Linux中大内存页Oracle数据库优化的方法

前言
pc server发展到今天,在性能方面有着长足的进步。64位的cpu在数年前都已经进入到寻常的家用pc之中,更别说是更高端的pc server;在intel和amd两大处理器巨头的努力下,x86 cpu在处理能力上不断提升;同时随着制造工艺的发展,在pc server上能够安装的内存容量也越来越大,现在随处可见数十g内存的pc server。正是硬件的发展,使得pc server的处理能力越来越强大,性能越来越高。而在稳定性方面,搭配pcserver和linux操作系统,同样能够满重要业务系统所需要的稳定性和可靠性。当然在成本方面,引用一位在行业软件厂商的网友的话来说,“如果不用pc server改用小型机,那我们赚什么钱啊?”。不管从初期的购买,运行期的能耗和维护成本,pc server都比相同处理能力的小型机便宜很多。正是在性能和成本这两个重要因素的影响下,运行在pc server上的数据库越来越多。笔者所服务的一些客户,甚至把高端的pcserver虚拟化成多台机器,在每台虚拟机上跑一套oracle数据库,这些数据库不乏承载着重要的生产系统。
毫无疑问,在pc server上运行oracle数据库,最适合的操作系统无疑是linux。作为与unix极为类似的操作系统,在稳定性、可靠性和性能方面有着与unix同样优异的表现。但是linux在内存分页处理机制上与aix、hp-ux等操作系统相比有一个明显的缺陷,而这个缺陷在使用较大sga的oracle数据库上体现尤为明显,严重时对数据库性能有着显著的负面影响,甚至会导致数据库完全停止响应。而本文就将从一个案例来详述这种缺陷,并使用linux下的大内存页来解决这一问题。
一、案例的引入
客户的一套系统,出现了严重的性能问题。在问题出现时,系统基本不可使用,应用上所有的业务操作完全失去响应。系统的数据库是运行在rhel 5.2 (red hat enterprise linux server release 5 (tikanga))下的oracle 10.2.0.4 oracle database,cpu为4颗4核至强处理器(intel(r)xeon(r) cpu e7430 @ 2.13ghz),也就是逻辑cpu为16,内存32gb。故障期间,数据库服务器的cpu长期保持在100%。甚至将应用的所有weblogic server都关闭之后,数据库服务器的cpu利用率在数分钟之内都一直是100%,然后逐渐下降,大约需要经过20分钟才会下降到正常的空闲状态,因为这个时候所有的应用都已经关闭,只有非常低的cpu利用率才是正常的状态。据这套系统的数据库维护人员反映,这种情况已经出现多次,就算是重启数据库之后,过不了一两天,这样的故障同样会出现。同时这套系统最近也没做过大的变动。
笔者在接到接到故障报告后,通过ssh连接到数据库数据库都非常慢,需要差不多1分钟才能连接上去。先简单的看一下服务器的性能状况,发展io极低、内存剩余还比较多,至少还有1gb以上,也没有page in / page out。而最显著的现象就是cpu利用率相当地高,一直保持在100%,同时cpu利用率的sys部分,均在95%以上。而操作系统运行队列也一直在200以上。服务器内存的使用情况如下:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | $ cat /proc/meminfo memtotal: 32999792 kb memfree: 1438672 kb buffers: 112304 kb cached: 23471680 kb swapcached: 1296 kb active: 19571024 kb inactive: 6085396 kb hightotal: 0 kb highfree: 0 kb lowtotal: 32999792 kb lowfree: 1438672 kb swaptotal: 38371320 kb swapfree: 38260796 kb dirty: 280 kb writeback: 0kb anonpages: 2071192 kb mapped: 12455324 kb slab: 340140 kb pagetables: 4749076 kb nfs_unstable: 0 kb bounce: 0 kb commitlimit: 54871216kb committed_as: 17226744 kb vmalloctotal:34359738367 kb vmallocused: 22016 kb vmallocchunk:34359716303 kb |
从现象上看,sys cpu高是分析问题的一个重要线索。
在以最快的速度了解了一下操作系统层面的性能情况之后,立即通过sqlplus连接到数据库,查看数据库内部的性能信息:
(注:以下数据关于sql、服务器名称、数据库名称等相关信息经过处理。)
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 | sql> select sid,serial #,program,machine,sql_id,eventfrom v$session where type='user' and status='active'; sid serial # program machine sql_id event -------------------- ------------------------------ ---------- ------------- 519 4304 xxx_app1 0gc4uvt2pqvpu latch: cache buffers chains 459 12806 xxx_app1 0gc4uvt2pqvpu latch: cache buffers chains 454 5518 xxx_app1 15hq76k17h4ta latch: cache buffers chains 529 7708 xxx_app1 0gc4uvt2pqvpu latch: cache buffers chains 420 40948 xxx_app1 0gc4uvt2pqvpu latch: cache buffers chains 353 56222 xxx_app1 f7fxxczffp5rx latch: cache buffers chains 243 42611 xxx_app1 2zqg4sbrq7zay latch: cache buffers chains 458 63221 xxxtimer.exe appserver 9t1ujakwt6fnf local write wait ...为节省篇幅,省略部分内容... 409 4951 xxx_app1 7d4c6m3ytcx87 read by other session 239 51959 xxx_app1 7d4c6m3ytcx87 read by other session 525 3815 xxxtimer.exe appserver 0ftnnr7pfw7r6 enq: ro -fast object reu 518 7845 xxx_app1 log file sync 473 1972 xxxtimer.exe appserver 5017jsr7kdk3b log file sync 197 37462 xxx_app1 cbvbzbfdxn2w7 db file sequential read 319 4939 xxxtimer.exe appserver 6vmk5uzu1p45m db file sequentialread 434 2939 xxx_app1 gw921z764rmkc latch: shared pool 220 50017 xxx_app1 2zqg4sbrq7zay latch: library cache 301 36418 xxx_app1 02dw161xqmrgf latch: library cache 193 25003 oracle@xxx_db1 (j001) xxx_db1 jobq slave wait 368 64846 oracle@xxx_db1 (j000) xxx_db1 jobq slave wait 218 13307 sqlplus@xxx_db1 (tns v1-v3) xxx_db1 5rby2rfcgs6b7 sql*net message to client 435 1883 xxx_app1 fd7369jwkuvty sql*net message from client 448 3001 xxxtimer.exe appserver bsk0kpawwztnwsql*net message from dblink sql>@waitevent sid event seconds_in_wait state ----------------------------------- --------------- ------------------- 556 latch: cache buffers chains 35 waited known time 464 latch:cache buffers chai ns 2 waiting 427 latch:cache buffers chai ns 34 waited short time 458 localwrite wait 63 waiting 403 writecomplete waits 40 waiting 502 writecomplete waits 41 waiting 525 enq:ro - fast object reuse 40 waiting 368 enq:ro - fast object reu se 23 waiting 282 db file sequential read 0 waiting 501 dbfile sequential read 2 waited short time 478 db file sequential read 0 waiting 281 db file sequential read 6 waited known time 195 db file sequential read 4 waited known time 450 db file sequential read 2 waited known time 529 db file sequential read 1 waiting 310 dbfile sequential read 0 waited known time 316 db filesequential read 89 waited short time 370 db file sequential read 1 waiting 380 db file sequential read 1 waited short time 326 jobq slave wait 122 waiting 378 jobq slave wait 2 waiting 425 jobq slave wait 108 waiting 208 sql*net more data from db 11 waited short time link 537 streams aq: waiting for t 7042 waiting ime management or cleanup tasks 549 streams aq: qmn coordinat 1585854 waiting or idle wait 507 streams aq: qmn slave idl 1585854 waiting e wait 430 latch free 2 waited known time 565 latch:cache buffers lru 136 waited short time chain |
从数据库中的活动以及等待事件来看,并没有太大的异常。值得注意的是,在数据库服务器cpu利用率长期在100%,或物理内存耗尽并伴有大量的交换内存换入换出时,需要仔细地诊断数据库中的性能现象,比如某类较多的等待事件,是由cpu或内存不足导致的结果还是因为这些数据库中的特定的活动才是root cause引起cpu过高或内存耗尽。
从上面的数据来看,活动会话并不是特别多,不到50个,加上后台进程的数量,与操作系统中高达200的运行相比,存在不小的差异。数据库中主要有三类的非空闲等待事件,io相关的等待如db file sequential read,database link相关的sql*net more data from dblink以及latch 相关的等待事件。在这三类种,通常只有latch这类等待事件才会引起cpu的利用率增加。
通过分析对比awr报告,在故障期间和正常期间,从数据库活动来说,没有特别明显的差异。但是在系统统计上,差异较大:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | statisticname 1st 2nd value ----------------------------------- -------------- -------------- ------------------------ busy_time 3,475,776 1,611,753 idle_time 2,266,224 4,065,506 iowait_time 520,453 886,345 load -67 -3 nice_time 0 0 num_cpu_sockets 0 0 physical_memory_bytes 0 0 rsrc_mgr_cpu_wait_time 0 0 sys_time 1,802,025 205,644 user_time 1,645,837 1,381,719 |
上面的数据中,是来自于包含故障时间段的1小时(1st)和正常时间段1小时(2nd)的awr的对比数据。对于故障分析来说,特别是故障时间比较短的情况下,1小时的awr报告会不够准确地反映故障期间的性能情况。但是我们在trouble shooting之时,首要的是需要从各种数据中,确定方向。正如前面提到,sys部分的cpu利用率过高是一个很重要的线索,而数据库内部的其他性能数据相差不大的情况下,可以先从cpu这一点着手。
二、操作系统中cpu使用分析
那么,在操作系统中,sys和user这两个不同的利用率代表着什么?或者说二者有什么区别?
简单来说,cpu利用率中的sys部分,指的是操作系统内核(kernel)使用的cpu部分,也就是运行在内核态的代码所消耗的cpu,最常见的就是系统调用(sys call)时消耗的cpu。而user部分则是应用软件自己的代码使用的cpu部分,也就是运行在用户态的代码所消耗的cpu。比如oracle在执行sql时,从磁盘读数据到db buffer cache,需要发起read调用,这个read调用主要是由操作系统内核包括设备驱动程序的代码在运行,因此消耗的cpu计算到sys部分;而oracle在解析从磁盘中读到的数据时,则只是oracle自己的代码在运行,因此消耗的cpu计算到user部分。
那么sys部分的cpu主要会由哪些操作或是系统调用产生呢:
1. i/o操作,比如读写文件、访问外设、通过网络传输数据等。这部分操作一般不会消耗太多的cpu,因为主要的时间消耗会在io操作的设备上。比如从磁盘读文件时,主要的时间在磁盘内部的操作上,而消耗的cpu时间只占i/o操作响应时间的少部分。只有在过高的并发i/o时才可能会使sys cpu有所增加。
2. 内存管理,比如应用进程向操作系统申请内存,操作系统维护系统可用内存,交换空间换页等。其实与oracle类似,越大的内存,越频繁的内存管理操作,cpu的消耗会越高。
3. 进程调度。这部分cpu的使用,在于操作系统中运行队列的长短,越长的运行队列,表明越多的进程需要调度,那么内核的负担也就越高。
4. 其他,包括进程间通信、信号量处理、设备驱动程序内部一些活动等等。
从系统故障时的性能数据来看,内存管理和进程调度这两项可能是引起sys cpu很高的原因。但是运行队列高达200以上,很可能是由于cpu利用率高导致的结果,而不是因为运行队列高导致了cpu利用率高。从数据库里面来看活动会话数不是特别高。那么接下来,需要关注是否是由于系统内存管理方面的问题导致了cpu利用率过高?
回顾本文开始部分收集的/proc/meminfo中系统内存方面数据,可以发现一项重要的数据:
?| 1 | pagetables: 4749076 kb |
从数据可以看到,pagetables内存达到了4637mb。pagetables在字面意思上是指“页面表”。简单地说,就是操作系统内核用于维护进程线性虚拟地址和实际物理内存地址对应关系的表格。
现代计算机对于物理内存,通常是将其以页(page frame)为单位进行管理和分配,在 x86处理器架构上,页面大小为4k。运行在操作系统上的进程,可访问的地址空间称为虚地址空间,跟处理器位数有关。对于32位的x86处理器,进程的可访问地址空间为4gb。在操作系统中运行的每一个进程,都有其独立的虚地址空间或线性地址空间,而这个地址空间同样也是按页(page)进行管理,在linux中,页大小通常为4kb。进程在访问内存时,由操作系统和硬件配合,负责将进程的虚拟地址转换成为物理地址。两个不同的进程,其相同的虚拟线性地址,指向的物理内存,可能相同,比如共享内存;也可能不同,比如进程的私有内存。
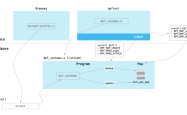
下图是关于虚拟地址和物理内存对应关系的示意图:
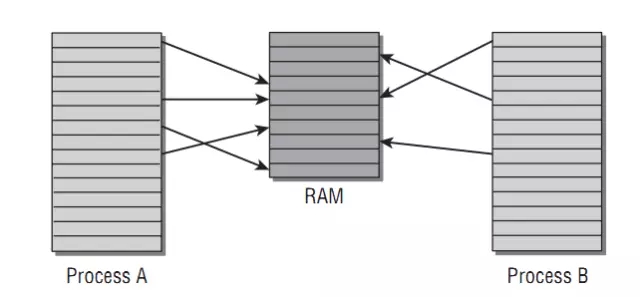
假设有两个进程a、b,分别有一个内存指针指向的地址为0x12345(0x表示16进制数),比如一个进程fork或clone出另一个进程,那么这2个进程就会存在指向相同内存地址的指针的情况。进程在访问0x12345这个地址指向的内存时,操作系统将这个地址转换为物理地址,比如a进程为0x23456,b进程为0x34567,二者互不影响。那么这个物理地址是什么时候得来?对于进程私有内存(大部分情况均是如此)来说,是进程在向操作系统请求分配内存时得来。进程向操作系统请求分配内存时,操作系统将空闲的物理内存以page为单位分配给进程,同时给进程产生一个虚拟线程地址,在虚拟地址和物理内存地址之间建立 映射关系,这个虚拟地址作为结果返回给进程。
page table(页表)就是用于操作系统维护进程虚拟地址和物理内存对应关系的数据结构。下图是一个比较简单情况下的page table示意图:
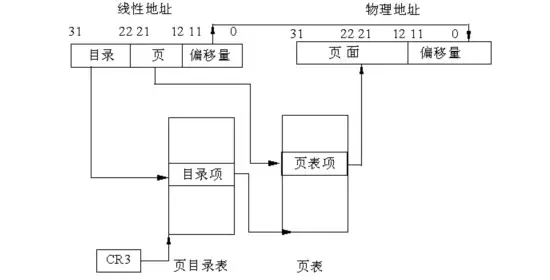
下面简单地描述在32位系统下,页大小为4k时,操作系统是如何为进程的虚拟地址和实际物理地址之间进行转换的。
1. 目录表是用于索引页表的数据结构,每个目录项占32位,即4字节,存储一个页表的位置。目录表刚好占用1页内存,即4kb,可以存储1024个目录项,也就是可以存储1024个页表的位置。
2. 页表项(page table entry)大小为4字节,存储一个物理内存页起始地址。每个页表同样占用4k内存,可以存储1024个物理内存页起始地址。由于物理内存页起始地址以4kb为单位对齐,所以32位中,只需要20位来表示地址,其他12位用于其他用途,比如表示这1内存页是只读还是可写等等。
3. 1024个页表,每个页表1024个物理内存页起始地址,合计就是1m个地址,每个地址指向的物理内存页大小为4kb,合计为4gb。
4. 操作系统及硬件将虚拟地址映射为物理地址时,将虚拟地址的31-22这10位用于从目录项中索引到1024个页表中的一个;将虚拟地址的12-21这10位用于从页表中索引到1024个页表项中的一个。从这个索引到的页表项中得到物理内存页的起始地址,然后将虚拟地址的0-11这12位用作4kb内存页中的偏移量。那么物理内存页起始地址加上偏移量就是进程所需要访问的物理内存的地址。
再看看目录表和页表这2种数据结构占用的空间会有多少。目录表固定只有4kb。而页表呢?由于最多有1024个页表,每个页表占用4kb,因此页表最多占用4mb内存。
实际上32位linux中的进程通常不会那么大的页表。进程不可能用完所有的4gb大小地址空间,甚至有1gb虚拟地址空间分给了内核。同时linux不会为进程一次性建立那么大的页表,只有进程在分配和访问内存时,操作系统才会为进程建立相应地址的映射。
这里只描述了最简单情况下的分页映射。实际上页表目录连同页表一共有四级。同时在32位下启用pae或64位系统,其页表结构比上面的示意图更复杂。但无论怎么样,最后一级即页表的结构是一致的。
在64位系统中,page table(页表)中的页表项,与32位相比,大小从32位变为64位。那么这会有多大的影响?假如一个进程,访问的物理内存有1gb,即262144个内存页,在32位系统中,页表需要262144*4/1024/1024=1mb,而在64位系统下,页表占用的空间增加1倍,即为2mb。
那再看看对于linux系统中运行的oracle数据库,又是怎么样一番情景。本文案例中数据库的sga大小12gb,如果一个oracleprocess访问到了所有的sga内存,那么其页表大小会是24mb,这是一个惊人的数字。这里忽略掉pga,因为平均下来每个进程的pga不超过2m,与sga相比实在太小。从awr报告来看,有300个左右的会话,那么这300个连接的页表会达到7200mb,只不过并不是每个进程都会访问到sga中所有的内存。而从meminfo查看到的page tables大小达到4637mb,这么大的page table空间,正是300个会话,sga大小达到12gb的结果。
系统中显然不会只有page table这唯一的内存管理数据结构,还有其他一些数据结构用于管理内存。这些过大的内存管理结构,无疑会大大增加操作系统内核的负担和对cpu的消耗。而在负载变化或其他原因导致内存需求大幅变化,比如多进程同时申请大量的内存,可能引起cpu在短时间内达到高峰,从而引起问题。
三、使用大内存页来解决问题
虽然没有确实的证据,也没有足够长的时间来收集足够的证据来证明是过大的page table导致了问题,那需要面临多次半小时以上的系统不可用故障。但是从目前来看,这是最大的可疑点。因此,决定先使用大内存页来调优系统的内存使用。
大内存页是一种统称,在低版本的linux中为large page,而当前主流的linux版本中为huge page。下面以huge page为例来说明huge page的优点及如何使用。
使用大内存页有哪些好处:
1. 减少页表(page table)大小。每一个huge page,对应的是连续的2mb物理内存,这样12gb的物理内存只需要48kb的page table,与原来的24mb相比减少很多。
2. huge page内存只能锁定在物理内存中,不能被交换到交换区。这样避免了交换引起的性能影响。
3. 由于页表数量的减少,使得cpu中的tlb(可理解为cpu对页表的cache)的命中率大大提高。
4. 针对huge page的页表,在各进程之间可以共享,也降低了page table的大小。实际上这里可以反映出linux在分页处理机制上的缺陷。而其他操作系统,比如aix,对于共享内存段这样的内存,进程共享相同的页表,避免了linux的这种问题。像笔者维护的一套系统,连接数平常都是5000以上,实例的sga在60gb左右,要是按linux的分页处理方式,系统中大部分内存都会被页表给用掉。
那么,怎么样为oracle启用大内存页(huge page)?以下是实施步骤。由于案例中涉及的数据库在过一段时间后将sga调整为了18g,这里就以18g为例:
1、检查/proc/meminfo,确认系统支持hugepage:
?| 1 2 3 4 5 6 7 | hugepages_total: 0 hugepages_free: 0 hugepages_rsvd: 0 hugepagesize: 2048 kb |
hugepages total表示系统中配置的大内存页页面数。hugepages free表示没有访问过的大内存页面数,这里free容易引起误解,这在稍后有所解释。hugepages rsvd表示已经分配但是还未使用的页面数。hugepagesize表示大内存页面大小,这里为2mb,注意在有的内核配置中可能为4mb。
比如hugepages总计11gb,sga_max_size为10gb,sga_target为8gb。那么数据库启动后,会根据sga_max_size分配hugepage内存,这里为10gb,真正free的hugepage内存为11-10=1g。但是sga_target只有8gb,那么会有2gb不会被访问到,则hugepage_free为2+1=3gb,hugepage_rsvd内存有2gb。这里实际上可以给其他实例使用的只有1gb,也就是真正意义上的free只有1gb。
2. 计划要设置的内存页数量。到目前为止,大内存页只能用于共享内存段等少量类型 的内存。一旦将物理内存用作大内存页,那么这些物理内存就不能用作其他用途,比如作为进程的私有内存。因此不能将过多的内存设置为大内存页。我们通常将大内存页用作oracle数据库的sga,那么大内存页数量:
?| 1 | hugepages_total=ceil(sga_max_size /hugepagesize )+n |
比如,为数据库设置的sga_max_size为18gb,那么页面数可以为ceil(18*1024/2)+2=9218。
这里加上n,是需要将hugepage内存空间设置得比sga_max_size稍大,通常为1-2即可。我们通过ipcs -m命令查看共享内存段的大小,可以看到共享内存段的大小实际上比sga_max_size约大。如果服务器上有多个oracle实例,需要为每个实例考虑共享内存段多出的部分,即n值会越大。另外,oracle数据库要么全部使用大内存页,要么完全不使用大内存页,因此不合适的hugepages_total将造成内存的浪费。
除了使用sga_max_size计算,也可以通过ipcs -m所获取的共享内存段大小计算出更准确的hugepages_total。
?| 1 | hugepages_total= sum (ceil(share_segment_size /hugepagesize )) |
3. 修改/etc/sysctl.conf文件,增加如下行:
?| 1 | vm.nr_hugepages=9218 |
然后执行sysctl –p命令,使配置生效。
这里vm.nr_hugepages这个参数值为第2步计算出的大内存页数量。然后检查/proc/meminfo,如果hugepages_total小于设置的数量,那么表明没有足够的连续物理内存用于这些大内存页,需要重启服务器。
4. 在/etc/security/limits.conf文件中增加如下行:
?| 1 2 3 | oracle soft memlock 18878464 oracle hard memlock 18878464 |
这里设定oracle用户可以锁定内存的大小 ,以kb为单位。
然后重新以oracle用户连接到数据库服务器,使用ulimit -a命令,可以看到:
?| 1 | max lockedmemory (kbytes, -l) 18878464 |
这里将memlock配置为unlimited也可以。
5. 如果数据库使用manual方式管理sga,需要改为auto方式,即将sga_target_size设置为大于0的值。对于11g,由于hugepage只能用于共享内存,不能用于pga,所以不能使用amm,即不能设置memory_target为大于0,只能分别设置sga和pga,sga同样只能是auto方式管理。
6. 最后启动数据库,检查/proc/meminfo中查看hugepages_free是否已经减少。如果已经减少,表明已经使用到hugepage memory。
不过查看出故障数据库服务器上的/proc/meminfo时发现,居然没有hugepage相关的信息,sysctl -a查看所有系统参数也没有找到vm.nr_hugepages这个参数。这是由于linux内核没有编译进hugepage这个特性。我们需要使用其他的内核来启用hugepage。
查看/boot/grub/grub.conf:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | # grub.confgenerated by anaconda # note thatyou do not have to rerun grub after making changes to this file #notice: you have a /boot partition. this means that # all kerneland initrd paths are relative to /boot/, eg. # root(hd0,0) # kernel/vmlinuz-version ro root=/dev/volgroup00/logvol00 # initrd/initrd-version.img #boot=/dev/cciss/c0d0 default=0 timeout=5 splashimage=(hd0,0) /grub/splash .xpm.gz hiddenmenu title red hatenterprise linux server (2.6.18-8.el5xen) with rdac root (hd0,0) kernel /xen .gz-2.6.18-8.el5 module /vmlinuz-2 .6.18-8.el5xen roroot= /dev/volgroup00/logvol00 rhgb quiet module /mpp-2 .6.18-8.el5xen.img title red hatenterprise linux server (2.6.18-8.el5xen) root (hd0,0) kernel /xen .gz-2.6.18-8.el5 module /vmlinuz-2 .6.18-8.el5xen roroot= /dev/volgroup00/logvol00 rhgb quiet module /initrd-2 .6.18-8.el5xen.img title red hatenterprise linux server-base (2.6.18-8.el5) root (hd0,0) kernel /vmlinuz-2 .6.18-8.el5 roroot= /dev/volgroup00/logvol00 rhgb quiet module /initrd-2 .6.18-8.el5.img |
发现这个系统使用的内核带有"xen"字样,我们修改这个文件,将default=0改为default=2,或者将前面2种内核用#号屏蔽掉,然后重启数据库服务器,发现新的内核已经支持hugepage。
数据库启用大内存页之后,本文描述的性能问题甚至是在增大了sga的情况下也没有出现。观察/proc/meminfo数据,pagetables占用的内存一直保持在120m以下,与原来相比,减少了4500mb。据观察,cpu的利用率也较使用hugepages之前有所下降,而系统运行也相当地稳定,至少没有出现因使用hugepage而产生的bug。
测试表明,对于oltp系统来说,在运行oracle数据库的linux上启用hugepage,数据库处理能力和响应时间均有不同程度的提高,最高甚至可以达到10%以上。
四、小结
本文以一个案例,介绍了linux操作系统下大内存页在性能提升方面的作用,以及如何设置相应的参数来启用大内存页。在本文最后,笔者建议在linux操作系统中运行oracle数据库时,启用大内存页来避免本文案例遇到的性能问题,或进一步提高系统性能。可以说,hugepage是少数不需要额外代价就能提升性能的特性。另外值得高兴的是,新版本的linux内核提供了transparent huge pages,以便运行在linux上的应用能更广泛更方便地使用大内存页,而不仅仅是只有共享内存这类内存才能使用大内存页。对于这一特性引起的变化,让我们拭目以待。
文章来源:《oracle dba手记 3》linux大内存页oracle数据库优化 作者:熊军
配图来源: http://2.bp.blogspot.com/-o1ihxahkl0o/vqfhfj2lhwi/aaaaaaaaav4/eguhlwaytmc/s1600/oracle_linux.png
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对服务器之家的支持。
原文链接:https://mp.weixin.qq.com/s/UNUIEg-qIzXXzdKH4TlD4g
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。