Linux平台下生成C语言数据结构关系图

作为一名Linux系统下的C语言开发,经常需要阅读源码,但是有些源码实在是难以阅读,各种庞大的结构体交杂,分分钟把你绕晕,让你头昏眼花,迟迟无法梳理清楚。这时候,一个能够帮你梳理数据结构的工具就显得极其重要,让你能够很清晰的看出各个数据结构之间的关系。
本文我们主要介绍CentOS平台下通过python和graphviz生成数据结构关系图。
一、前置条件
为使用python和graphviz生成C语言的数据结构关系图,需提前安装好python3,这里不做介绍。这里介绍一下绘图工具graphviz和Linux命令行打开图片的工具eog等。
1、安装绘图工具graphviz
Graphviz(Graph Visualization Software)是一个由AT&T实验室启动的开源工具包,能够支持基于 DOT 脚本,文件扩展名通常是 .gv 或 .dot 的描述绘制图形。DOT 是一种文本图形描述语言,将生成的图形转换成多种输出格式的命令行工具,其输出格式包括PostScript,PDF,SVG,PNG,含注解的文本等。DOT 本身非常原始,提供了一种非常简单的描述图形的方法,同时意味着可以在命令行终端使用,或者被其它编程语言调用(Graphviz 就可以作为一个库使用)。这一点非常关键,基于 Graphviz 应用开发者不必掌握布局的复杂算法,而是可以把精力放在业务方面,将最后的图对象交给绘图引擎来处理即可。
yum install graphviz -y2、安装命令行图片查看工具
GNOME之眼,图像查看器(eog)是GNOME桌面的官方图像查看器,可以用来在服务器端查看图片。它可以查看各种格式的单个图像文件,以及大型图像集合。eog可以通过插件系统进行扩展。
yum install eog -y二、生成工具及使用方法
绘制关键数据结构的关联关系图,可以协助我们快速理解组织架构,加速理解代码逻辑;Linux平台下生成C语言数据结构关系图主要基于python+graphviz,python和graphviz工具是基础,需要辅助以python脚本,才能实现分析数据结构并生成用于绘图的dot语言;之后利用graphviz根据上一步中的临时生成文件的dot语言描述绘图。图形保存到xxx.svg文件中,.svg可以使用eog或者浏览器打开。
1、Python脚本分析工具
用于分析结构体关联关系的python脚本(analysis_dt.py),如下:
#!/usr/bin/python3
import os,re
prefix = '''digraph spdk {
graph [
rankdir = "LR"
//splines=polyline
//overlap=false
];
node [
fontsize = "16"
shape = "ellipse"\r
];
edge [
];
'''
middle_str = ''
edge_list = []
edge_string = ''
cur_indentation_level = 0
space4 = ' '
space8 = space4 + space4
space12 = space4 + space8
space16 = space4 + space12
node_database = {}
node_database['created'] = []
color_arrary = ['red', 'green', 'blue', 'black','blueviolet','brown', 'cadetblue','chocolate','crimson','cyan','darkgrey','deeppink',data_struct
with open(r'/tmp/713/data_struct', 'r') as file_input:
tmpline = file_input.readline()
while(tmpline):
tmpline = re.sub(r'([^a-zA-Z0-9]const )', ' ', tmpline)
#for match :struct device {
if re.search(r'struct\s*([0-9a-zA-Z_\-]+)\s*\{', tmpline):
m = re.search(r'struct\s*([0-9a-zA-Z_\-]+)\s*\{', tmpline)
cur_indentation_level += 1
if (cur_indentation_level == 1):
node_name = m.group(1)
node_str = space4 + '\"' + node_name + '\" [\n' + space8 + 'label = \"<head> '+ node_name +'\l|\n' + space12 + '{|{\n'
node_database['created'].append(node_name)
try:
node_database[node_name]['node_str'] = node_str
except:
node_database[node_name] = {}
node_database[node_name]['node_str'] = node_str
#for match :struct device *parent;
elif re.search(r'struct\s*([0-9a-zA-Z_\-]+)\s*(\**)(\s*)([0-9a-zA-Z_\-]+)\s*;', tmpline) and cur_indentation_level > 0:
m = re.search(r'struct\s*([0-9a-zA-Z_\-]+)\s*(\**)(\s*)([0-9a-zA-Z_\-]+)\s*;', tmpline)
member_type = m.group(1)
node_database[node_name]['node_str'] += space16 + '<'+ member_type + '> ' + m.group(2) + m.group(3) + m.group(4) + '\l|\n'
try:
node_database[member_type]['included_by'].append(node_name)
except:
try:
node_database[member_type]['included_by'] = []
node_database[member_type]['included_by'].append(node_name)
except:
node_database[member_type] = {}
node_database[member_type]['included_by'] = []
node_database[member_type]['included_by'].append(node_name)
#print('%s included by %s'%(member_type, node_database[member_type]['included_by']))
if(member_type in node_database['created']):
tmp_edge_str = space4 + node_name + ':' + member_type + ' -> ' + member_type + ':' + 'head'
if not tmp_edge_str in edge_list:
edge_list.append(tmp_edge_str)
#for match : void *driver_data;
elif re.search(r'\s*[0-9a-zA-Z_\-]+\s*(\**[0-9a-zA-Z_\-]+)\s*;', tmpline) and cur_indentation_level > 0:
m = re.search(r'\s*[0-9a-zA-Z_\-]+\s*(\**[0-9a-zA-Z_\-]+)\s*;', tmpline)
node_database[node_name]['node_str'] += space16 + '<'+ m.group(1) + '> ' + m.group(1) + '\l|\n'
#for match:const char *init_name;
elif re.search(r'(.*)\s+(\**)(\s*)([0-9a-zA-Z_\-]+\s*);', tmpline) and cur_indentation_level > 0:
m = re.search(r'(.*)\s+(\**)(\s*)([0-9a-zA-Z_\-]+\s*);', tmpline)
node_database[node_name]['node_str'] += space16 + '<'+ m.group(2) + '> ' + m.group(2) + m.group(3) + m.group(4) + '\l|\n'
#for match:int *(*runtime_idle)(struct device *dev);
elif re.search(r'\s*[0-9a-zA-Z_\-]+\s*\**\s*\(\s*(\**\s*[0-9a-zA-Z_\-]+)\s*\)\s*\([^\)]*\)\s*;', tmpline) and cur_indentation_level > 0:
m = re.search(r'\s*[0-9a-zA-Z_\-]+\s*\**\s*\(\s*(\**\s*[0-9a-zA-Z_\-]+)\s*\)\s*\([^\)]*\)\s*;', tmpline)
node_database[node_name]['node_str'] += space16 + '<'+ m.group(1) + '> (' + m.group(1) + ')\l|\n'
#for match: };
elif re.search(r'\s*\}\s*;', tmpline):
if(cur_indentation_level >= 1):
cur_indentation_level -= 1
if (cur_indentation_level == 0):
node_database[node_name]['node_str'] += space12 + '}}\"\n'
node_database[node_name]['node_str'] += space8 + 'shape = \"record\"\n' + space4 + '];\n'
if 'included_by' in node_database[node_name]:
for parent_node in node_database[node_name]['included_by']:
if parent_node in node_database['created']:
tmp_edge_str = space4 + parent_node + ':' + node_name + ' -> ' + node_name + ':' + 'head'
if not tmp_edge_str in edge_list:
edge_list.append(tmp_edge_str)
tmpline = file_input.readline()
for tmpnode in node_database['created']:
middle_str = middle_str + node_database[tmpnode]['node_str']
for i, tmpstr in enumerate(edge_list):
edge_string += tmpstr + '[color="' + color_arrary[i%len(color_arrary)] + '"]\n'
print(prefix + middle_str + '\n' + edge_string + '}')2、使用方法
绘制C语言结构体关系图方法和流程如下:
(1)把需要绘制关系图的关键数据结构复制粘贴到一个文本文件data_struct中;
(2)把python脚本中保存数据结构的文件路径(/tmp/713/data_struct )替换为自己的保存数据结构的文件路径(可自行修改脚本,通过参数传入文件路径);
(3)执行命令,自动生成关系图,命令如下:
python3 analysis_dt.py > tmpfile
dot -Tsvg tmpfile -o xxx.svg其中第一条命令使用python分析数据结构并生成用于绘图的dot语言,第二条命令利用graphviz根据tmpfile中的dot语言描述绘图。图形保存到xxx.svg文件中,xxx可以自行命名;生成的xxx.svg文件可以在服务器的命令行使用eog打开,也可以下载到windows上使用浏览器打开,且可以实现缩放。
注意:这里也可以通过dot命令直接生成图片格式,如下:
dot -Tsvg tmpfile -o xxx.png 即可生成xxx.png图片。
这里以一个简单的结构体文本文件data_struct为Demo,查看其内结构体之间的关系。data_struct文本文件内容如下:
struct ovsdb {
char *name;
struct ovsdb_schema *schema;
struct ovsdb_storage *storage; /* If nonnull, log for transactions. */
struct uuid prereq;
struct ovs_list monitors; /* Contains "struct ovsdb_monitor"s. */
struct shash tables; /* Contains "struct ovsdb_table *"s. */
/* Triggers. */
struct ovs_list triggers; /* Contains "struct ovsdb_trigger"s. */
bool run_triggers;
bool run_triggers_now;
struct ovsdb_table *rbac_role;
/* History trasanctions for incremental monitor transfer. */
bool need_txn_history; /* Need to maintain history of transactions. */
unsigned int n_txn_history; /* Current number of history transactions. */
unsigned int n_txn_history_atoms; /* Total number of atoms in history. */
struct ovs_list txn_history; /* Contains "struct ovsdb_txn_history_node. */
size_t n_atoms; /* Total number of ovsdb atoms in the database. */
/* Relay mode. */
bool is_relay; /* True, if database is in relay mode. */
/* List that holds transactions waiting to be forwarded to the server. */
struct ovs_list txn_forward_new;
/* Hash map for transactions that are already sent and waits for reply. */
struct hmap txn_forward_sent;
/* Database compaction. */
struct ovsdb_compaction_state *snap_state;
};
struct ovsdb_storage {
/* There are three kinds of storage:
*
* - Standalone, backed by a disk file. 'log' is nonnull, 'raft' is
* null.
*
* - Clustered, backed by a Raft cluster. 'log' is null, 'raft' is
* nonnull.
*
* - Memory only, unbacked. 'log' and 'raft' are null. */
struct ovsdb_log *log;
struct raft *raft;
char *unbacked_name; /* Name of the unbacked storage. */
/* All kinds of storage. */
struct ovsdb_error *error; /* If nonnull, a permanent error. */
long long next_snapshot_min; /* Earliest time to take next snapshot. */
long long next_snapshot_max; /* Latest time to take next snapshot. */
/* Standalone only. */
unsigned int n_read;
unsigned int n_written;
};
struct ovsdb_table {
struct ovsdb_table_schema *schema;
struct ovsdb_txn_table *txn_table; /* Only if table is in a transaction. */
struct hmap rows; /* Contains "struct ovsdb_row"s. */
/* An array of schema->n_indexes hmaps, each of which contains "struct
* ovsdb_row"s. Each of the hmap_nodes in indexes[i] are at index 'i' at
* the end of struct ovsdb_row, following the 'fields' member. */
struct hmap *indexes;
bool log; /* True if logging is enabled for this table. */
};
struct ovsdb_compaction_state {
pthread_t thread; /* Thread handle. */
struct ovsdb *db; /* Copy of a database data to compact. */
struct json *data; /* 'db' as a serialized json. */
struct json *schema; /* 'db' schema json. */
uint64_t applied_index; /* Last applied index reported by the storage
* at the moment of a database copy. */
/* Completion signaling. */
struct seq *done;
uint64_t seqno;
uint64_t init_time; /* Time spent by the main thread preparing. */
uint64_t thread_time; /* Time spent for compaction by the thread. */
};执行结果如下:
[root@localhost 713]# vi analysis_dt.py
[root@localhost 713]# python3 analysis_dt.py > tmpfile
[root@localhost 713]# ls
analysis_dt.py data_struct tmpfile
[root@localhost 713]# vi tmpfile
[root@localhost 713]# dot -Tsvg tmpfile -o my.svg
[root@localhost 713]# ls
analysis_dt.py data_struct my.svg tmpfile
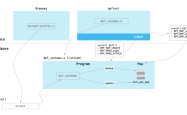
[root@localhost 713]# eog my.svgeog打开my.svg文件,结果如下:
 图片
图片
根据图片可以看出,成功展现了结构体之间的关系。
三、总结
graphviz很强大,可以用来画各种各样的图,本文只是简单总结一下用于画C语言结构体关系的方法,并做一个记录。小编在看代码的时候,一直想着有什么工具可以实现这个功能,检索了一圈,没找到什么很方便的工具。也有人推荐用draw.io,processon等,但是小编觉得这两个工具画结构体关系图终究是没有这种通过脚本工具的方法方便。因此总结成文,希望对有需要的朋友能够有帮助,也希望有更方便的解决方案的朋友可以反馈给小编,大家一起互帮互助,一起成长。
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。