
MySQL分库分表详情

一、业务场景介绍
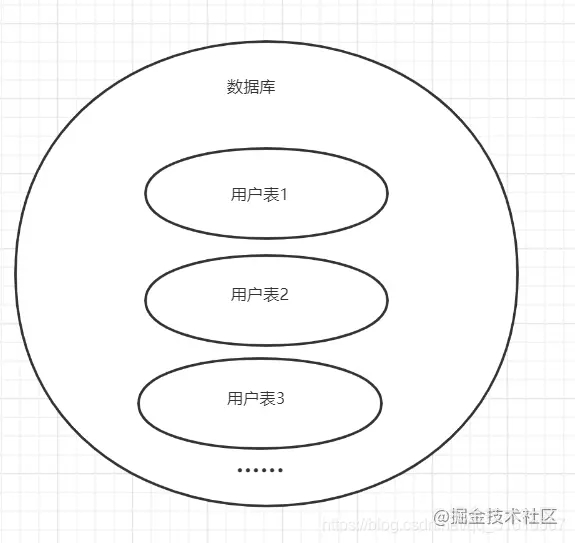
假设目前有一个电商系统使用的是mysql,要设计大数据量存储、高并发、高性能可扩展的方案,数据库中有用户表。用户会非常多,并且要实现高扩展性,你会怎么去设计? ok咱们先看传统的分库分表方式
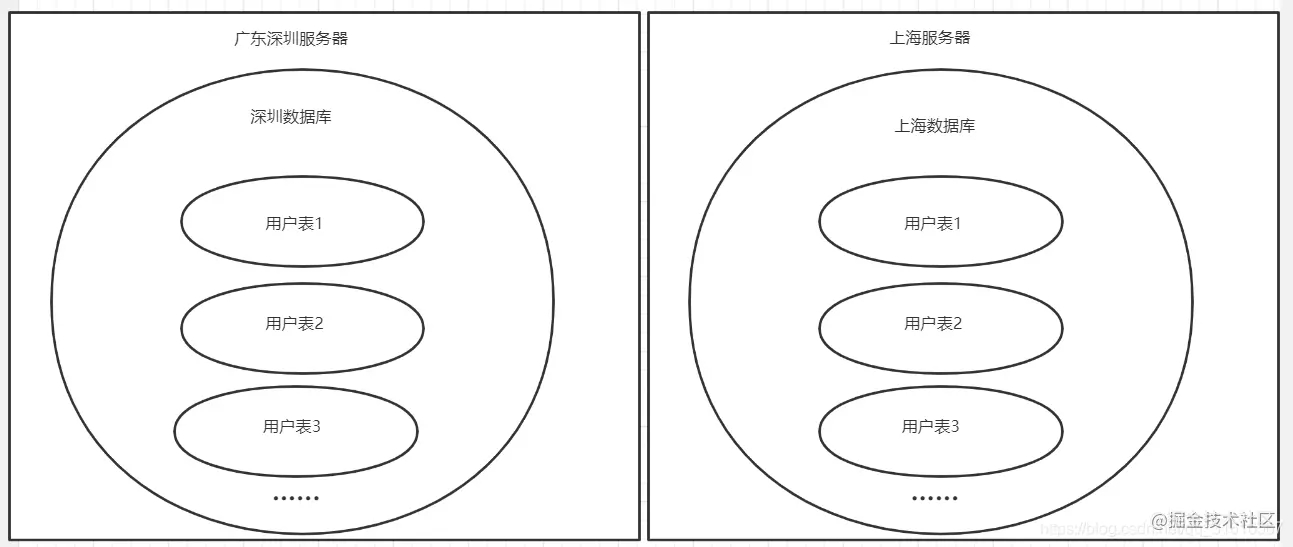
当然还有些小伙伴知道按照省份/地区或一定的业务关系进行数据库拆分
ok,问题来了,如何保证合理的让数据存储在不同的库不同的表里呢?让库减少并发压力?应该怎么去制定分库分表的规则?不用急,这不就来了
二、水平分库分表方法
1.range
第一种方法们可以指定一个数据范围来进行分表,例如从1~1000000,1000001-2000000,使用一百万一张表的方式,如下图所示
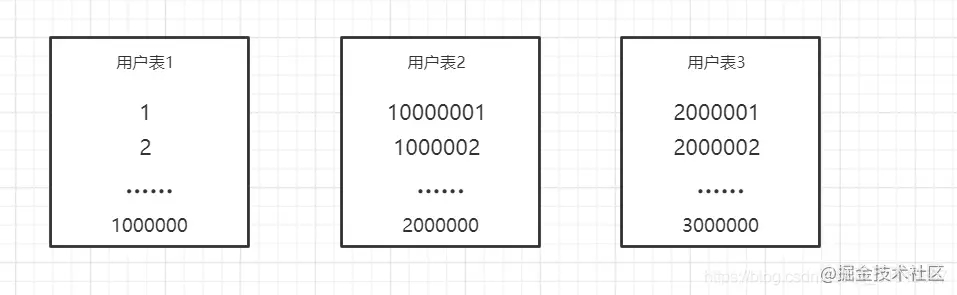
在这里插入图片描述 当然这种方法需要维护表的id,特别是分布式环境下,这种分布式id,在不使用第三方分表工具的情况下,建议使用redis,redis的incr操作可以轻松的维护分布式的表id。
range方法优点: 扩容简单,提前建好库、表就好
range方法缺点: 大部分读和写都访会问新的数据,有io瓶颈,这样子造成新库压力过大,不建议采用。
2.hash取模
针对上述range方式分表有io瓶颈的问题,咱们可以采用根据用户id hasg取模的方式进行分库分表,如图所示: 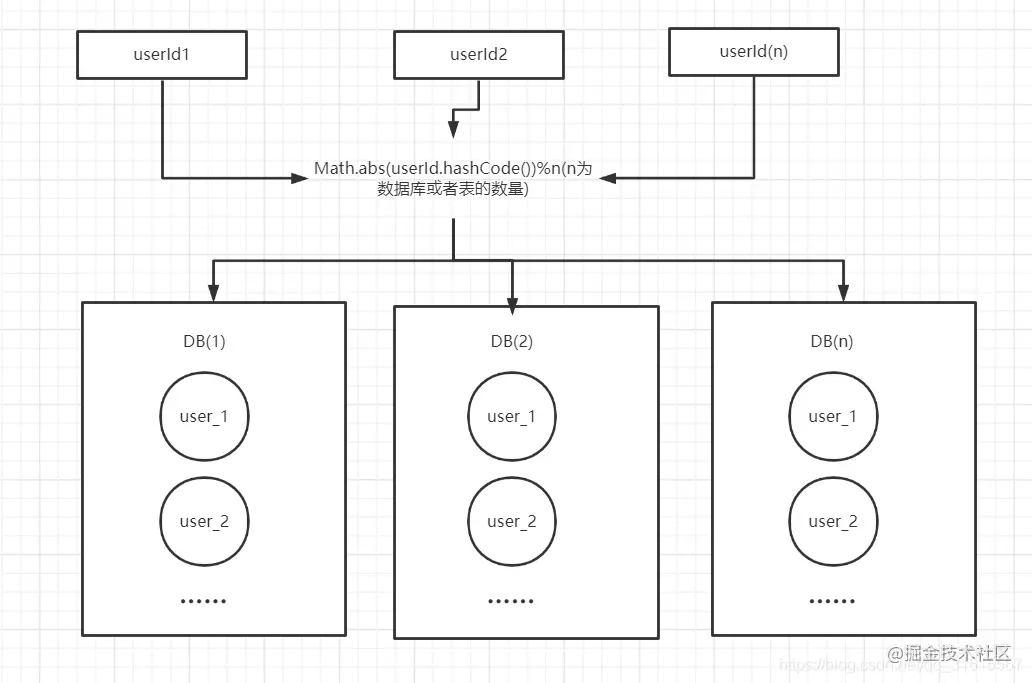
这样就可以将数据分散在不同的库、表中,避免了io瓶颈的问题。
hash取模方法优点: 能保证数据较均匀的分散落在不同的库、表中,减轻了数据库压力
hash取模方法缺点: 扩容麻烦、迁移数据时每次都需要重新计算hash值分配到不同的库和表
3.一致性hash
通过hash取模也不是最完美的办法,那什么才是呢?
使用一致性hash算法能完美的解决问题
普通hash算法:
普通哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。
普通的hash算法在分布式应用中的不足:在分布式的存储系统中,要将数据存储到具体的节点上,如果我们采用普通的hash算法进行路由,将数据映射到具体的节点上,如key%n,key是数据的key,n是机器节点数,如果有一个机器加入或退出集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
一致性hash算法: 按照常用的hash算法来将对应的key哈希到一个具有2^32次方个节点的空间中,即0~ (2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形,如下图所示。
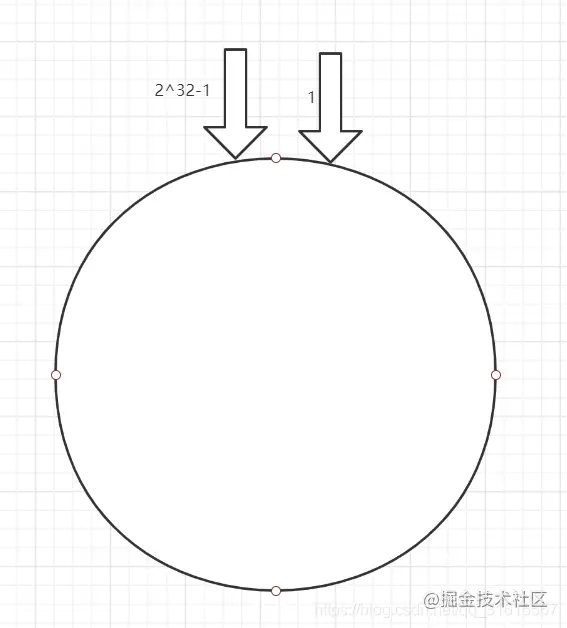
这个圆环首尾相连,那么假设现在有三个数据库服务器节点node1、node2、node3三个节点,每个节点负责自己这部分的用户数据存储,假设有用户user1、user2、user3,我们可以对服务器节点进行hash运算,假设hash计算后,user1落在node1上,user2落在node2上,user3落在user3上
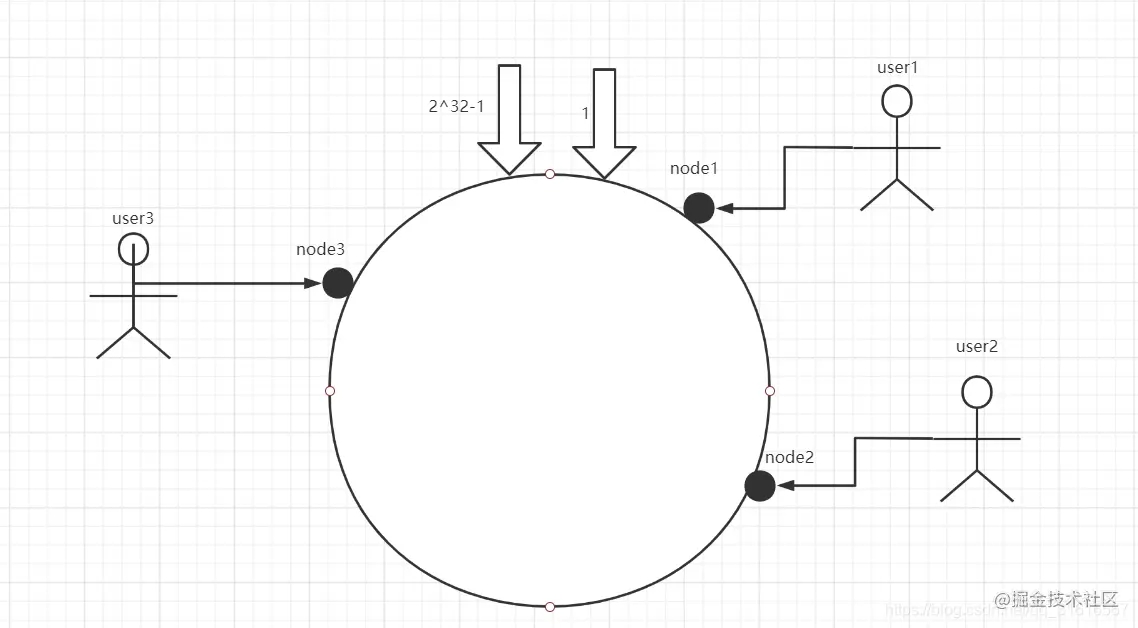
ok,现在咱们假设node3节点失效了
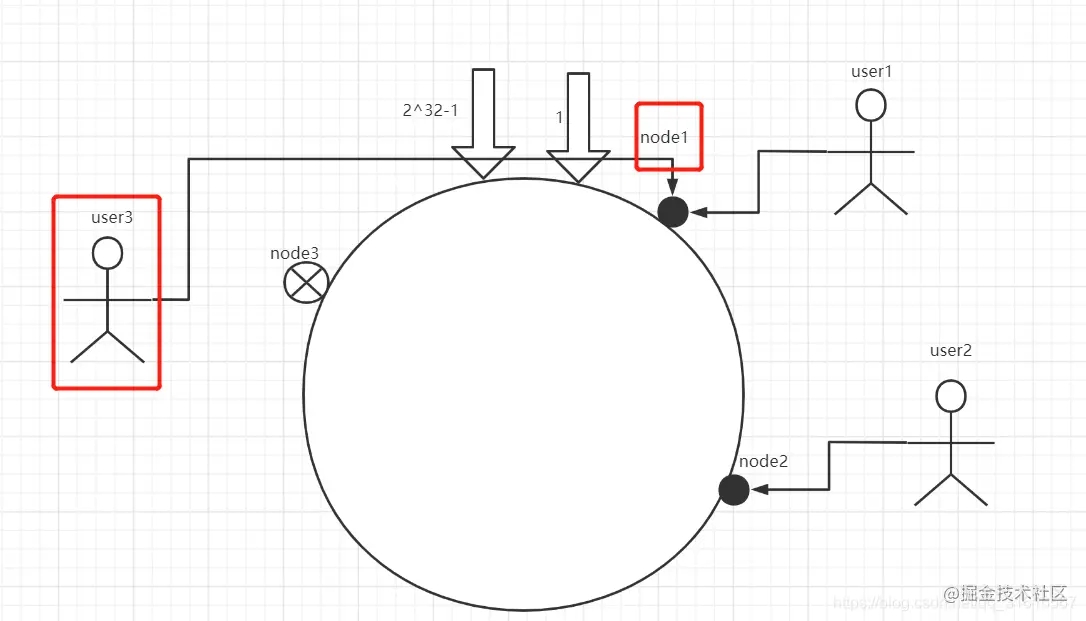
user3将会落到node1上,而之前的node1和node2数据不会改变,再假设新增了节点node4
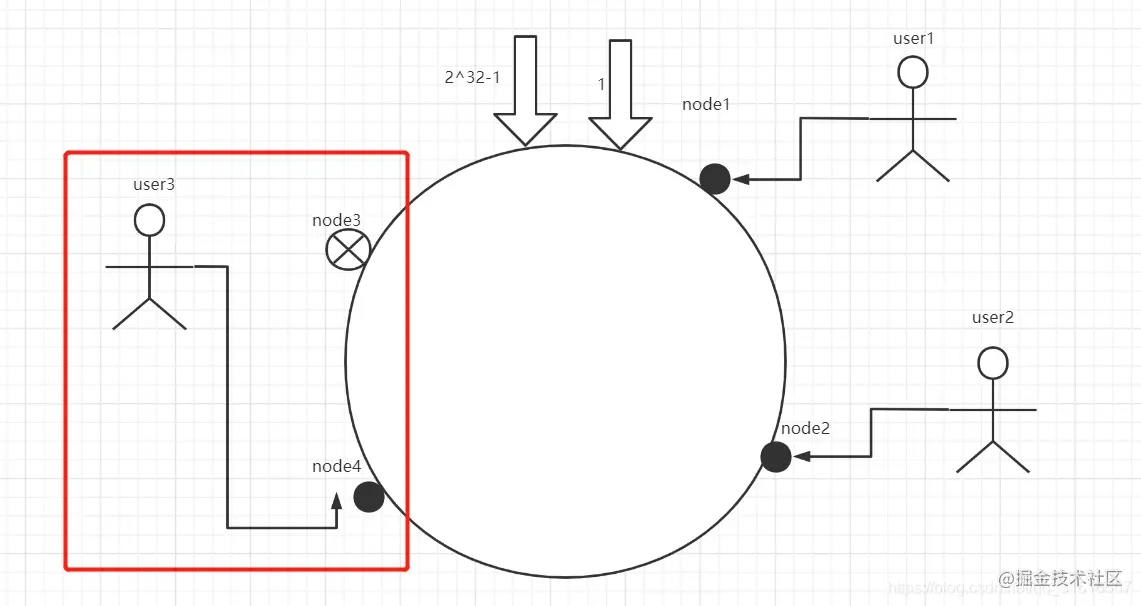
你会发现user3会落到node4上,你会发现,通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
当然还有一个问题还需要解决,那就是平衡性。从图我们可以看出,当服务器节点比较少的时候,会出现一个问题,就是此时必然造成大量数据集中到一个节点上面,极少数数据集中到另外的节点上面。
为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个节点,称为虚拟节点。具体做法可以先确定每个物理节点关联的虚拟节点数量,然后在ip或者主机名后面增加编号。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “node 1-1”、“node 1-2”、“node 1-3”、“node 2-1”、“node 2-2”、“node 2-3”、“node 3-1”、“node 3-2”、“node 3-3”的哈希值,这样形成九个虚拟节点
例如user1定位到node 1-1、node 1-2、node 1-3上其实都是定位到node1这个节点上,这样能够解决服务节点少时数据倾斜的问题,当然这个虚拟节点的个数不是说固定三个或者至多、至少三个,这里只是一个例子,具体虚拟节点的多少,需要根据实际的业务情况而定。
一致性hash方法优点: 通过虚拟节点方式能保证数据较均匀的分散落在不同的库、表中,并且新增、删除节点不影响其他节点的数据,高可用、容灾性强。
一致性取模方法缺点: 嗯,比起以上两种,可以认为没有。
三、单元测试
ok,不废话,接下来上单元测试,假设有三个节点,每个节点有三个虚拟节点的情况
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 | package com.hyh.core.test; import com.hyh.utils.common.stringutils; import org.junit.test; import java.util.linkedlist; import java.util.list; import java.util.sortedmap; import java.util.treemap; /** * 一致性hash test * * @author heyuhua * @ create 2021/1/31 19:50 */ public class consistenthashtest { //待添加入hash环的服务器列表 private static string[] servers = { "192.168.5.1" , "192.168.5.2" , "192.168.5.3" }; //真实结点列表,考虑到服务器上线、下线的场景,即添加、删除的场景会比较频繁,这里使用linkedlist会更好 private static list<string> realnodes = new linkedlist<>(); //虚拟节点, key 表示虚拟节点的hash值,value表示虚拟节点的名称 private static sortedmap< integer , string> virtualnodes = new treemap<>(); //一个真实结点对应3个虚拟节点 private static final int virtual_nodes = 3; /** * 测试有虚拟节点的一致性hash */ @test public void testconsistenthash() { initnodes(); string[] users = { "user1" , "user2" , "user3" , "user4" , "user5" , "user6" , "user7" , "user8" , "user9" }; for ( int i = 0; i < users.length; i++) system. out .println( "[" + users[i] + "]的hash值为" + gethash(users[i]) + ", 被路由到结点[" + getserver(users[i]) + "]" ); } /** * 先把原始的服务器添加到真实结点列表中 */ public void initnodes() { for ( int i = 0; i < servers.length; i++) realnodes. add (servers[i]); for (string str : realnodes) { for ( int i = 0; i < virtual_nodes; i++) { string virtualnodename = str + "-虚拟节点" + string.valueof(i); int hash = gethash(virtualnodename); system. out .println( "虚拟节点[" + virtualnodename + "]被添加, hash值为" + hash); virtualnodes.put(hash, virtualnodename); } } system. out .println(); } //使用fnv1_32_hash算法计算服务器的hash值,这里不使用重写hashcode的方法,最终效果没区别 private static int gethash(string str) { final int p = 16777619; int hash = ( int ) 2166136261l; for ( int i = 0; i < str.length(); i++) hash = (hash ^ str.charat(i)) * p; hash += hash << 13; hash ^= hash >> 7; hash += hash << 3; hash ^= hash >> 17; hash += hash << 5; // 如果算出来的值为负数则取其绝对值 if (hash < 0) hash = math. abs (hash); return hash; } //得到应当路由到的结点 private static string getserver(string key ) { //得到该 key 的hash值 int hash = gethash( key ); // 得到大于该hash值的所有map sortedmap< integer , string> submap = virtualnodes.tailmap(hash); string virtualnode; if (submap.isempty()) { //如果没有比该 key 的hash值大的,则从第一个node开始 integer i = virtualnodes.firstkey(); //返回对应的服务器 virtualnode = virtualnodes.get(i); } else { //第一个 key 就是顺时针过去离node最近的那个结点 integer i = submap.firstkey(); //返回对应的服务器 virtualnode = submap.get(i); } //virtualnode虚拟节点名称要截取一下 if (stringutils.isnotblank(virtualnode)) { return virtualnode. substring (0, virtualnode.indexof( "-" )); } return null ; } } |
这里模拟9个用户对象hash后被路由的情况,看下结果
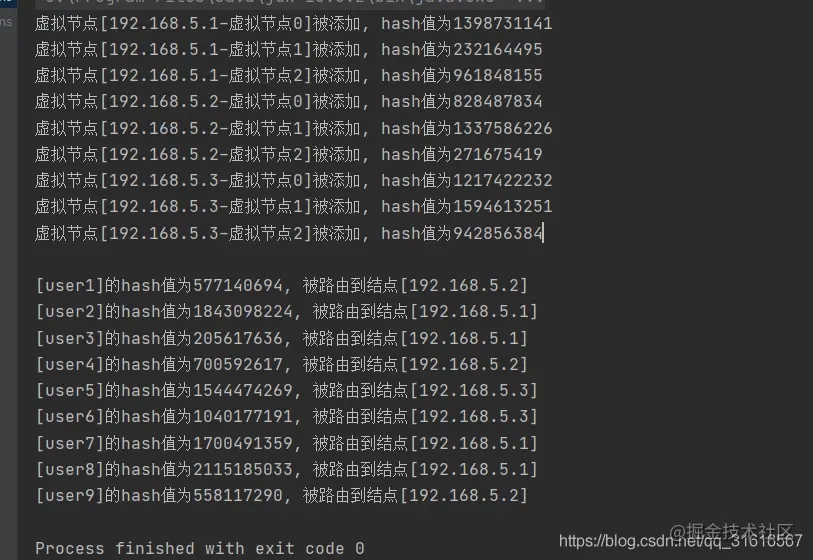
总结:
分库分表在分布式微服务架构环境下建议强烈使用一致性hash算法来做,当然分布式环境下也会产生业务数据数据一致性、分布式事务问题,下期咱们再来探讨数据一致性、分布式事务的解决方案
到此这篇关于mysql分库分表详情的文章就介绍到这了,更多相关mysql分库分表内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://juejin.cn/post/6923898244304994317
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








