
mysql实现合并结果集并去除重复值

mysql 合并结果集并去除重复值
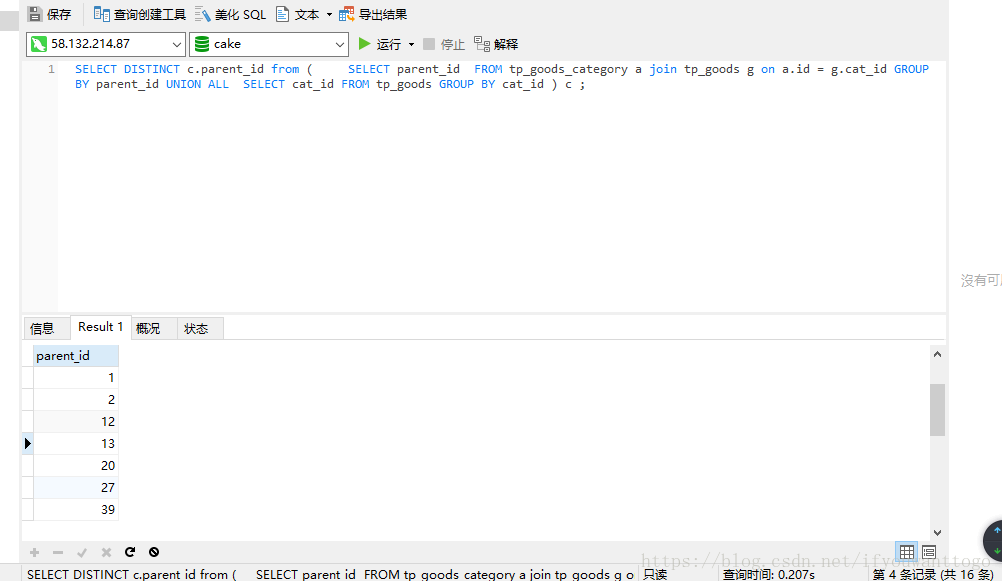
SELECT DISTINCT c.parent_id from ( SELECT parent_id FROM tp_goods_category a join tp_goods g on a.id = g.cat_id GROUP BY parent_id UNION ALL SELECT cat_id FROM tp_goods GROUP BY cat_id ) c;
先去除每个结果集中的重复值 以 group by 方式除去
SELECT parent_id FROM tp_goods_category a join tp_goods g on a.id = g.cat_id GROUP BY parent_id SELECT cat_id FROM tp_goods GROUP BY cat_id
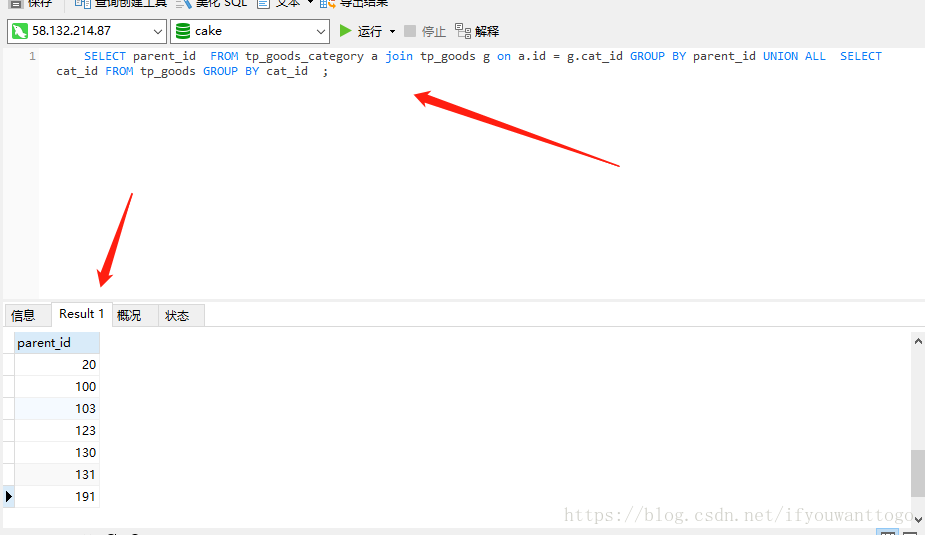
然后合并两个结果集 生成一个新的结果集 (或者可以成为新表) 在 使用DISTINCT 去除合并结果集中的重复值 注意 必须给 新结果集取一个别名 比如例子中的 c

新的查询结果
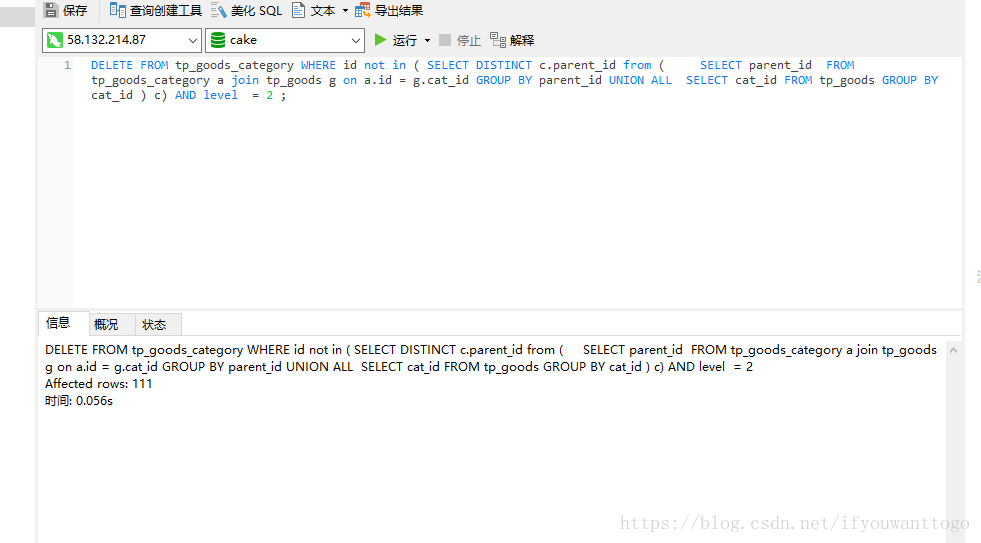
此语句为了删除分类表中 在goods表中不存在的 分类id 且 级别为第二级别
mysql 合并结果集(union,union all)
我需要在一个sql的执行结果中,显示两个或两个以上的where条件的结果(select 列的结构相同)。
考虑使用union,或union all 。
union 与 union all 执行结果不同
UNION 删除重复的记录再返回结果,即对整个结果集合使用了DISTINCT。结果中无重复数据。
UNION ALL 将各个结果合并后就返回,不删除重复记录。如果结果中有重复数据,则包含重复数据。
例如,
mysql> SELECT * FROM world.city where ID=2020 UNION SELECT * FROM world.city where ID=2020; +------+-------+-------------+--------------+------------+ | ID | Name | CountryCode | District | Population | +------+-------+-------------+--------------+------------+ | 2020 | Tieli | CHN | Heilongjiang | 265683 | +------+-------+-------------+--------------+------------+ 1 row in set (0.00 sec) mysql> SELECT * FROM world.city where ID=2020 UNION ALL SELECT * FROM world.city where ID=2020; +------+-------+-------------+--------------+------------+ | ID | Name | CountryCode | District | Population | +------+-------+-------------+--------------+------------+ | 2020 | Tieli | CHN | Heilongjiang | 265683 | | 2020 | Tieli | CHN | Heilongjiang | 265683 | +------+-------+-------------+--------------+------------+ 2 rows in set (0.00 sec)
对UNION,UNION ALL的结果继续处理,需要加括号
比如要对合并后的结果集进行ORDER BY,LIMIT等操作需要对合并对象单个的SELECT语句加上括号。
并且把整体结果的条件ORDER BY,LIMIT等放到最后一个SELECT的括号后面。
例如,
(SELECT * FROM world.city WHERE CountryCode = "JPN" AND Name LIKE "nishi%") UNION ALL (SELECT * FROM world.city WHERE CountryCode = "CHN" AND Population >= 5000000) LIMIT 5;
mysql中,UNION,UNION ALL的性能/效率不同
从效率上说,UNION ALL 要比UNION快很多。
所以,如果可以确认合并的结果集中不包含重复的数据的话,或者需要的结果中即使包含重复也无所谓,那么就使用UNION ALL。
UNION
- UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算。
- UNION在运行时先取出各个表/各个select的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
UNION ALL
- UNION ALL只是简单的将结果合并后就返回。不涉及排序运算。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持服务器之家。
原文地址:https://blog.csdn.net/ifyouwanttogo/article/details/80928816
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









