
详解MySQL多版本并发控制机制(MVCC)源码

一、前言
作为一个数据库爱好者,自己动手写过简单的sql解析器以及存储引擎,但感觉还是不够过瘾。<<事务处理-概念与技术>>诚然讲的非常透彻,但只能提纲挈领,不能让你玩转某个真正的数据库。感谢cmake,能够让我在mac上用xcode去debug mysql,从而能去领略它的各种实现细节。
(注:本文的mysql采用的是mysql-5.6.35版本)
二、mvcc(多版本并发控制机制)
隔离性也可以被称作并发控制、可串行化等。谈到并发控制首先想到的就是锁,mysql通过使用两阶段锁的方式实现了更新的可串行化,同时为了加速查询性能,采用了mvcc(multi version concurrency control)的机制,使得不用锁也可以获取一致性的版本。
2.1、repeatable read
mysql的通过mvcc以及(next-key lock)实现了可重复读(repeatable read),其思想(mvcc)就是记录数据的版本变迁,通过精巧的选择不同数据的版本从而能够对用户呈现一致的结果。如下图所示:
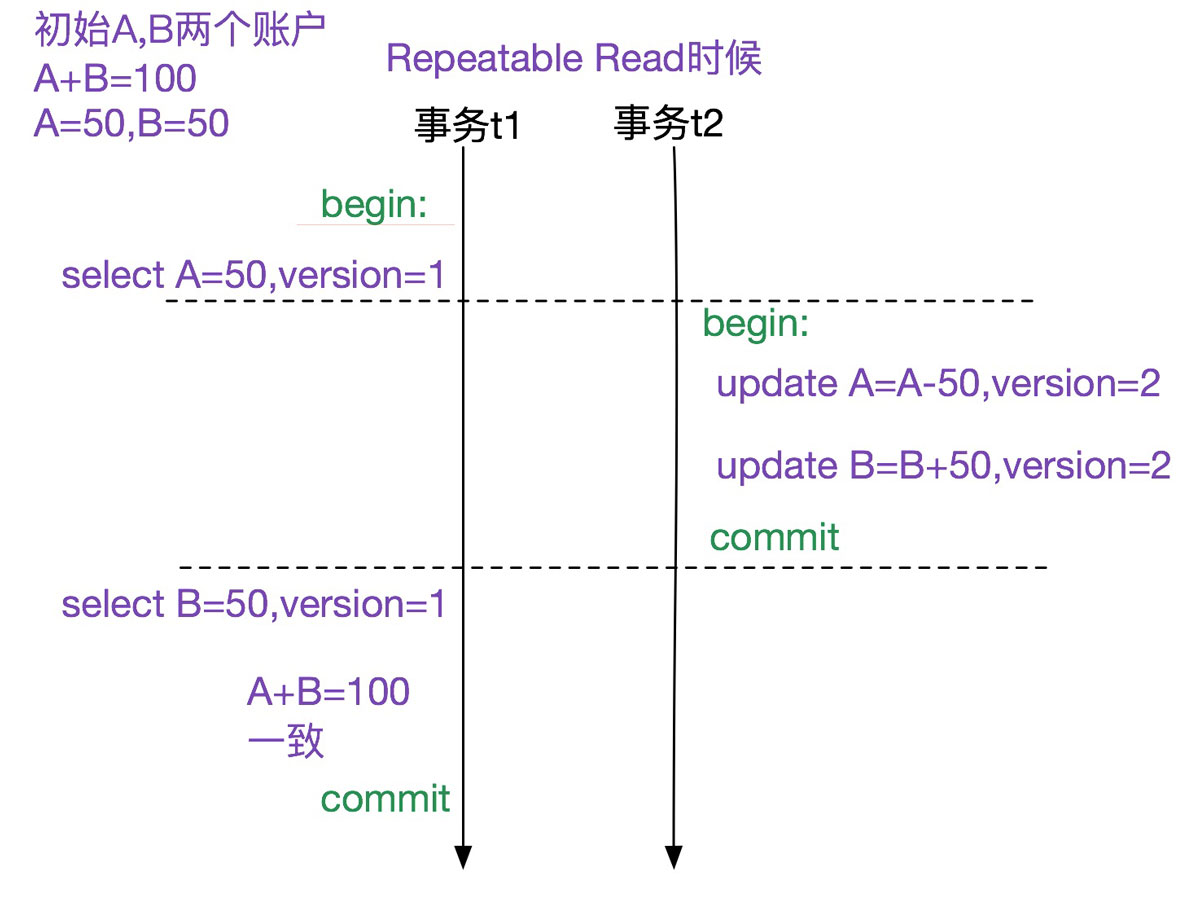
上图中,(a=50|b=50)的初始版本为1。
1.事务t1在select a时候看到的版本为1,即a=50
2.事务t2对a和b的修改将版本升级为2,即a=0,b=100
3.事务t1再此select b的时候看到的版本还是1, 即b=50
这样就隔离了版本的影响,a+b始终为100。
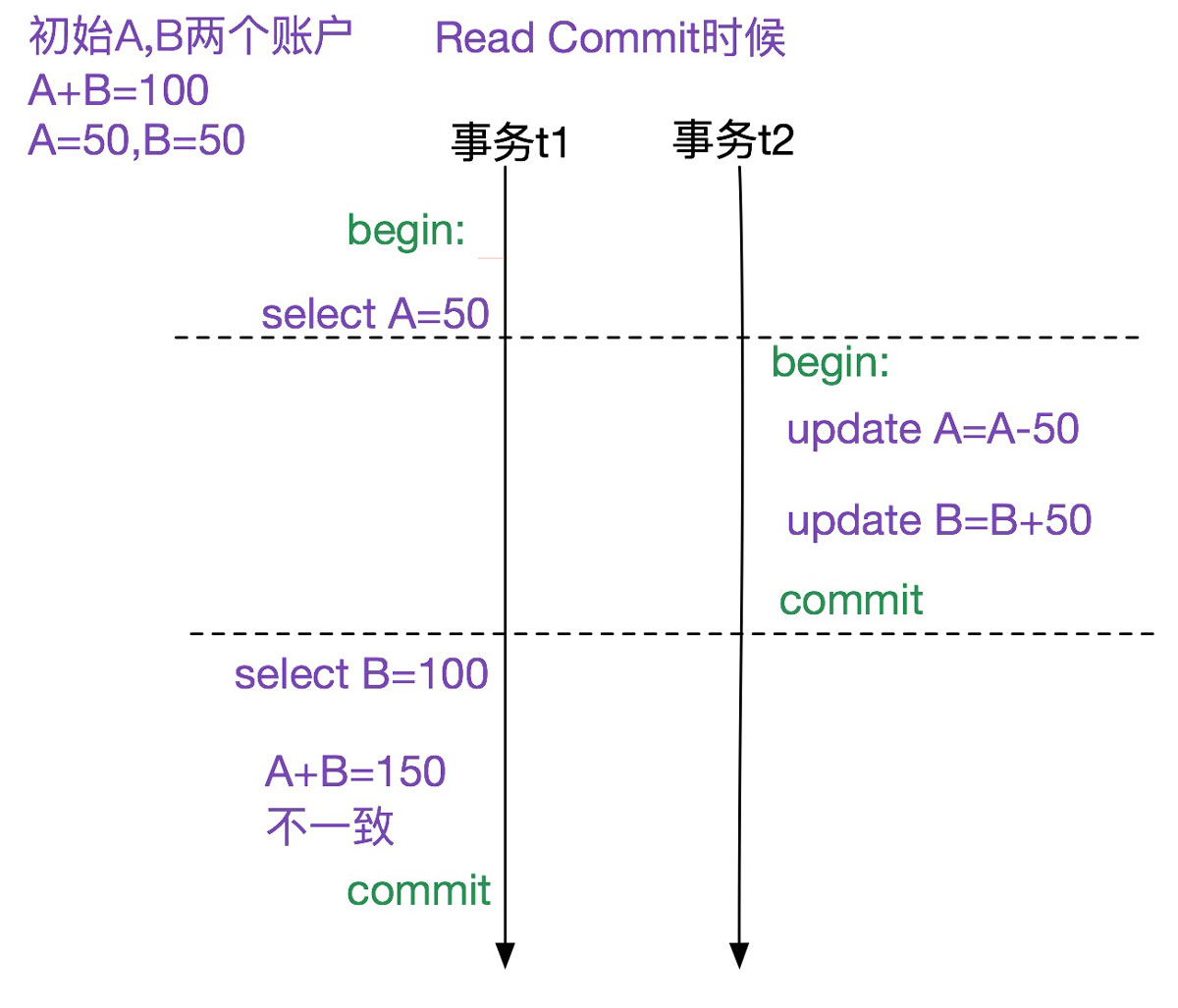
2.2、read commit
而如果不通过版本控制机制,而是读到最近提交的结果的话,则隔离级别是read commit,如下图所示:
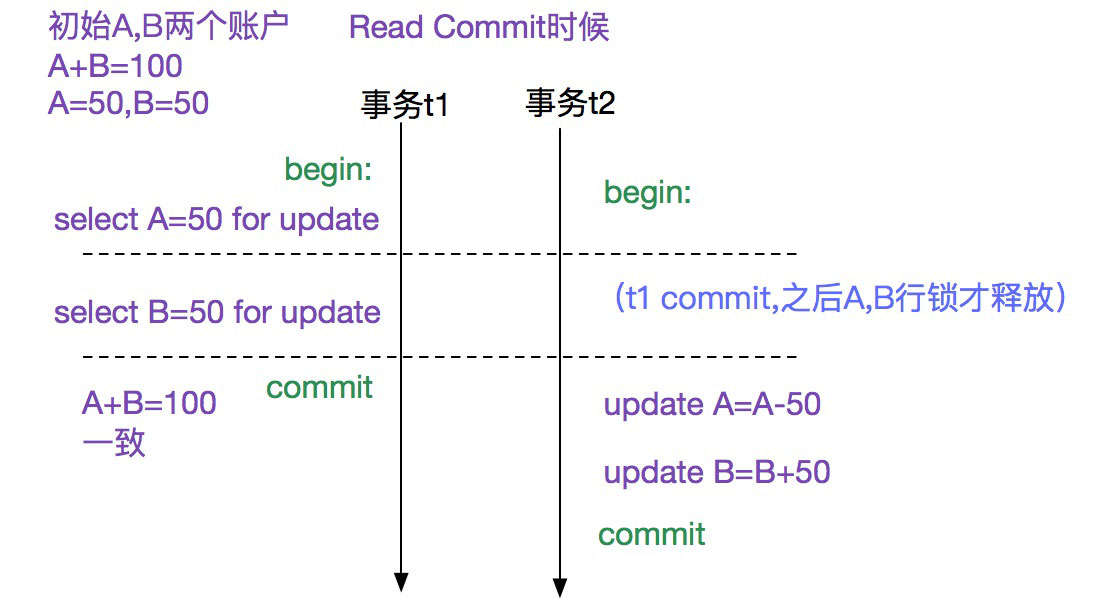
在这种情况下,就需要使用锁机制(例如select for update)将此a,b记录锁住,从而获得正确的一致结果,如下图所示:
2.3、mvcc的优势
当我们要对一些数据做一些只读操作来检查一致性,例如检查账务是否对齐的操作时候,并不希望加上对性能损耗很大的锁。这时候mvcc的一致性版本就有很大的优势了。
三、mvcc(实现机制)
本节就开始谈谈mvcc的实现机制,注意mvcc仅仅在纯select时有效(不包括select for update,lock in share mode等加锁操作,以及update\insert等)。
3.1、select运行栈
首先我们追踪一下一条普通的查询sql在mysql源码中的运行过程,sql为(select * from test);

其运行栈为:
handle_one_connection mysql的网络模型是one request one thread
|-do_handle_one_connection
|-do_command
|-dispatch_command
|-mysql_parse 解析sql
|-mysql_execute_command
|-execute_sqlcom_select 执行select语句
|-handle_select
...一堆parse join 等的操作,当前并不关心
|-*tab->read_record.read_record 读取记录
由于mysql默认隔离级别是repeatable_read(rr),所以read_record重载为
rr_sequential(当前我们并不关心select通过index扫描出row之后再通过condition过滤的过程)。继续追踪:
read_record
|-rr_sequential
|-ha_rnd_next
|-ha_innobase::rnd_next 这边就已经到了innodb引擎了
|-general_fetch
|-row_search_for_mysql
|-lock_clust_rec_cons_read_sees 这边就是判断并选择版本的地方
让我们看下该函数内部:
?| 1 2 3 4 5 6 7 | bool lock_clust_rec_cons_read_sees(const rec_t* rec /*由innodb扫描出来的一行*/,....){ ... // 从当前扫描的行中获取其最后修改的版本trx_id(事务id) trx_id = row_get_rec_trx_id(rec, index , offsets); // 通过参数(一致性快照视图和事务id)决定看到的行快照 return (read_view_sees_trx_id( view , trx_id)); } |
3.2、read_view的创建过程
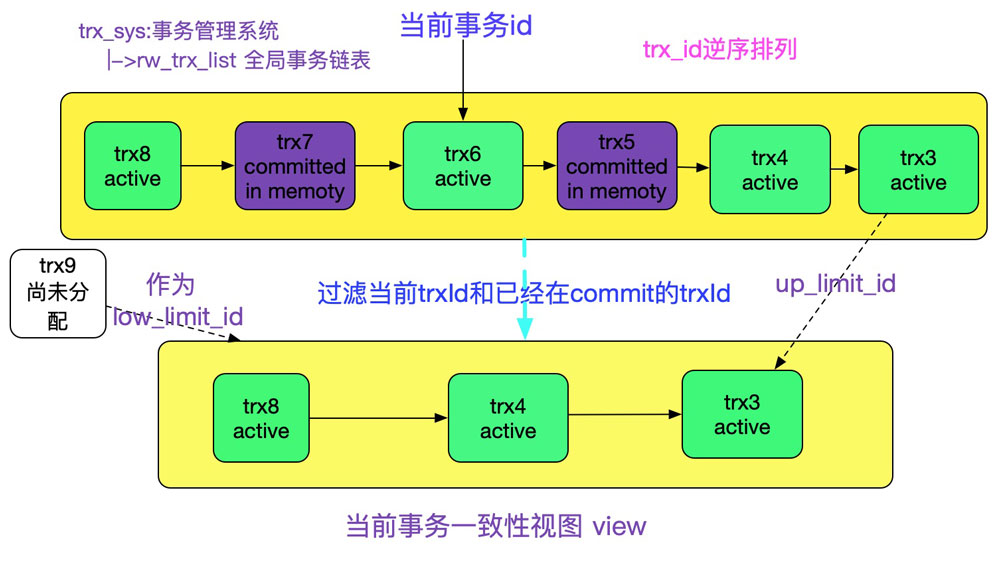
我们先关注一致性视图的创建过程,我们先看下read_view结构:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | struct read_view_t{ // 由于是逆序排列,所以low/up有所颠倒 // 能看到当前行版本的高水位标识,>= low_limit_id皆不能看见 trx_id_t low_limit_id; // 能看到当前行版本的低水位标识,< up_limit_id皆能看见 trx_id_t up_limit_id; // 当前活跃事务(即未提交的事务)的数量 ulint n_trx_ids; // 以逆序排列的当前获取活跃事务id的数组 // 其up_limit_id<tx_id<low_limit_id trx_id_t* trx_ids; // 创建当前视图的事务id trx_id_t creator_trx_id; // 事务系统中的一致性视图链表 ut_list_node_t(read_view_t) view_list; }; |
然后通过debug,发现创建read_view结构也是在上述的rr_sequential中操作的,继续跟踪调用栈:
rr_sequential
|-ha_rnd_next
|-rnd_next
|-index_first 在start_of_scan为true时候走当前分支index_first
|-index_read
|-row_search_for_mysql
|-trx_assign_read_view
我们看下row_search_for_mysql里的一个分支:
?| 1 2 3 4 5 6 | row_search_for_mysql: // 这边只有 select 不加锁模式的时候才会创建一致性视图 else if (prebuilt->select_lock_type == lock_none) { // 创建一致性视图 trx_assign_read_view(trx); prebuilt->sql_stat_start = false ; } |
上面的注释就是select for update(in share model)不会走mvcc的原因。让我们进一步分析trx_assign_read_view函数:
trx_assign_read_view
|-read_view_open_now
|-read_view_open_now_low
好了,终于到了创建read_view的主要阶段,主要过程如下图所示:
代码过程为:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | static read_view_t* read_view_open_now_low(trx_id_t cr_trx_id,mem_heap_t* heap) { read_view_t* view ; // 当前事务系统中max_trx_id(即尚未被分配的trx_id)设置为low_limit_no view ->low_limit_no = trx_sys->max_trx_id; view ->low_limit_id = view ->low_limit_no; // createview构造函数,会将非当前事务和已经在内存中提交的事务给剔除,即判断条件为 // trx->id != m_view->creator_trx_id&& !trx_state_eq(trx, trx_state_committed_in_memory)的 // 才加入当前视图列表 ut_list_map(trx_sys->rw_trx_list, &trx_t::trx_list, createview( view )); if ( view ->n_trx_ids > 0) { // 将当前事务系统中的最小id设置为up_limit_id,因为是逆序排列 view ->up_limit_id = view ->trx_ids[ view ->n_trx_ids - 1]; } else { // 如果当前没有非当前事务之外的活跃事务,则设置为low_limit_id view ->up_limit_id = view ->low_limit_id; } // 忽略purge事务,purge时,当前事务id是0 if (cr_trx_id > 0) { read_view_add( view ); } // 返回一致性视图 return ( view ); } |
3.3、行版本可见性
由上面的lock_clust_rec_cons_read_sees可知,行版本可见性由read_view_sees_trx_id函数判断:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | /*********************************************************************//** checks if a read view sees the specified transaction . @ return true if sees */ univ_inline bool read_view_sees_trx_id( /*==================*/ const read_view_t* view , /*!< in : read view */ trx_id_t trx_id) /*!< in : trx id */ { if (trx_id < view ->up_limit_id) { return ( true ); } else if (trx_id >= view ->low_limit_id) { return ( false ); } else { ulint lower = 0; ulint upper = view ->n_trx_ids - 1; ut_a( view ->n_trx_ids > 0); do { ulint mid = ( lower + upper ) >> 1; trx_id_t mid_id = view ->trx_ids[mid]; if (mid_id == trx_id) { return ( false ); } else if (mid_id < trx_id) { if (mid > 0) { upper = mid - 1; } else { break; } } else { lower = mid + 1; } } while ( lower <= upper ); } return ( true ); } |
其实上述函数就是一个二分法,read_view其实保存的是当前活跃事务的所有事务id,如果当前行版本对应修改的事务id不在当前活跃事务里面的话,就返回true,表示当前版本可见,否则就是不可见,如下图所示。
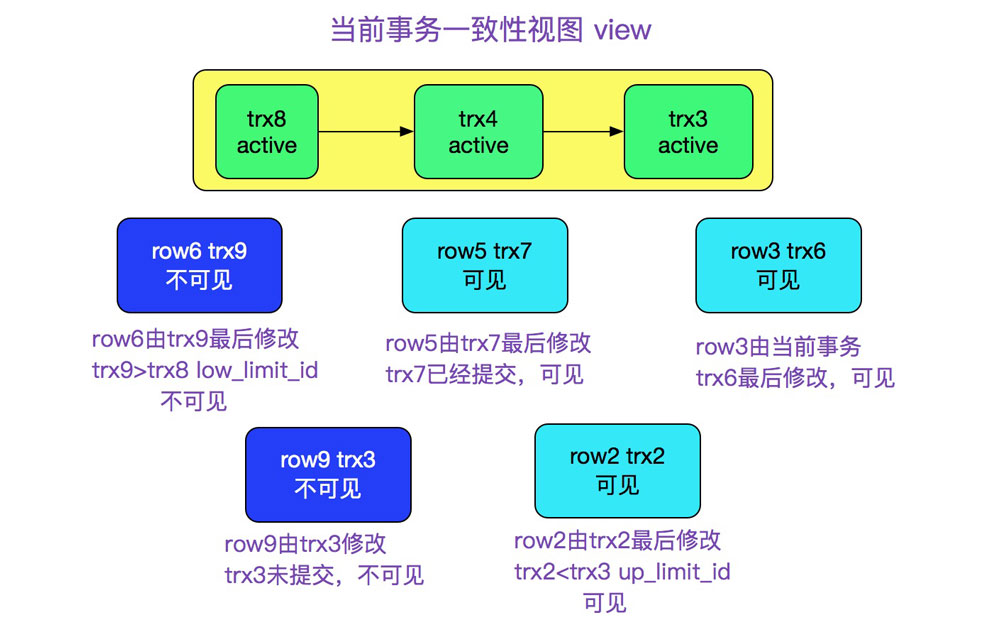
接上述lock_clust_rec_cons_read_sees的返回:
?| 1 2 3 4 5 6 7 8 9 10 11 12 | if (univ_likely(srv_force_recovery < 5) && !lock_clust_rec_cons_read_sees( rec, index , offsets, trx->read_view)){ // 当前处理的是当前版本不可见的情况 // 通过undolog来返回到一致的可见版本 err = row_sel_build_prev_vers_for_mysql( trx->read_view, clust_index, prebuilt, rec, &offsets, &heap, &old_vers, &mtr); } else { // 可见,然后返回 } |
3.4、undolog搜索可见版本的过程
我们现在考察一下row_sel_build_prev_vers_for_mysql函数:
row_sel_build_prev_vers_for_mysql
|-row_vers_build_for_consistent_read
主要是调用了row_ver_build_for_consistent_read方法返回可见版本:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | dberr_t row_vers_build_for_consistent_read(...) { ...... for (;;){ err = trx_undo_prev_version_build(rec, mtr,version, index ,*offsets, heap,&prev_version); ...... trx_id = row_get_rec_trx_id(prev_version, index , *offsets); // 如果当前row版本符合一致性视图,则返回 if (read_view_sees_trx_id( view , trx_id)) { ...... break; } // 如果当前row版本不符合,则继续回溯上一个版本(回到 for 循环的地方) version = prev_version; } ...... } |
整个过程如下图所示:
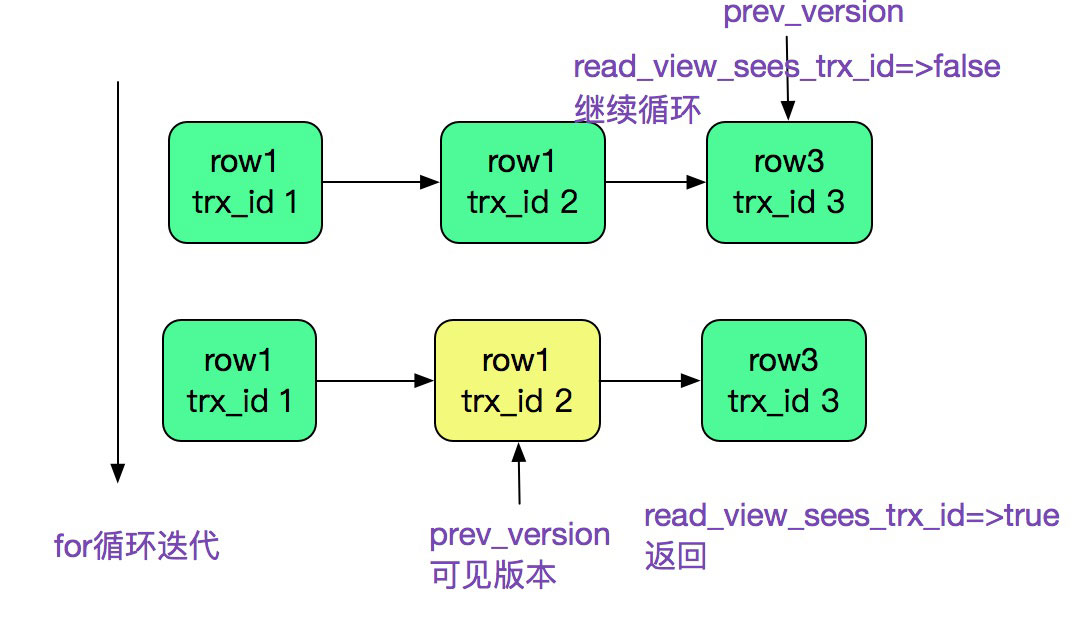
至于undolog怎么恢复出对应版本的row记录就又是一个复杂的过程了,由于篇幅原因,在此略过不表。
3.5、read_view创建时机再讨论
在创建一致性视图的row_search_for_mysql的代码中
?| 1 2 3 4 5 | // 只有非锁模式的 select 才创建一致性视图 else if (prebuilt->select_lock_type == lock_none) { // 创建一致性视图 trx_assign_read_view(trx); prebuilt->sql_stat_start = false ; } |
trx_assign_read_view中由这么一段代码
?| 1 2 3 4 5 6 | // 一致性视图在一个事务只创建一次 if (!trx->read_view) { trx->read_view = read_view_open_now( trx->id, trx->global_read_view_heap); trx->global_read_view = trx->read_view; } |
所以综合这两段代码,即在一个事务中,只有第一次运行select(不加锁)的时候才会创建一致性视图,如下图所示:
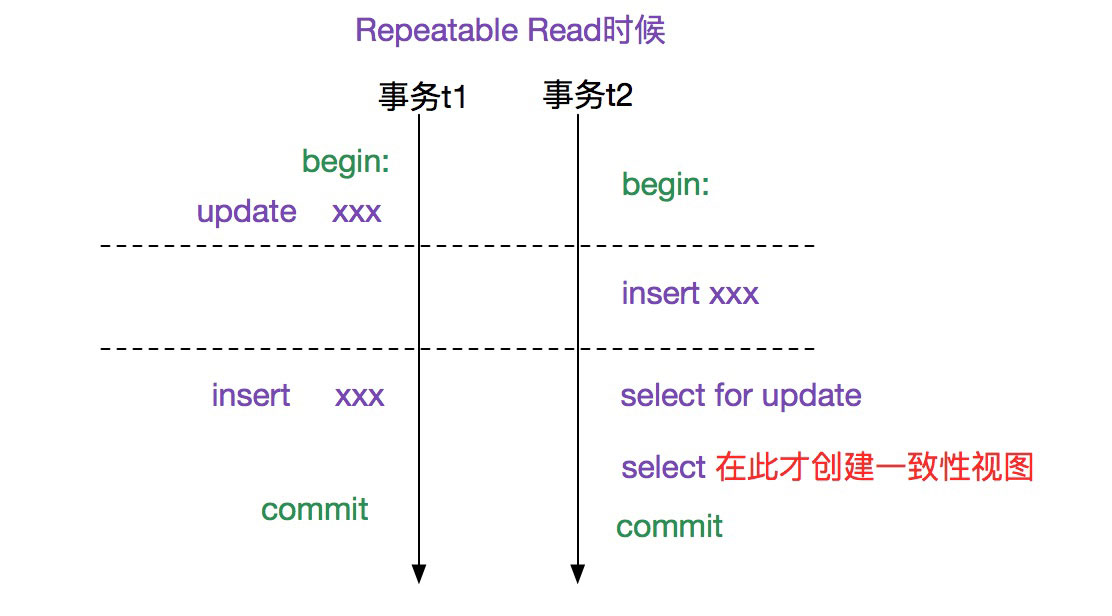
笔者构造了此种场景模拟过,确实如此。
四、mvcc和锁的同时作用导致的一些现象
mysql是通过mvcc和二阶段锁(2pl)来兼顾性能和一致性的,但是由于mysql仅仅在select时候才创建一致性视图,而在update等加锁操作的时候并不做如此操作,所以就会产生一些诡异的现象。如下图所示:

如果理解了update不走一致性视图(read_view),而select走一致性视图(read_view),就可以很好解释这个现象。
如下图所示:
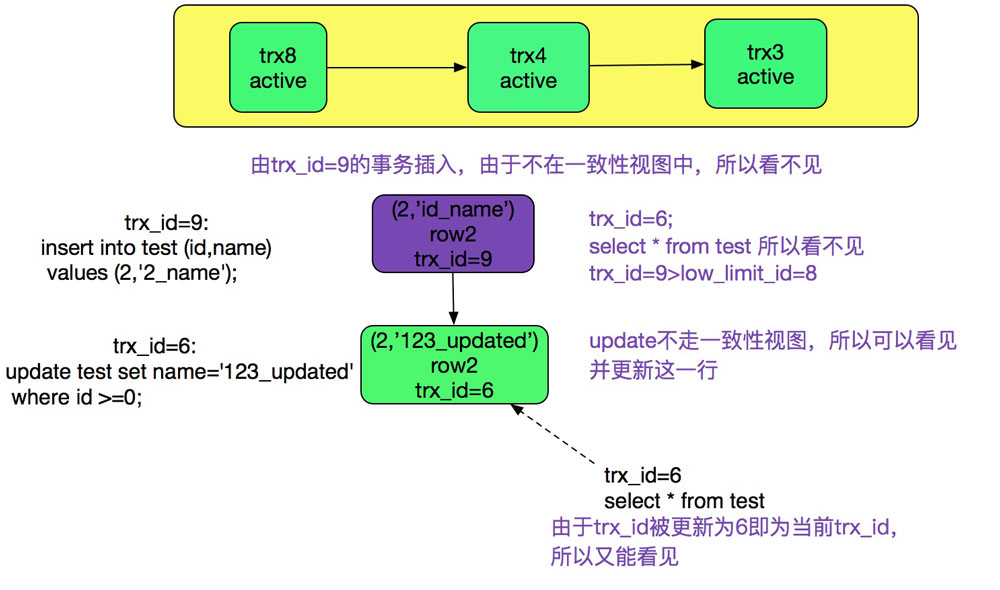
五、总结
mysql为了兼顾性能和acid使用了大量复杂的机制,2pl(两阶段锁)和mvcc就是其实现的典型。幸好可以通过xcode等ide进行方便的debug,这样就可以非常精确加便捷的追踪其各种机制的实现。希望这篇文章能够帮助到喜欢研究mysql源码的读者们。
以上就是详解mysql多版本并发控制机制(mvcc)源码的详细内容,更多关于mysql 并发控制机制 mvcc的资料请关注服务器之家其它相关文章!
原文链接:https://www.cnblogs.com/alchemystar/p/13784292.html
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








