
你好奇过 MySQL 内部临时表存了什么吗?


MySQL 临时表分为两种:外部临时表、内部临时表。用户通过 CREATE TEMPORARY TABLE 创建的是外部临时表。SQL 语句执行过程中 MySQL 自行创建的是内部临时表,explain 输出结果的 Extra 列出现了 Using temporary 就说明 SQL 语句执行时使用了内部临时表。
为了描述方便,本文后续内容中临时表和内部临时表意思一样,都表示 SQL 语句执行过程中 MySQL 自行创建的临时表。
本文内容基于 MySQL 5.7.35 源码。
1、 准备工作
本文使用了 2 个示例表:t_recbuf、t_internal_tmp_table,2 个表的结构完全一样,以下列出 t_recbuf 的表结构:
CREATE TABLE `t_recbuf` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `i1` int(10) unsigned DEFAULT '0', `str1` varchar(32) DEFAULT '', `str2` varchar(255) DEFAULT '', `c1` char(11) DEFAULT '', `e1` enum('北京','上海','广州','深圳','天津','杭州','成都','重庆','苏州','南京','洽尔滨','沈阳','长春','厦门','福州','南昌','泉州','德清','长沙','武汉') DEFAULT '北京', `s1` set('吃','喝','玩','乐','衣','食','住','行','前后','左右','上下','里外','远近','长短','黑白','水星','金星','地球','火星','木星','土星','天王星','海王星','冥王星') DEFAULT '', `bit1` bit(8) DEFAULT b'0', `bit2` bit(17) DEFAULT b'0', `blob1` blob, `d1` decimal(10,2) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2001 DEFAULT CHARSET=utf8;
2、哪些场景会用到临时表?
MySQL 使用临时表的场景很多,下面列举出部分场景:
- order by 和 group by 字段不一样。
- join 语句中,order by 或 group by 字段不属于执行计划中第一个表。
- 包含 distinct 关键字的聚合函数,例如:count(distinct i1)、sum(distinct i1) 等。
- 使用 union 或 union distinct 关键字的 SQL 语句。
- 派生表(explain 输出结果的 select_type 列的值为 DERIVED)。
- 子查询半连接物化(把子查询结果存到临时表,然后和主查询进行 join 连接)。
- 子查询物化(除半连接物化之外的场景,如不相关子查询,半连接重复值消除等)。
- insert ... select 语句的源表和目标表是同一个表,例如:insert into t_recbuf(i1, str1) select i1, str1 from t_recbuf)。
以上罗列的场景以官方文档为基础,做了些改动。
大家不用纠结于是不是记住了上面这些场景,确定 SQL 语句是否使用了临时表,查看执行计划是最方便快捷的方法,只要 explain 输出结果的 Extra 列出现了 Using temporary 那就是用了临时表。
3、 临时表用哪种存储引擎?
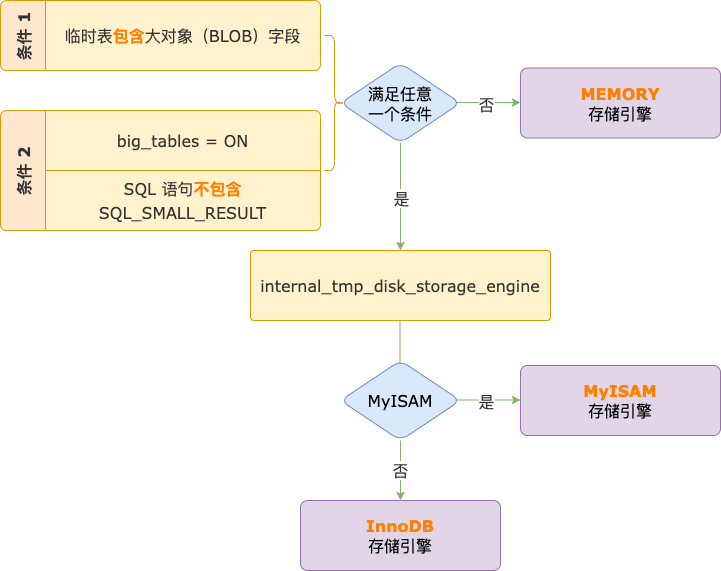
MySQL 临时表可以选择 3 种存储引擎:MEMORY、MyISAM、InnoDB。MEMORY 是内存引擎,数据和索引都存放在内存中;MyISAM、InnoDB 是磁盘存储引擎,数据和索引都存放在磁盘中。
SQL 执行过程中,如果需要使用临时表,MySQL 默认使用 MEMORY 存储引擎。
有 2 种情况会影响 MySQL 的默认行为,以下 2 种情况满足其中任何一种,临时表就会使用 MyISAM 或 InnoDB 存储引擎。
情况 1,写入临时表的字段中包含大对象(BLOB)字段。
关于哪些类型的字段属于大对象,可以看看这篇文章:MySQL 大对象(BLOB)和字符串的分身术。
情况 2,系统变量 big_tables 的值为 ON,表示如果要使用临时表,就一定要用 MyISAM 或 InnoDB 存储引擎。
不过,在 big_tables = ON 的前提下,如果我们能够非常确定某条 SQL 语句写入临时表的数据会很小,MEMORY 存储引擎完全够用,可以对单条 SQL 进行特殊处理。
在 SQL 语句中加入 SQL_SMALL_RESULT 提示,告诉 MySQL:我只需要 MEMORY 存储引擎。SQL_SMALL_RESULT 是这样用的:
select SQL_SMALL_RESULT * from t_recbuf
前面已经介绍完了 MySQL 怎么选择内存、磁盘存储引擎,如果 MySQL 决定了要使用磁盘存储引擎,用 MyISAM 还是 InnoDB ?
这个选择很简单,系统变量 internal_tmp_disk_storage_engine 值为 MyISAM 就选择 MyISAM 存储引擎,值为 InnoDB 就使用 InnoDB 存储引擎。
internal_tmp_disk_storage_engine 的值只能从 MyISAM、InnoDB 中二选一,默认为 InnoDB。
选择存储引擎
4、 内存临时表变磁盘临时表
MEMORY 存储引擎表的记录为固定长度,不支持大对象(BLOB)字段。
变长类型字段(VARCHAR、VARBINARY)也会按照定义时的最大长度存储,实际上相当于 CHAR、BINARY 字段。
内存临时表已插入记录占用的空间,加上即将要插入的记录占用的空间,如果超过阈值,临时表的存储引擎会由内存存储引擎变为磁盘存储引擎。

占用内存空间超过阈值
临时表占用内存空间的阈值,由系统变量 tmp_table_size 和 max_heap_table_size 中较小的那个决定。
tmp_table_size 默认大小为 16M,最小可设置为 1K,最大值是个超级巨大的值。
max_heap_table_size 默认为大小为 16M,最小可设置为 16K,最大值也是超级巨大的值。
得益于 MEMORY 引擎的记录长度固定,判断内存临时表占用的空间是否超过阈值就很简单了。
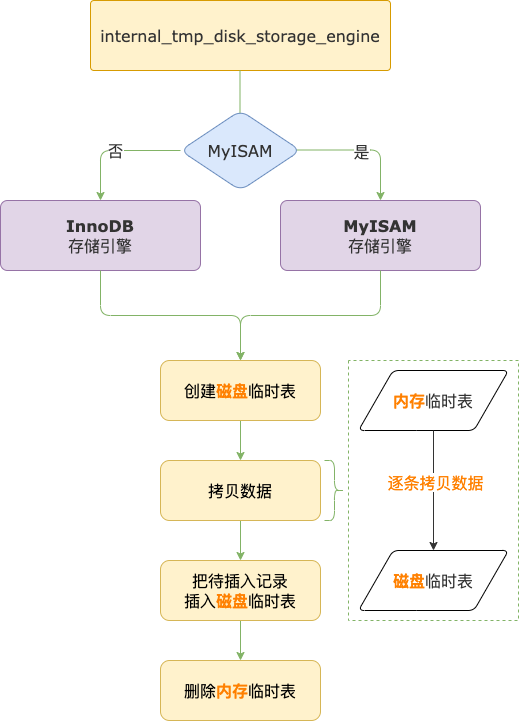
临时表存储引擎变为磁盘存储引擎的过程如下:
- 创建一个 MyISAM 或 InnoDB 临时表,选择哪个存储引擎由 internal_tmp_disk_storage_engine 控制。
- 把内存临时表中的所有记录逐条拷贝到磁盘临时表。
- 把原计划要插入内存临时表但还没插入的那条记录插入磁盘临时表。
- 删除内存临时表。
创建磁盘临时表
等内存临时表写满,才知道需要创建磁盘临时表,这样成本太高了。如果一开始就知道 SQL 语句执行时需要使用临时表,并且内存临时表肯定存不下那么多记录,我们直接告诉 MySQL 使用磁盘临时表岂不是能节省很多开销?
是的,如果我们一开就知道 SQL 语句数据量大会导致使用磁盘临时表,在 SQL 语句中加上 SQL_BIG_RESULT (MySQL 里把这个叫做 hint),MySQL 为临时表选择存储引擎时,就会直接选择磁盘存储引擎。
SQL_BIG_RESULT 是这样用的:
select SQL_BIG_RESULT e1, min(i1) from t_internal_tmp_table group by e1
如果我们在 SQL 语句中加入了 SQL_BIG_RESULT 提示,查询优化器按使用磁盘临时表评估执行成本,也有可能会得出使用磁盘临时表的成本比对 t_internal_tmp_table 表中的记录排序之后再进行 group by 的成本更高的结论,就会选择先对 t_internal_tmp_table 表中的记录进行排序,然后再对已经排好序的记录进行 group by 操作,这样一来内存临时表和磁盘临时表都不需要了。
5、写入哪些字段到临时表?
从写入哪些字段到临时表这个角度看,临时表可以分为两类:
- 为整条 SQL 语句服务的临时表。
- 为单个聚合函数服务的临时表。
对于为整条 SQL 语句服务的临时表,SQL 语句执行过程中,存储引擎返回给 server 层的字段都需要写入到临时表中。写入到临时表中的字段内容,可能是字段值,也可能是函数基于字段值计算的结果,以两个 SQL 为例来说明。
select e1, count(i1) from t_internal_tmp_table group by e1
示例 SQL 1,SQL 执行过程中,MySQL 会把 t_internal_tmp_table 表的 e1 字段值、count(i1) 的计算结果写入到临时表。
select a.e1, b.c1, count(a.i1) as t from t_internal_tmp_table as a inner join t_recbuf as b on a.id = b.id group by a.e1, b.c1 with rollup
示例 SQL 2,由于 rollup 的存在,不能把聚合函数的计算结果写入到临时表,而是要把聚合函数参数中的字段值写入到临时表。
SQL 执行过程中,MySQL 会把 t_internal_tmp_table 表的 e1、i1 字段值,t_recbuf 表中的 c1 字段值写入临时表。
把 t_internal_tmp_table 和 t_recbuf 两个表连接查询得到的记录全部写入临时表之后,再对临时表中的记录进行分组(group by)、聚合(count)操作。
对于为单个聚合函数服务的临时表,SQL 语句执行过程中,只会把聚合函数中的字段写入到临时表,以一个 SQL 为例说明。
select e1, count(distinct i1) as t from t_internal_tmp_table group by e1
示例 SQL 3,临时表只用于为 count(distinct i1) 中的 i1 字段去重,所以临时表中只会写入 t_internal_tmp_table 表的 i1 字段值,并且会为临时表中的 i1 字段建立唯一索引,实现对 i1 字段的去重。
6、为哪些字段建立索引?
MySQL 使用临时表,可能是为了 group by 分组、聚合,也可能是为了对记录去重(distinct),还有可能只是为了避免重复执行子查询而存放子查询的执行结果。
对于 group by 和 distinct,为了保证临时表中 group by 的一个分组只有一条记录,distinct 字段内容相同的记录只保留一条,临时表中会为相应的字段创建唯一索引。
非常重要的说明:临时表中最多只会有一个索引,要么是为 group by 建立的索引,要么是为 distinct 建立的索引。
(1) group by
select e1, count(i1) from t_internal_tmp_table group by e1
这是上一小节(5. 写入哪些字段到临时表?)的示例 SQL 1,临时表中写入 e1 字段值、count(i1) 的计算结果(每个分组中 i1 字段值不为 NULL 的记录数量)。
MySQL 为了保证 e1 字段的每个值在临时表中只有一条记录,会为 e1 字段建立唯一索引,索引名是 。
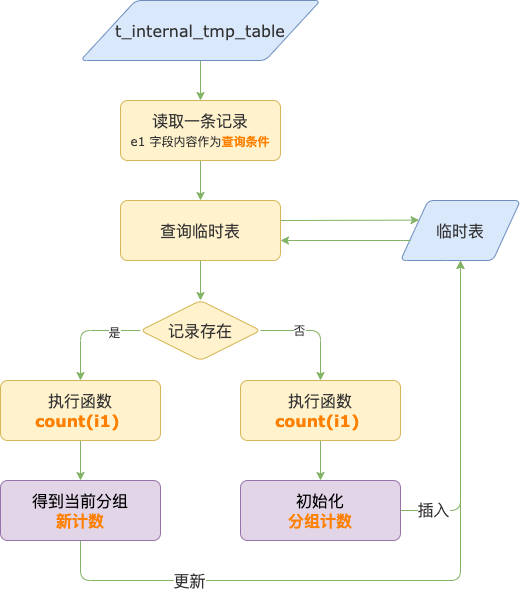
临时表 e1 字段上唯一索引的存在,就是为了保证每个分组中记录的唯一性,保证唯一性的流程是这样的:
第 1 步,从 t_internal_tmp_table 表中读取一条记录之后,用该记录的 e1 字段值作为查询条件,去临时表中查询是否有对应的记录。
第 2 步,如果 e1 字段值对应的记录在临时表中已经存在,执行 count(i1) 函数得到当前分组新计数,然后把分组新计数更新到临时表。
第 3 步,如果 e1 字段值对应的记录在临时表中还不存在,执行 count(i1) 函数初始化分组计数,然后把 e1 字段值和分组计数插入到临时表中。
执行流程示意图
(2) distinct
select e1, count(distinct i1) as t from t_internal_tmp_table group by e1
这是上一小节(5. 写入哪些字段到临时表?)的示例 SQL 3,和示例 SQL 1 不一样的地方是 count() 函数多了个 distinct,表示统计每个分组中,不同的 i1 字段值的数量(不包含 NULL)。
临时表中写入的字段只有 i1,为了保证临时表的每个分组中 i1 字段值是唯一的,MySQL 会为 i1 字段建立唯一索引,索引名是 。
distinct 唯一索引的名字看起来有点词不达意,源码中说以后会改成 。
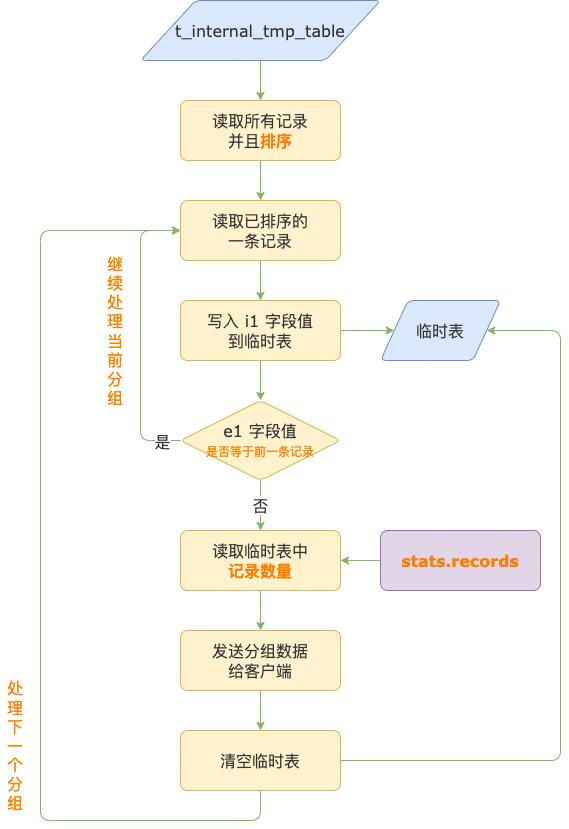
保证每个分组中 i1 字段的唯一性,执行流程是这样的:
前奏,写入数据到临时表之前,MySQL 就已经读取了 t_internal_tmp_table 表中的所记录,并且已经按照 e1 字段排好了序。
第 1 步,读取已经排好序的一条记录,把 i1 字段值写入到临时表中(i1 字段值为 NULL 则不写入)。
如果写入成功,说明临时表中还没有该 i1 字段值对应的记录。
如果写入失败,说明临时表中已经有该 i1 字段值对应的记录了,此时,写入失败的错误会被忽略,因为这正是我们想要的结果:对 i1 字段值去重。
插入操作直接利用了唯一索引中记录不能重复的特性,虽然有点简单粗暴,但也方便快捷。
第 2 步,判断第 1 步读取到的记录的 e1 字段值和上一条记录的 e1 字段值是否一样。
如果一样,说明是同一个分组,回到第 1 步继续执行,写入当前分组中下一条记录的 i1 字段值到临时表。
如果不一样,说明当前分组结束,进入第 3 步处理分组结束逻辑。
第 3 步,获取临时表中的记录数量,也就是分组中 i1 字段值不为 NULL 并且已经去重的数量,发送给客户端。
这里获取临时表中的记录数量很方便,不需要扫描临时表中所有记录进行计数,而是直接读取临时表的统计信息(stats.records)。
第 4 步,分组数据发送给客户端之后,清空临时表中的所有记录,为下一个分组写入 i1 字段值到临时表做准备。
执行流程示意图
(3) hash 字段
为 group by、distinct 字段建立唯一索引,能够保证临时表中记录的唯一性,看起来已经很完美了。
不过,世间事总有例外,存储引擎对于索引中的字段数量、单个字段长度、索引记录长度都是有限制的,一旦超过限制创建索引就会失败,也就不能为 group by、distinct 字段建立唯一索引了。
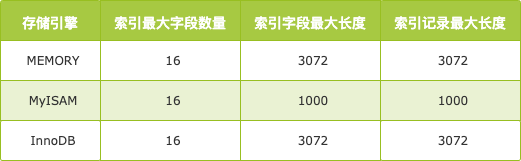
存储引擎限制
不能为 group by、distinct 字段建立唯一索引,那怎么保证这两种情况下记录的唯一性?
别急,你永远可以相信 MySQL 有大招。
如果因为超限问题,不能为 group by、distinct 字段建立唯一索引,MySQL 会在临时表中增加一个哈希字段(字段名 ),并为这个字段建立非唯一索引(因为不同内容计算得到的哈希值有可能重复)。
字段值可能存在重复,那怎么保证临时表中记录的唯一性?流程是这样的:
第 1 步,插入记录到临时表之前,计算 字段值,计算过程是这样的:
计算 group by、distinct 每一个字段的哈希值
所有字段哈希值再经过计算得到的结果,作为 字段值。
第 2 步,用第 1 步中计算出来的 字段值作为查询条件,到临时表中查找记录。
第 3 步,如果在临时表中没有找到记录,说明记录不存在,执行插入操作。
第 4 步,如果在临时表中找到了记录,把记录读取出来(存到 table->record[1] 中)。
这时候还不能说明 group by、distinct 字段对应的记录在表中就是存在的,因为哈希值有可能重复。
第 5 步,把 group by 或 distinct 中的字段逐个和第 4 步读出来的记录中对应的字段进行比较。
如果有任何一个字段值不相等,说明 group by、distinct 字段对应的记录在临时表中不存在,执行插入操作。
如果所有字段值都相等,才能说明 group by、distinct 字段对应的记录在临时表中已经存在。
对于 group by,更新临时表中对应的记录;对于 distinct,准备要插入的记录就可以忽略了,不需要进行插入操作。
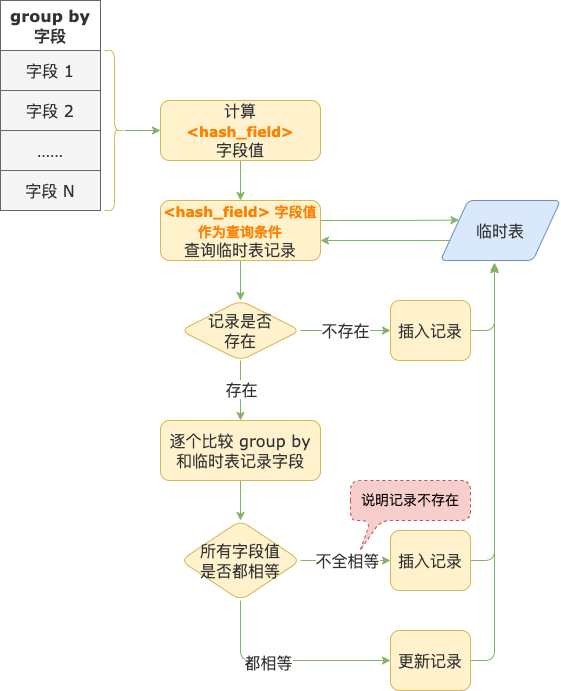
group by 执行流程示意图
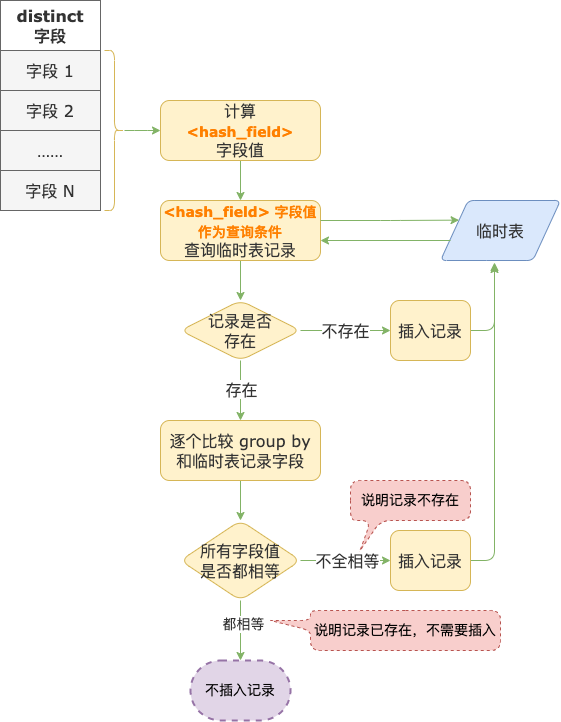
distinct 执行流程示意图
7、 内部临时表使用情况统计
MySQL 每创建一个临时表,状态变量 created_tmp_tables 的值就加 1。
临时表的存储引擎由 MEMORY 替换为 MyISAM 或 InnoDB,状态变量 created_tmp_disk_tables 的值就加 1。
created_tmp_disk_tables 除以 created_tmp_tables 得到的结果越大,说明创建的临时表中,磁盘临时表的比例越高。
减少内存临时表转换为磁盘临时表,有两种可能的优化方案:
降低内存临时表转换为磁盘临时表的比例:修改系统变量 tmp_table_size 和 max_heap_table_size 的值,让临时表可以使用更多的内存,减少这种转换。
强制临时表使用磁盘存储引擎:如果业务类型比较特殊,临时表的数据不可避免的会很大,加大临时表占用内存的阈值效果不明显的情况下,把系统变量 big_tables 的值设置为 ON,强制内部临时表使用磁盘存储引擎,可以避免不必要的内存临时表转换为磁盘临时表。
8、 总结
第 2 小节,列出了 MySQL 使用临时表的部分场景,这些场景反正也记不住,就不用记了,了解下就好。理解了临时表的用途和 SQL 语句的执行过程,大体上也能推断出来是否会用到临时表,再结合 explain 查看执行计划就能知道结果了。
第 3 小节,介绍了临时表的默认存储引擎为 MEMORY,如果写入临时表的字段包含大对象(BLOB)字段,或者系统变量 big_tables 的值为 ON,会根据系统变量 internal_tmp_disk_storage_engine 的值选择使用 MyISAM 或 InnoDB 作为临时表的存储引擎。
第 4 小节,介绍了内存临时表占用空间超过 tmp_table_size 和 max_heap_table_size 中较小的那个值时,会把内存临时表替换为磁盘临时表。如果想要指定单条 SQL 语句直接使用磁盘临时表,可以在 SQL 语句中加入 SQL_BIG_RESULT 提示。
第 5 小节,介绍了临时表中会写入哪些字段。对于 group by,临时表中会写入存储引擎返回给 server 层的所有字段,写入临时表的字段内容,可能是字段值,也可能是聚合函数基于字段值计算的结果;对于 distinct,临时表中会写入聚合函数中的字段。
第 6 小节,介绍了临时表中会为 group by、distinct 字段建立唯一索引,如果 group by 或 distinct 索引字段数量、单个字段长度、索引记录长度超过了限制,就不建立唯一索引了,会在临时表中增加一个名为 的字段,并在该字段上建立非唯一索引。
第 7 小节,介绍了 2 个系统变量 created_tmp_tables、created_tmp_disk_tables 可以用于查看 MySQL 临时表的使用情况,以及可以通过调整 tmp_table_size、max_heap_table_size、big_tables 这 3 个系统变量,减少或避免内存临时表转换为磁盘临时表。
本文转载自微信公众号「一树一溪」,可以通过以下二维码关注。转载本文请联系一树一溪公众号。

原文地址:https://mp.weixin.qq.com/s/jrkZ1lbx4Qzvn_3F0LPxLA
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









