MySQL 隔离级别的资料请关注服务器之家其它相关文章!
原文链接:https://www.cnblogs.com/dlcode/p/14281430.html
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








