
mysql重复索引与冗余索引实例分析
吾爱主题
阅读:277
2024-04-05 14:21:56
评论:0

本文实例讲述了mysql重复索引与冗余索引。分享给大家供大家参考,具体如下:
重复索引:表示一个列或者顺序相同的几个列上建立的多个索引。
冗余索引:两个索引所覆盖的列重叠
冗余索引在一些特殊的场景下使用到了索引覆盖,所以比较快。
场景
比如文章与标签表
+——+——-+——+
| id | artid | tag |
+——+——-+——+
| 1 | 1 | php |
| 2 | 1 | linux |
| 3 | 2 | mysql |
| 4 | 2 | oracle |
+——+——-+——+
在实际使用中, 有2种查询
- artid—查询文章的—tag
- tag—查询文章的 —artid
sql语句:
?| 1 2 | select tag from t11 where artid=2; select artid from t11 where tag= 'php' ; |
我们可以建立冗余索引,来达到索引覆盖的情况,这样的查询效率会比较高。
1、建立一个文章标签表
这个表中有两个索引,一个是at,一个是ta,两个索引都用到了artid和tag两个字段。
?| 1 2 3 4 5 6 7 8 | create table `t16` ( `id` int (10) unsigned not null auto_increment, `artid` int (10) unsigned not null default '0' , `tag` char (20) not null default '' , primary key (`id`), key ` at ` (`artid`,`tag`), key `ta` (`tag`,`artid`) ) engine=innodb auto_increment=5 default charset=utf8 |
2、测试两条sql语句
?| 1 | select artid from t11 where tag= 'php' ; |
这条语句的查询分析中的extra有using index,表示此处用到了索引覆盖,使用索引覆盖后就不需要回行查询数据,这样的查询效率比较高。
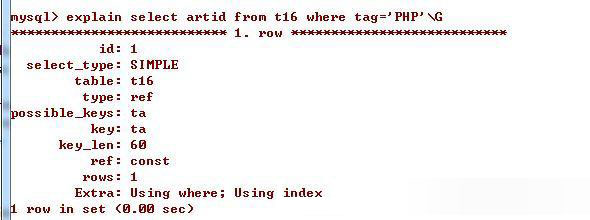
| 1 | select tag from t11 where artid = 1; |
这条语句的查询分析中的extra有using index,表示此处用到了索引覆盖,使用索引覆盖后就不需要回行查询数据,这样的查询效率比较高。

关于索引覆盖的详细内容可以查看前面一篇文章:索引覆盖
希望本文所述对大家MySQL数据库计有所帮助。
原文链接:https://blog.csdn.net/baochao95/article/details/62439908
声明
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








