
MySQL 覆盖索引的优点

一个通常的建议是为where条件创建索引,但这其实是片面的。索引应当为全部查询设计,而不仅仅是where条件。索引确实能有效地查找数据行,但mysql也能够使用索引获取列数据,这样根本不需要去读取一行数据。毕竟,索引的叶子节点包含了索引对应的值。当年能够读取索引就能够拿到想要的数据时为什么还去读数据行呢?当索引包含了所有查询的数据时,这个索引就称之为覆盖索引。
覆盖索引能够成为一个非常有力的工具并且能够显著改善性能。考虑一下不读数据只需要读取索引的情况:
- 索引值通常会比整个行存储空间小很多,因此mysql只读取索引值时可以只读取很少的数据。这对于缓存负荷来说十分重要——响应时间大部分消耗在复制数据。对于磁盘i/o而言也是一样,因为索引数据相比行数据存储空间小很多,因此更节省i/o负载和内存占用(对于myisam引擎更显著,因为myisam可以将索引打包使得存储空间更小)。
- 索引是按索引值的顺序存储的,因此i/o访问跨度相比随机磁盘位置获取行数据而言消耗的i/o频次更少。对于某些存储引擎,例如myisam和percona xtradb,你甚至能够使用optimize优化表获得完全有序的索引,这会使得简单范围的查询完全使用顺序访问。
- 有些存储引擎,例如myisam,mysql内存中只缓存索引。由于操作系统为myisam缓存了数据,访问时通常需要一个系统调用。这可能导致巨大的性能影响,尤其是对于缓存负荷场景来说,系统调用对于数据访问来说是最昂贵的代价。
- 由于innodb的聚集索引,覆盖索引对于innodb来说十分有帮助。innodb的辅助索引在其叶子节点中保存了行的主键值。因此,辅助索引覆盖查询后可以避免进行主键查询。
在所有的场景中,最典型的就是相比查找数据行,只包含索引列的查询的代价相当低。需要注意的是,聚集索引并不是任意类型的索引。聚集索引必须存储索引数据列对应的值。哈希,空间和全文索引并没有存储这些值,因此mysql只能使用二叉树去覆盖查询。而且,不同的存储引擎实现覆盖索引的方式不同,并且并不是全部的存储引擎都支持覆盖索引(例如memory存储引擎当前就不支持)。
当你验证查询中索引使用了覆盖索引时,使用explain语句时,会在extra列中看到“using index”。例如,在store_goods表有一个(shop_id, goods_category_id1)的多列索引。mysql可以在查询返回数据只有这两列时使用索引:
?| 1 | explain select `goods_category_id1`,`shop_id` from `store_goods` where 1 |

覆盖索引查询在某些情况会让这样的优化失效。mysql查询优化器在执行查询时会判断索引是否覆盖到。假设索引覆盖了where条件,但没有覆盖整个查询。如果评估结果决定不走覆盖索引,那么mysql 5.5及以前的版本会直接获取数据行,即便是不需要这些数据,然后才会过滤掉。
让我们看一下为什么这种情况会发生,然后如何重写查询以便解决这个问题。首先查询是这样的:
?| 1 | explain select * from products where actor= 'sean carrey' and title like '%apollo%' |
这个时候的结果是不会走覆盖索引,而是普通的索引,这是因为:
- 没有索引覆盖了查询数据列,因为我们从数据表读取了全部列并且没有索引列覆盖了全部列。理论上,mysql还有一个快捷方式可以使用,那就是where条件中使用了索引覆盖的列,因此mysql可以先使用这个索引找到对应的actor,然后在检查他们的title是否匹配,然后在读取满足条件的全部的数据行。
- 对于早期的低版本的存储引擎api(mysql 5.5以前的版本)来说,mysql无法在索引中使用like操作,而只支持简单的比较操作(=,in,>=)。mysql可以在索引中使用前缀匹配的like查询,这是因为它可以将它们转换为比较操作。但是前导通配符(也就是like中前置的%)导致存储引擎无法评估匹配条件。因此,mysql会获取行数据再比较,而不是索引的值。
有一种方式可以使用巧妙的组合索引和重写查询条件。我们可以将索引扩展到(artist, title, prod_id),然后像下面那样重写查询语句:
?| 1 2 3 4 5 6 7 | explain select * from products join ( select prod_id from products where actor= 'sean carrey' and title like '%apollo%' ) as t1 on (t1.prod_id=products.prod_id) |
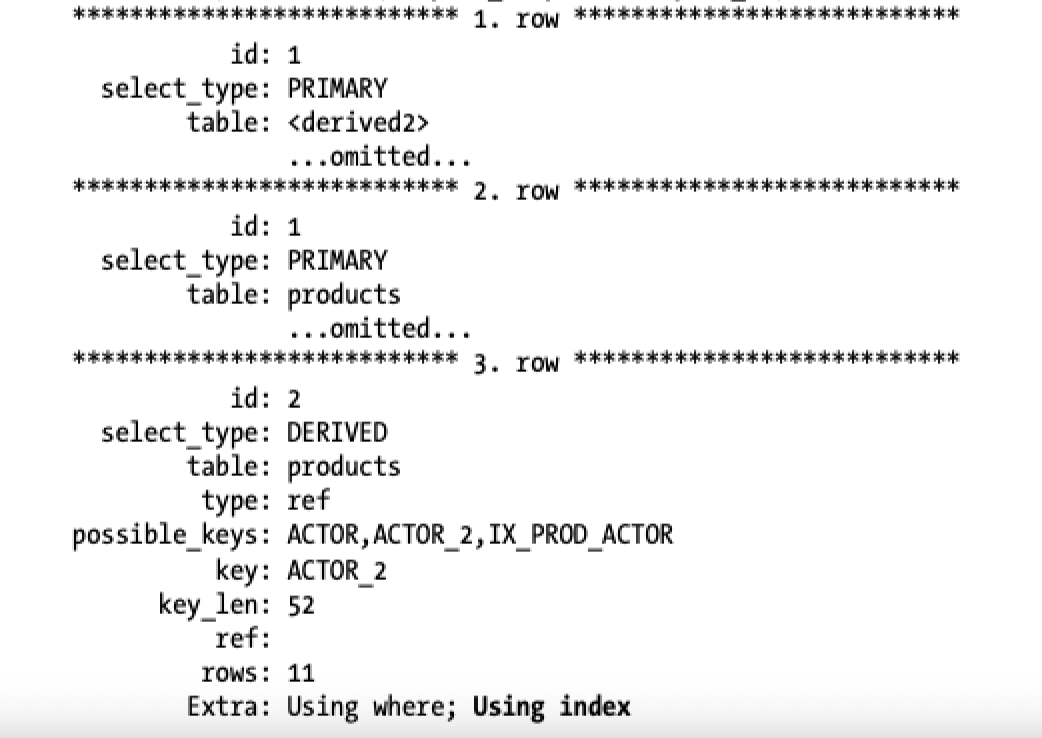
我们称之为“递延join(deferred join)”,因为它延迟了列的访问。在第一阶段的查询中,当它在子查询中找到了匹配的行的过程中,mysql使用了覆盖索引。虽然在整个查询中没有覆盖到,但总比没有的好。
这种优化的效果好坏取决于where条件查找到了多少行数据。假设products表包含了上百万行的数据。可以对比一下这两种查询的性能对比,总的数据为100万行。
- 第一种情况:有30000个products的actor是“sean carrey”,其中20000个的title包含“apollo”;
- 第二种情况:有30000个products的actor是“sean carrey”,其中40个的title包含“apollo”;
- 第三种情况:有50个products的actor是“sean carrey”,其中10个的title包含“apollo”。
对比结果如下表。
| 数据集 | 原始查询 | 优化后查询 |
|---|---|---|
| 第一种情况 | 5qps | 5qps |
| 第二种情况 | 7qps | 35qps |
| 第三种情况 | 2400qps | 2000qps |
结果的解释如下:
- 在第一种情况中,查询返回了很大的结果集,因此看不到优化效果。大部分时间花在了读取和发送数据。
- 在第二种情况中,使用覆盖索引后子查询过滤得到了一个小的结果集,这样优化的效果是性能提升了5倍。产生这种效果的原因是相比查出30000行的数据集,这里只需要读取40行。
- 第三种情况显示了子查询失效了。覆盖索引过滤返回的结果集太少了,导致子查询的代价比直接从数据表读取数据还要高。
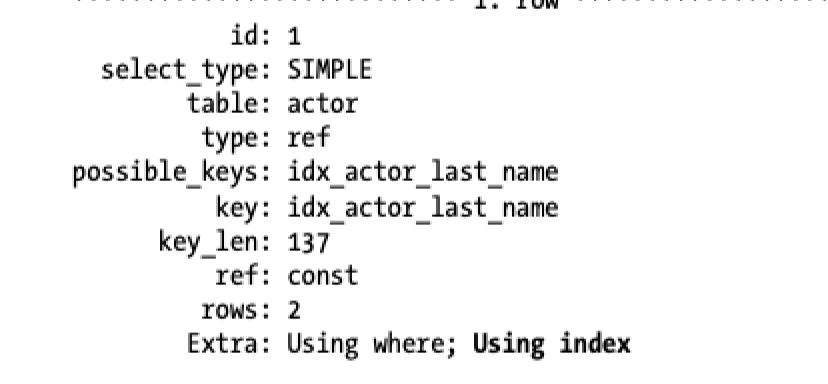
在大多数存储引擎中,一个索引只能够覆盖访问列是索引的一部分。然而,innodb实际上会做进一步的优化。想想innodb的的辅助索引在叶子节点中存储了主键的值。这意味着innodb的辅助索引实际上有了额外的列帮助innodb使用覆盖索引。 例如,sakila.actor表使用了innodb,然后在last_name有一个索引,因此这个索引能够覆盖或者主键actor_id的查询——即便这个列并不是索引的一部分。
?| 1 2 | explain select actor_id, last_name from sakila.actor where last_name = 'hopper' |
以上就是mysql 覆盖索引的优点的详细内容,更多关于mysql 覆盖索引的资料请关注服务器之家其它相关文章!
原文链接:https://juejin.cn/post/6940595769871335461
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。







