Linux下利用python实现语音识别详细教程

语音识别工作原理简介
语音识别源于 20 世纪 50 年代早期在贝尔实验室所做的研究。早期语音识别系统仅能识别单个讲话者以及只有约十几个单词的词汇量。现代语音识别系统已经取得了很大进步,可以识别多个讲话者,并且拥有识别多种语言的庞大词汇表。
语音识别的首要部分当然是语音。通过麦克风,语音便从物理声音被转换为电信号,然后通过模数转换器转换为数据。一旦被数字化,就可适用若干种模型,将音频转录为文本。
大多数现代语音识别系统都依赖于隐马尔可夫模型(HMM)。其工作原理为:语音信号在非常短的时间尺度上(比如 10 毫秒)可被近似为静止过程,即一个其统计特性不随时间变化的过程。
许多现代语音识别系统会在 HMM 识别之前使用神经网络,通过特征变换和降维的技术来简化语音信号。也可以使用语音活动检测器(VAD)将音频信号减少到可能仅包含语音的部分。
幸运的是,对于 Python 使用者而言,一些语音识别服务可通过 API 在线使用,且其中大部分也提供了 Python SDK。
选择合适的python语音识别包
PyPI中有一些现成的语音识别软件包。其中包括:
•apiai
•google-cloud-speech
•pocketsphinx
•SpeechRcognition
•watson-developer-cloud
•wit
一些软件包(如 wit 和 apiai )提供了一些超出基本语音识别的内置功能,如识别讲话者意图的自然语言处理功能。其他软件包,如谷歌云语音,则专注于语音向文本的转换。
其中,SpeechRecognition 就因便于使用脱颖而出。
识别语音需要输入音频,而在 SpeechRecognition 中检索音频输入是非常简单的,它无需构建访问麦克风和从头开始处理音频文件的脚本,只需几分钟即可自动完成检索并运行。
安装SpeechRecognition
SpeechRecognition 兼容 Python2.6 , 2.7 和 3.3+,但若在 Python 2 中使用还需要一些额外的安装步骤。大家可使用 pip 命令从终端安装 SpeechRecognition:pip3 install SpeechRecognition
安装过程中可能会出现一大片红色字体提示安装错误!我在另一篇博客中有解决方法(http://www.tuohang.net/article/266605.html)
安装完成后可以打开解释器窗口进行验证安装:

注:不要关闭此会话,在后几个步骤中你将要使用它。
若处理现有的音频文件,只需直接调用 SpeechRecognition ,注意具体的用例的一些依赖关系。同时注意,安装 PyAudio 包来获取麦克风输入
识别器类
SpeechRecognition 的核心就是识别器类。
Recognizer API 主要目是识别语音,每个 API 都有多种设置和功能来识别音频源的语音,这里我选择的是recognize_sphinx(): CMU Sphinx - requires installing PocketSphinx(支持离线的语音识别)
那么我们就需要通过pip命令来安装PocketSphinx,在安装过程中也容易出现一大串红色字体的错误。因为博主英语不太好,具体啥错误不知道。直接上解决方法吧!在我的另一篇文章有介绍:
(http://www.tuohang.net/article/266604.html)
音频文件的使用
下载相关的音频文件保存到特定的目录(博主直接保存到ubuntu桌面):
链接:https://pan.baidu.com/s/1oWG1A6JnjpeT_8DhEpoZzw
提取码:sf73
注意:
AudioFile 类可以通过音频文件的路径进行初始化,并提供用于读取和处理文件内容的上下文管理器界面。
SpeechRecognition 目前支持的文件类型有:
- WAV: 必须是 PCM/LPCM 格式
- AIFF
- AIFF-CFLAC: 必须是初始 FLAC 格式;OGG-FLAC 格式不可用
英文的语音识别
在完成以上基础工作以后,就可以进行英文的语音识别了。
(1)打开终端
(2)进入语音测试文件所在目录(博主的是 桌面)
(3)打开python解释器
(4)按照下图输入相关命令
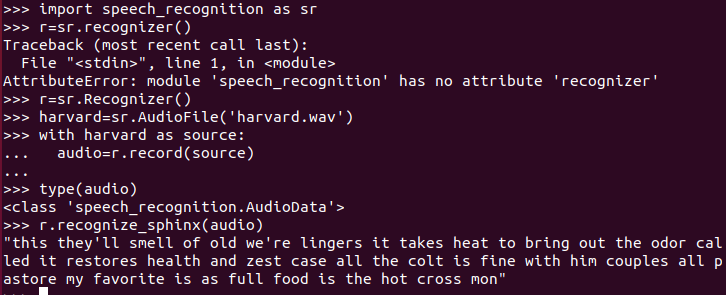
最后就可以看到语音转文字的内容(this they’ll smell …),其实效果还是很不错的!因为是英文,并且没有噪音。
噪音对语音识别的影响
噪声在现实世界中确实存在,所有录音都有一定程度的噪声,而未经处理的噪音可能会破坏语音识别应用程序的准确性。
要了解噪声如何影响语音识别,请下载 “jackhammer.wav”(链接:https://pan.baidu.com/s/1AvGacwXeiSfMwFUTKer3iA
提取码:3pj7)
通过尝试转录效果并不好,我们可以通过尝试调用 Recognizer 类的adjust_for_ambient_noise()命令。
麦克风的使用
若要使用 SpeechRecognizer 访问麦克风则必须安装 PyAudio 软件包。
如果使用的是基于 Debian的Linux(如 Ubuntu ),则可使用 apt 安装 PyAudio:sudo apt-get install python-pyaudio python3-pyaudio安装完成后可能仍需要启用 pip3 install pyaudio ,尤其是在虚拟情况下运行。
在安装完pyaudio的情况下可以通过python实现语音录入生成相关文件。
pocketsphinx的使用注意:
支持文件格式:wav
音频文件的解码要求:16KHZ,单声道
利用python实现录音并生成相关文件程序代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | from pyaudio import PyAudio, paInt16 import numpy as np import wave class recoder: NUM_SAMPLES = 2000 SAMPLING_RATE = 16000 LEVEL = 500 COUNT_NUM = 20 SAVE_LENGTH = 8 Voice_String = [] def savewav( self ,filename): wf = wave. open (filename, 'wb' ) wf.setnchannels( 1 ) wf.setsampwidth( 2 ) wf.setframerate( self .SAMPLING_RATE) wf.writeframes(np.array( self .Voice_String).tostring()) wf.close() def recoder( self ): pa = PyAudio() stream = pa. open ( format = paInt16, channels = 1 , rate = self .SAMPLING_RATE, input = True ,frames_per_buffer = self .NUM_SAMPLES) save_count = 0 save_buffer = [] while True : string_audio_data = stream.read( self .NUM_SAMPLES) audio_data = np.fromstring(string_audio_data, dtype = np.short) large_sample_count = np. sum (audio_data > self .LEVEL) print (np. max (audio_data)) if large_sample_count > self .COUNT_NUM: save_count = self .SAVE_LENGTH else : save_count - = 1 if save_count < 0 : save_count = 0 if save_count > 0 : save_buffer.append(string_audio_data ) else : if len (save_buffer) > 0 : self .Voice_String = save_buffer save_buffer = [] print ( "Recode a piece of voice successfully!" ) return True else : return False if __name__ = = "__main__" : r = recoder() r.recoder() r.savewav( "test.wav" ) |
注意:在利用python解释器实现时一定要注意空格!!!
最后生成的文件就在Python解释器回话所在目录下,可以通过play来播放测试一下,如果没有安装play可以通过apt命令来安装。
中文的语音识别
在进行完以前的工作以后,我们对语音识别的流程大概有了一定的了解,但是作为一个中国人总得做一个中文的语音识别吧!
我们要在CMU Sphinx语音识别工具包里面下载对应的普通话升学和语言模型。
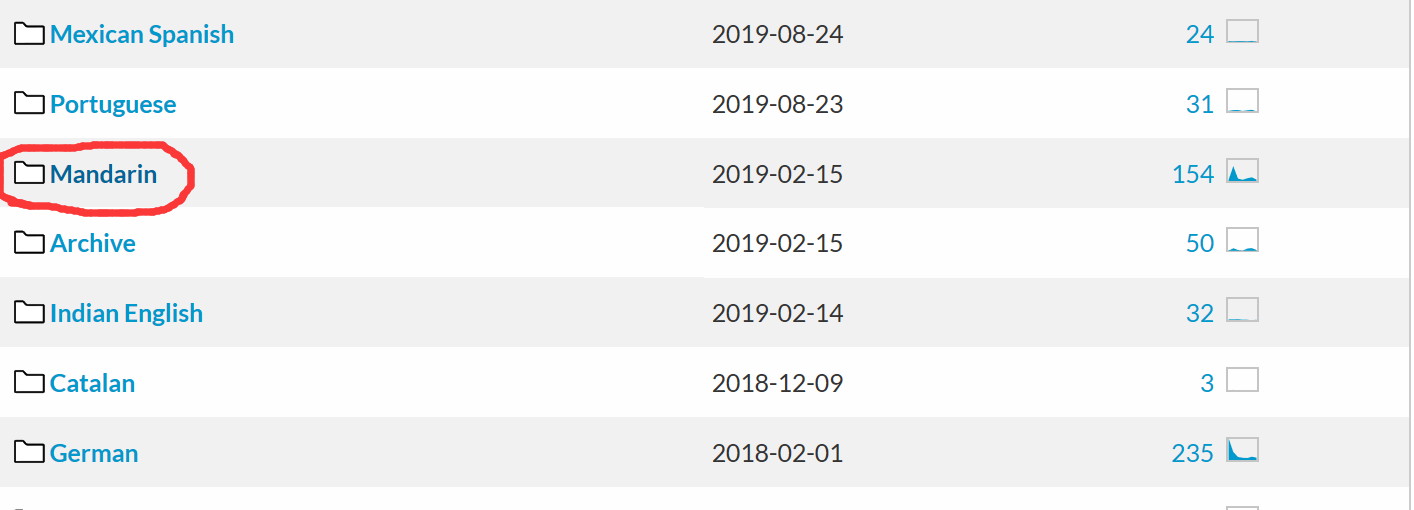
图片中标记的就是普通话!下载相关的语音识别工具包。
但是我们要把zh_broadcastnews_64000_utf8.DMP转化成language-model.lm.bin,再解压zh_broadcastnews_16k_ptm256_8000.tar.bz2得到zh_broadcastnews_ptm256_8000文件夹。
借鉴刚才那位博主的方法,在Ubuntu下找到speech_recognition文件夹。可能会有很多小伙伴找不到相关的文件夹,其实是在隐藏文件下。大家可以点击文件夹右上角的三条杠。如下图所示:

然后给显示隐藏文件打个勾,如下图所示:
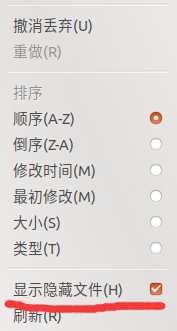
然后依次按照以下目录就可以找到啦:

然后把原来的en-US改名成en-US-bak,新建一个文件夹en-US,把解压出来的zh_broadcastnews_ptm256_8000改成acoustic-model,把chinese.lm.bin改成language-model.lm.bin,把pronounciation-dictionary.dic改后缀成dict,复制这三个文件到en-US里。同时把原来en-US文件目录下的LICENSE.txt复制到现在的文件夹下。
最终该文件夹下有以下文件:
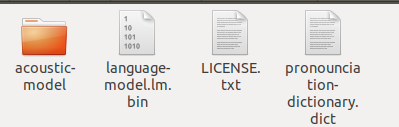
然后我们就可以通过麦克风录入一个语音文件文件(“test.wav”)
在该文件目录下打开python解释器输入以下内容:
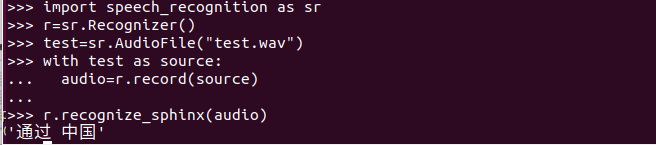
就看到了输出内容,但是我说的是两个中国,也测试了一下其他的发现识别效果很不好!!!
当然有好多同学可能想要语音包,我就分享给大家啦!(链接:https://pan.baidu.com/s/13DTDnv_4NYbKXpkXAXODpw
提取码:zh39)
小范围中文识别
用官方提供的效果太差,几乎不能用!那么我看了很多文章以后就想到了一种优化方法,但是只适合小范围的识别!一些命令啥的应该没有问题,但是聊天什么的可能就效果不太好。
找到刚才复制的4个文件夹,有一个pronounciation-dictionary.dict的文件夹,打开以后是以下内容:

感觉这内容就是类似于一个字典,很多用词和平时交流的用词差距比较大。那么我们改成我们习惯的用词就可以啦! 抱着试一试的想法,结果还真的可以。识别效果真的不错!
我的做法是:
(1)把图片中红色标记以上的内容继续保留,红色以下的内容删除掉。当然处于保险考虑建议大家给该文件备份一下!
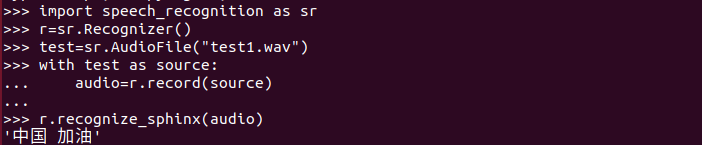
(2)给红色线以下输入自己想识别的内容!(按照规则输入,不同于拼音!!!)最近新型肺炎的情况不断的变好,听到最多的一句话就是“中国加油”那么今天的内容就是将“中国加油”实现语音转文字!希望能早日开学,哈哈哈哈。

3)输入以下内容:
语音合成
语音合成个人的理解就是文字转语音。不过这句话中可以设置client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('你好百度', 'zh', 1, { 'vol': 5,'spd': 3,'pit':9,'per': 3})音量、声调、速度、男/女/萝莉/逍遥。大家快去尝试合成一下吧!最后来欣赏一下语音合成后4种不同风格的语音,你更喜欢那一款呢?
以上就是Linux下利用python实现语音识别详细教程的详细内容,更多关于Linux利用python实现语音识别的资料请关注服务器之家其它相关文章!
原文链接:https://wlybsy.blog.csdn.net/article/details/104586902
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。