
SQL group by去重复且按照其他字段排序的操作

需求:
合并某一个字段的相同项,并且要按照另一个时间字段排序。
例子:
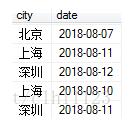
一开始用
?| 1 | select city from table group by city order by date desc |
会报错因为date没有包含在聚合函数或 GROUP BY 子句中
然后用将date放入group by中:
?| 1 | select city from table group by city, date order by date desc |
得到结果
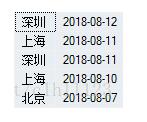
但是得到的结果还是有重复的,没有解决
如果不按照时间排序,就会影响我之后的操作,所以百度了很久,终于找到了解决方法:
正确写法:
?| 1 | select city from table group by city order by max ( date ) desc |
发现很神奇的结果出来了

然后又找了一些资料,发现max()神奇的地方:
?| 1 | select city, max ( date ) as d1 from table group by city,d1 order by d1 desc |
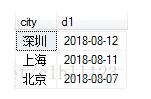
这里写在前面还能看到时间排序
如果还有更好的方法大家一起交流。
补充:MYSQL中去重,DISTINCT和GROUP BY的区别
例如有如下表user:
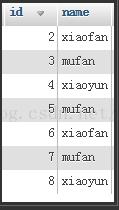
distinct会过滤掉它后面每个字段都重复的记录
用distinct来返回不重复的用户名:select distinct name from user;,结果为:
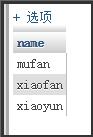
用distinct来返回不重复的name和id:select distinct name,id from user;,结果为:
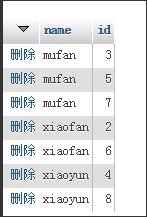
distinct name,id 这样的写法,mysql 会认为要过滤掉name和id两个字段都重复的记录。
如果sql这样写:
?| 1 | select id, distinct name from user |
这样mysql会报错,因为distinct必须放在要查询字段的开头。
group by则可以在要查询的多个字段中,针对其中一个字段去重 :
?| 1 | select id, name from user group by name ; |
以上为个人经验,希望能给大家一个参考,也希望大家多多支持服务器之家。如有错误或未考虑完全的地方,望不吝赐教。
原文链接:https://blog.csdn.net/clhll123/article/details/81777206
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








