linux环境不使用hadoop安装单机版spark的方法

大数据持续升温, 不熟悉几个大数据组件, 连装逼的口头禅都没有。 最起码, 你要会说个hadoop, hdfs, mapreduce, yarn, kafka, spark, zookeeper, neo4j吧, 这些都是装逼的必备技能。
关于spark的详细介绍, 网上一大堆, 搜搜便是, 下面, 我们来说单机版的spark的安装和简要使用。
0. 安装jdk, 由于我的机器上之前已经有了jdk, 所以这一步我可以省掉。 jdk已经是很俗气的老生常谈了, 不多说, 用java/scala的时候可少不了。
?| 1 2 3 4 5 | ubuntu@VM-0-15-ubuntu:~$ java -version openjdk version "1.8.0_151" OpenJDK Runtime Environment (build 1.8.0_151-8u151-b12-0ubuntu0.16.04.2-b12) OpenJDK 64-Bit Server VM (build 25.151-b12, mixed mode) ubuntu@VM-0-15-ubuntu:~$ |
1. 你并不一定需要安装hadoop, 只需要选择特定的spark版本即可。你并不需要下载scala, 因为spark会默认带上scala shell. 去spark官网下载, 在没有hadoop的环境下, 可以选择:spark-2.2.1-bin-hadoop2.7, 然后解压, 如下:
?| 1 2 3 4 5 6 | ubuntu@VM-0-15-ubuntu:~ /taoge/spark_calc $ ll total 196436 drwxrwxr-x 3 ubuntu ubuntu 4096 Feb 2 19:57 ./ drwxrwxr-x 9 ubuntu ubuntu 4096 Feb 2 19:54 ../ drwxrwxr-x 13 ubuntu ubuntu 4096 Feb 2 19:58 spark-2.2.1-bin-hadoop2.7/ -rw-r--r-- 1 ubuntu ubuntu 200934340 Feb 2 19:53 spark-2.2.1-bin-hadoop2.7.tgz |
2. spark中有python和scala版本的, 下面, 我来用scala版本的shell, 如下:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | ubuntu@VM-0-15-ubuntu:~ /taoge/spark_calc/spark-2 .2.1-bin-hadoop2.7$ bin /spark-shell Using Spark's default log4j profile: org /apache/spark/log4j-defaults .properties Setting default log level to "WARN" . To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 18 /02/02 20:12:16 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin -java classes where applicable 18 /02/02 20:12:16 WARN Utils: Your hostname , localhost resolves to a loopback address: 127.0.0.1; using 172.17.0.15 instead (on interface eth0) 18 /02/02 20:12:16 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address Spark context Web UI available at http: //172 .17.0.15:4040 Spark context available as 'sc' (master = local [*], app id = local -1517573538209). Spark session available as 'spark' . Welcome to ____ __ / __ /__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_ /_/ /_/ \_\ version 2.2.1 /_/ Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_151) Type in expressions to have them evaluated. Type :help for more information. scala> |
来进行简单操作:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | scala> val lines = sc.textFile( "README.md" ) lines: org.apache.spark.rdd.RDD[String] = README.md MapPartitionsRDD[1] at textFile at <console>:24 scala> lines.count() res0: Long = 103 scala> lines.first() res1: String = # Apache Spark scala> :quit ubuntu@VM-0-15-ubuntu:~ /taoge/spark_calc/spark-2 .2.1-bin-hadoop2.7$ ubuntu@VM-0-15-ubuntu:~ /taoge/spark_calc/spark-2 .2.1-bin-hadoop2.7$ ubuntu@VM-0-15-ubuntu:~ /taoge/spark_calc/spark-2 .2.1-bin-hadoop2.7$ ubuntu@VM-0-15-ubuntu:~ /taoge/spark_calc/spark-2 .2.1-bin-hadoop2.7$ wc -l README.md 103 README.md ubuntu@VM-0-15-ubuntu:~ /taoge/spark_calc/spark-2 .2.1-bin-hadoop2.7$ head -n 1 README.md # Apache Spark ubuntu@VM-0-15-ubuntu:~ /taoge/spark_calc/spark-2 .2.1-bin-hadoop2.7$ |
来看看可视化的web页面, 在Windows上输入: http://ip:4040
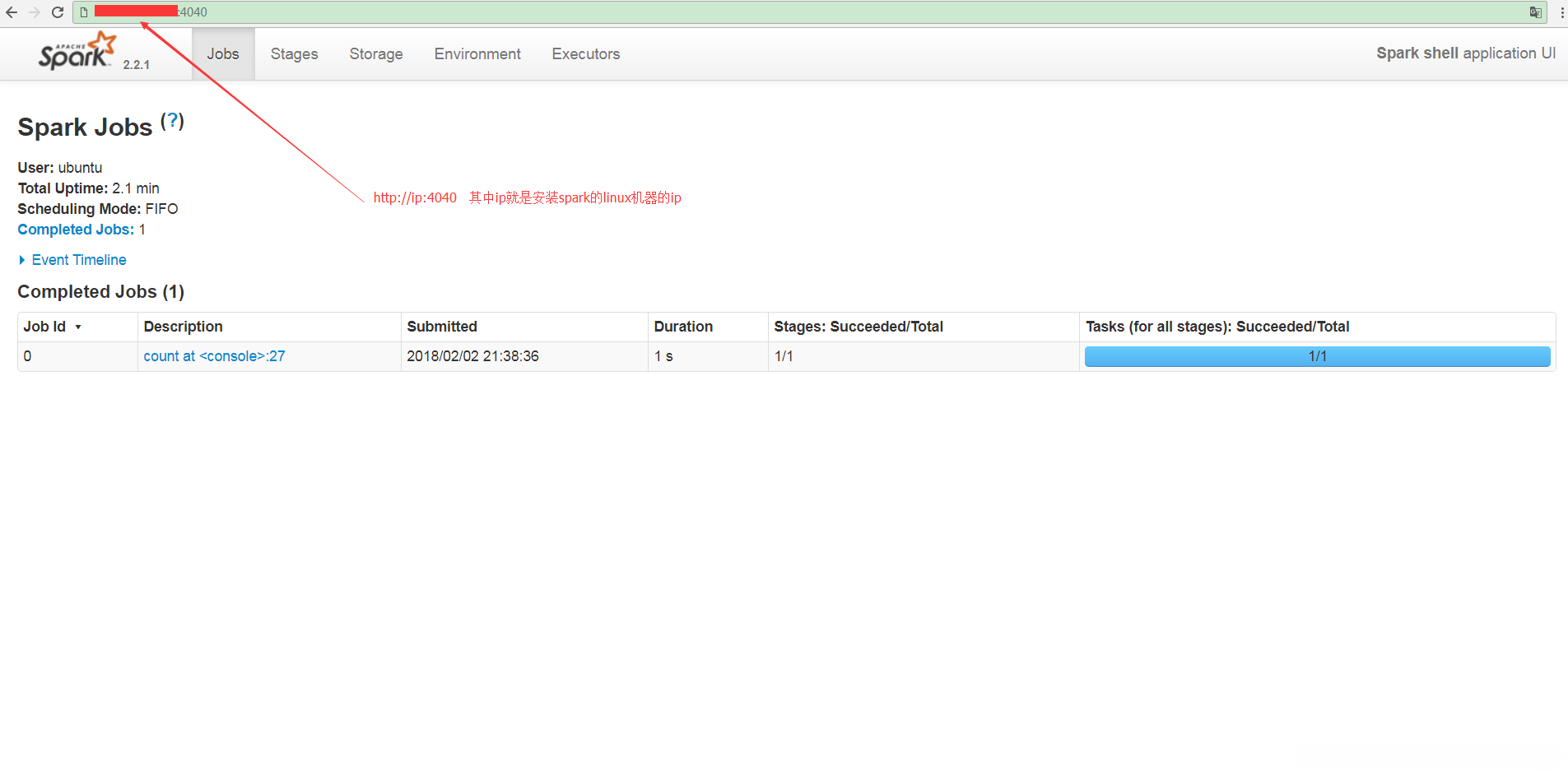
OK, 本文仅仅是简单的安装, 后面我们会继续深入介绍spark.
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对服务器之家的支持。如果你想了解更多相关内容请查看下面相关链接
原文链接:https://blog.csdn.net/stpeace/article/details/79242999
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。