想象我来设计Linux内核内存

哈喽,我是子牙,一个很卷的硬核男人
最近这段时间一直在备课Linux内核的内存模块,每每研究完一小块知识点,我就发自内心的感叹:太复杂了!但是就是这个只要研究过Linux内核内存都会感叹复杂的玩意,已存在了30多年(从Linux2.3引入,时间大概是1999年),可想而知这套内存模块设计的有多优秀!
我也问了下ChatGPT,这30多年来,这座当今科技世界的地基Linux内核的核心:内存模块,经历了哪些变化。
 图片
图片
看完了我久久不能平静!不是激动,是愁哇:这么复杂的玩意,我怎么教别人才能听得懂消化得了呢?早上突发奇想:不如换个思维,如果我们来设计Linux内核内存模块,我们会怎么去做呢?将自己代入,去了解大师的杰作,应该会有意想不到的效果吧!
OK,起笔,成文。愿你enjoy
一、内存管理算法
我问了下ChatGPT:历史上存在的管理大块内存的算法有哪些,它给的答案:
 图片
图片
先说内存池,这个是离大家最近的。如果你研究过底层项目如Java虚拟机、Python虚拟机、Redis、MySQL……里面一定会用到内存池,可以减少对OS内存的申请与释放,提升性能。通过垃圾回收线程回收内存或者完成内存规整,减少内存碎片。不过这个算法是依托OS内存实现的,我们如果要实现OS,这个用不了。
456提到的段页,是硬件层面提供的,即CPU层面的段机制与页机制,很早以前是通过段页来管理大块内存,因为那时候内存不大,自32位CPU以后,就不再使用这几种方式管理内存了。想研究明白的小伙伴可自行研究或者学习我的手写OS课程,里面有教。
位图跟链表,在不考虑非常复杂的场景的情况下,其实是最好的选择。我着重讲讲位图,我自己写的OS就是使用的位图,对链表感兴趣的自行研究。
 图片
图片
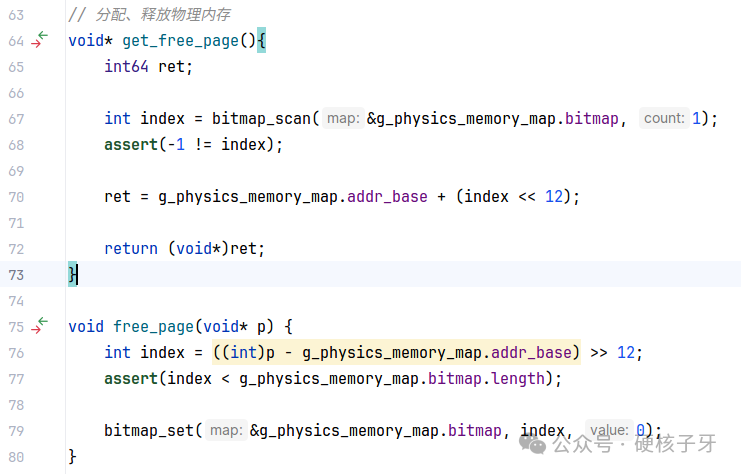
位图的核心思想是:一个比特映射一个4K物理页,一个比特两个值:0跟1,如果这个4K页是空闲的,对应的比特位置0,如果这个4K页分配出去了,这个比特位置为1。
 图片
图片
如果位图十全十美,就没有伙伴系统算法存在的必要了,那位图的缺陷是什么呢?这就要说到,优秀的内存管理算法的职责是什么:大块内存环境下,可以高效的分配内存;内存不够的时候,支持异步回收;内存极度紧张的时候,支持同步回收;支持内存规整,合并内存碎片;还有留有扩展余地,支持硬件的不断更新,比如当前内存条的热插拔……
来看看位图的优缺点:
 图片
图片
那Linux内核中有没有用位图呢?用了!在伙伴算法未完成初始化之前,一直用的是位图。即在未执行完paging_init函数前,使用的是bootmem分配器,它的底层就是位图。
接下来咱们就讲今天的重头戏:伙伴系统+Slab分配器。
二、页帧(page frame)
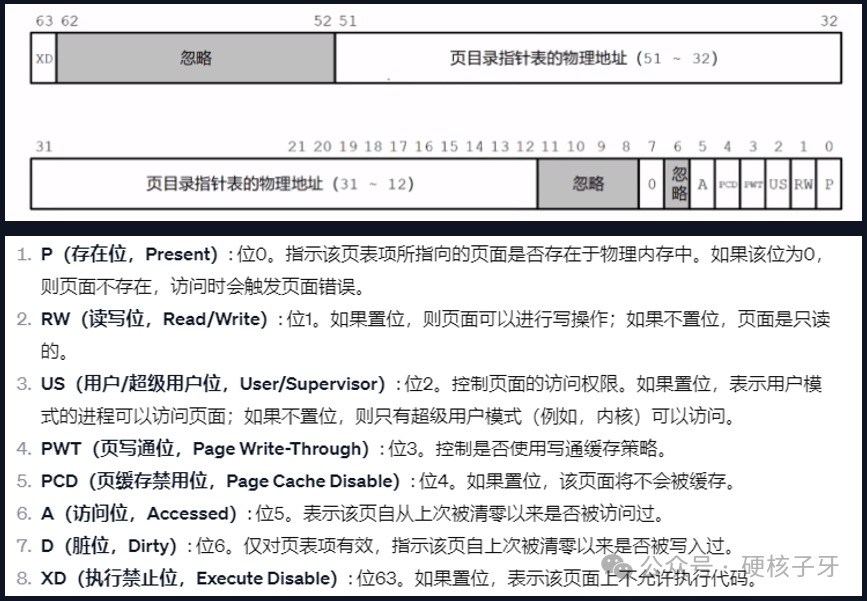
Linux内核中对内存的控制,除了实现了硬件层面的,还有软件层面的。硬件层面的,控制位在实现页表的时候就已经实现了。
 图片
图片
那软件层面的控制位保存在哪里呢?Linux内核引入了所谓的页帧,即每个4K物理页,在Linux内核中都有一个page对象与之一一对应。这个page对象,描述了一个4K页的信息如:匿名页还是文件页、page cache对应文件信息、私有还是共享、已被分配还是空闲、是否是脏页、被映射的次数及映射到哪些进程的页表中……
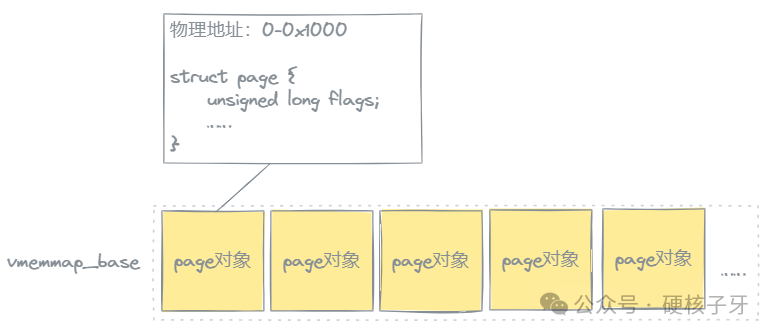 图片
图片
三、伙伴系统结构
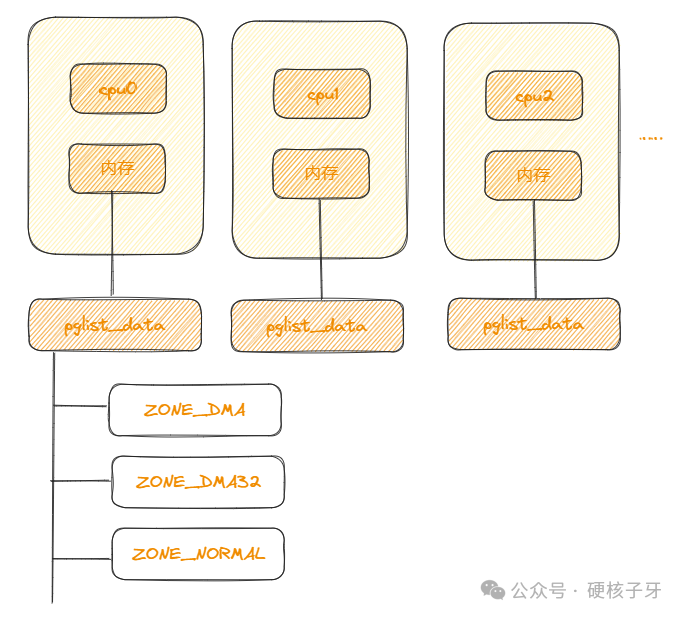
伙伴系统结构,简而言之就是:Linux内核用一个pglist_data对象描述一个NUMA节点,用N个zone对象分区管理NUMA节点中的内存,用前面提到的page对象管理每一个4K物理页,如图:
 图片
图片
每个NUMA节点中的内存称为本地内存,与之相邻的节点称为相邻节点,cpu1所在的NUMA节点比cpu2所在的NUMA节点离cpu0所在的NUMA节点更近,所以在某些分配策略下,cpu0所在的NUMA节点内存耗尽,就会优先从cpu1所在节点分配,以此内推……这些都是理解伙伴系统很重要的知识点。
总结一下:Linux内核是基于NUMA架构实现的,每一个NUMA节点,内核中都有一个pglist_data对象与之对象。每个NUMA节点中的内存,都会用N个zone进行管理,64位Linux,最多会有三个zone:ZONE_DMA、ZONE_DMA32、ZONE_NORMAL。每个4K物理页,内核中都有一个page对象与之对应,描述其相关使用信息及控制信息。
伙伴系统最终的结构长什么样呢?如图:
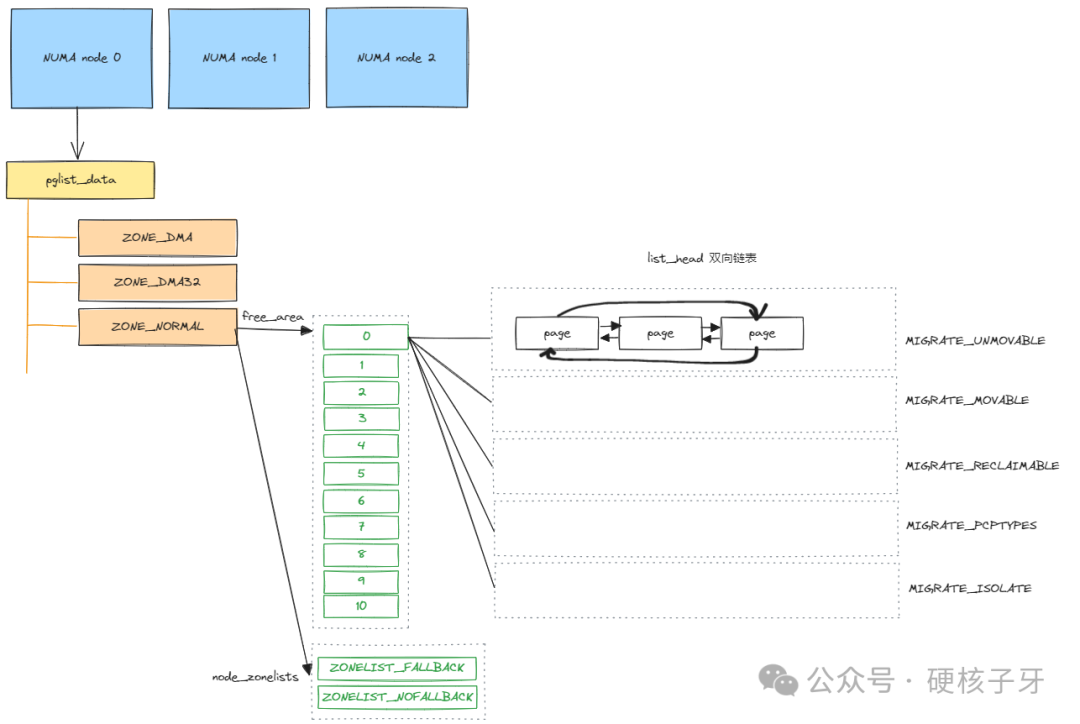 图片
图片
四、分配内存
现在结构有了,我们要写分配内存的函数了,要怎么写呢?比如我要5个4K物理页。
首先,肯定是定位我要在哪个NUMA节点上分配内存,这在Linux内核中对应的就是mempolicy。可选的方案有:
- 当前运行代码的CPU所在的NUMA节点,根据该NUMA节点内存耗尽的处理策略衍生出两个分配策略:default policy、local policy。默认策略(default policy)的方案是内存不足,会经过运算选择合适的NUMA节点去要内存。局部策略(local policy)的方案是分不到内存就死给你看
- Linux内核支持绑定一个进程到某个NUMA节点,意味着这个进程只有分配内存都是从这个NUMA节点分配,如果分配不到就会经历内存规整、同步回收、MEM killer、OOM。对应的策略就是绑定策略(bind policy)
- Linux内核支持你配置一个NUMA节点作为优先分配节点,因为所有的进程都优先在这个NUMA节点上分配内存,所以耗尽是迟早的事,如果耗尽了,就会经过运算从其他NUMA节点分配内存,这个策略就是首选策略(preferred policy),这个也是Linux内核的默认策略
- 咱们中国讲究中庸对吧,没想到国外也信奉这个,对于的策略是远程策略(interleave policy),即在所有的NUMA节点上均匀分配内存,这个也是创建进程的默认策略。言外之意,如果不后期配置,我们创建的进程的内存分配策略是在所有NUMA节点中均匀分配
现在我们选定了NUMA node0,接下来就要去选择zone了:
- 受上面讲的选择NUMA节点对应的分配策略影响,选择zone会考虑首选节点及备选节点,对应的就是ZONELIST_FALLBACK、ZONELIST_NOFALLBACK。一般用的都是ZONELIST_FALLBACK,当前NUMA节点分不到内存,去其他NUMA节点分配。default policy、preferred policy、interleave policy对应的是它
- 每个NUMA节点最多会有3个ZONE,比如64位Linux内核对应的ZONE;DMA、DMA32、NORMAL,那选择zone时可以指定在哪个ZONE中分配。如果不指定的话,默认是从NORMAL中分配。那都从NORMAL中分配,这个ZONE会很快用光的,但是其他ZONE如DMA、DMA32还是空闲的,所以Linux内核引入了降级机制(或者叫回退机制),即NORMAL分配不到内存了,去当前NUMA节点的低端内存去分配内存。但是DMA、DMA32也要考虑给DMA预留内存,不能帮助高端内存把自己区域内存耗尽,就有了lowmem_reserve
- 如果NORMAL分配不到内存,一开始是不会采用回退机制,想想也不合理对吧,就像你缺钱,你不可能一上来就去借钱,肯定想到的是家里有啥能卖的先给卖了,不够再说,Linux内核也是同样的逻辑,先回收,回收不到再说。那合适触发回收呢?是同步回收还是异步回收?要不要触发killer、OOM?这些都是由水位线(watermark)决定的,之前写过这方面的文章 传送门
现在zone也选中了:NORMAL,接下来就是真正的去拿物理页了。如何拿物理页呢?这里门道也蛮多的。想出这套算法的人,真乃奇才!把这套算法完美的实现出来的人,也不简单。
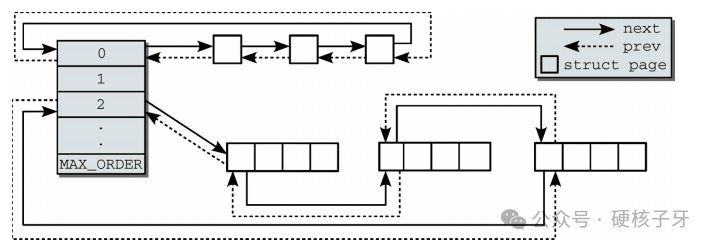
要想理解如何拿物理页,得知道伙伴系统底层是如何管理物理页的。每个ZONE中有一个数组free_area用来管理物理页,这个数组有12个元素,每个元素是个链表,数组下标就是阶,比如index=0对应的链表中的每个元素就是一个4K物理页,index=1对应的链表中的每个元素就是两个4K物理页,以此类推。
 图片
图片
回答最初的问题:如何拿到5个4K物理页呢,就是去index=3对应的链表中去分配。如果这个链表中是空的呢?那就往上找index=4的,index=4对应的链表中每个元素是16个4K物理页,会将这个元素拆成两个元素放到index=3的链表中,然后去分配。至此,就完成了内存分配。
对了,为了提升内存分配速度,Linux内核中还引入了PCP,即Per-CPU Pages,每个CPU都有自己的一组本地缓存页(pages),这些页可以被该CPU上运行的进程快速分配和回收,而不需要加锁操作,从而减少了对全局内存池的争用,提高了性能。但是只有当分配一个4K页的时候,才从PCP中分配。
总结来说,在NUMA节点环境下要想拿到物理内存,得先确定从哪个NUMA节点拿,再确定在选定的NUMA节点中的哪个ZONE中去拿,最后确定要怎么拿,这条线是主线,理解了这条主线,再结合Linux内核提供的机制,你就能理解完整的Linux内核内存模块。
这就是内存的全部吗?当然不是!还有很多很多:slab、匿名页、文件页、页回收、页迁移、vma、反向映射…但是你先得非常了解本文分享的这些,你才能理解后面的那些,本文分享的这些,是Linux内核内存模块基础中的基础。
原文地址:https://mp.weixin.qq.com/s/09kLo-G1dnvy0ollPy0b3g
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。