
mysql使用from与join两表查询的区别总结
吾爱主题
阅读:260
2024-04-05 14:02:11
评论:0

前言
在mysql中,多表连接查询是很常见的需求,在使用多表查询时,可以from多个表,也可以使用join连接连个表
这两种查询有什么区别?哪种查询的效率更高呢? 带着这些疑问,决定动手试试
1.先在本地的mysql上先建两个表one和two
one表
?| 1 2 3 4 5 | CREATE TABLE `one` ( `id` int (0) NOT NULL AUTO_INCREMENT, `one` varchar (100) NOT NULL , PRIMARY KEY (`id`) ) ENGINE = InnoDB CHARACTER SET = utf8; |
two表
?| 1 2 3 4 5 | CREATE TABLE `two` ( `id` int (0) NOT NULL AUTO_INCREMENT, `two` varchar (100) NOT NULL , PRIMARY KEY (`id`) ) ENGINE = InnoDB CHARACTER SET = utf8; |
先随便插入几条数据,查询看一下;
?| 1 | select one.id,one.one,two.id,two.two from one,two where one.id=two.id; |
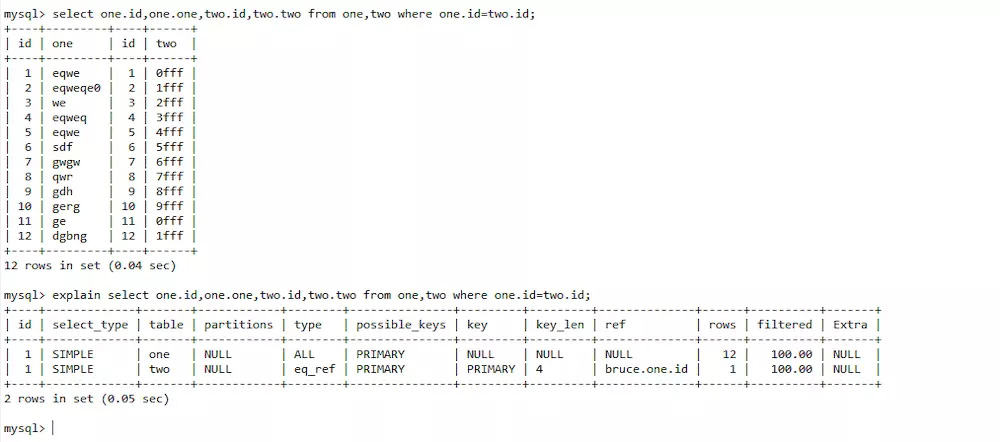
| 1 | select one.id,one.one,two.id,two.two from one join two on one.id=two.id; |
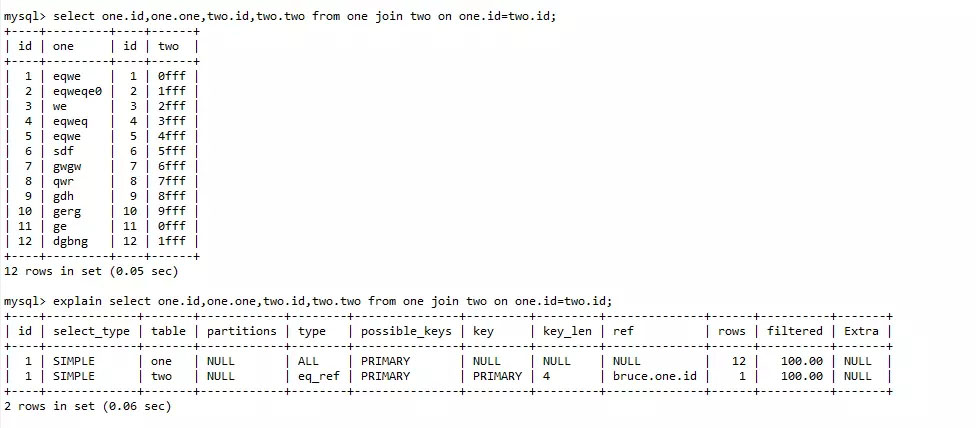
对比这两次的查询,查询时间几乎没有区别,查看sql运行分析,也没有区别
为了突出两种查询的性能差异,往one表中插入100w条数据,往two表中插入10w条数据,在大量数据面前,一丝一毫的差别也会被无限放大;这时候在来比较一下差异
先使用python往数据库中插入数据,为啥用python,因为python写起了简单
上代码
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | import pymysql db = pymysql. connect ( "127.0.0.1" , 'root' , "123456" , "bruce" ) cursor = db. cursor () sql = "INSERT INTO one (one) values (%s)" for i in range(1000000): cursor .executemany(sql, [ 'one' + str(i)]) if i % 10000 == 0: db. commit () print(str(i) + '次 commit' ) db. commit () print( 'insert one ok' ) sql2 = "INSERT INTO two (two) values (%s)" for i in range(100000): cursor .executemany(sql2, [ 'two' + str(i)]) if i % 10000 == 0: db. commit () print(str(i) + '次 commit' ) db. commit () print( 'insert two ok' ) |
耐心等待一会,插入需要一些时间;
等数据插入完成,来查询一些看看
先使用FROM两个表查询
?| 1 | select one.id,one.one,two.id,two.two from one,two where one.id=two.id; |

用时大约20.49;
再用JOIN查询看一下
?| 1 | select one.id,one.one,two.id,two.two from one join two on one.id=two.id; |

用时19.45,在10w条数据中,1秒的误差并不算大,
查看一下使用id作为条件约束时的查询


查询时间没有差别
再看一下sql执行分析


结果还是一样的
总结
在mysql中使用FROM查询多表和使用JOIN连接(LEFT JOIN,RIGHT JOIN除外),查询结果,查询效率是一样的
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对服务器之家的支持。
原文链接:https://www.jianshu.com/p/0631443593da
声明
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









