
MySQL 分库分表的项目实践

一、为什么要分库分表
数据库架构演变
刚开始多数项目用单机数据库就够了,随着服务器流量越来越大,面对的请求也越来越多,我们做了数据库读写分离, 使用多个从库副本(Slave)负责读,使用主库(Master)负责写,master和slave通过主从复制实现数据同步更新,保持数据一致。slave 从库可以水平扩展,所以更多的读请求不成问题
但是当用户量级上升,写请求越来越多,怎么保证数据库的负载足够?增加一个Master是不能解决问题的, 因为数据要保存一致性,写操作需要2个master之间同步,相当于是重复了,而且架构设计更加复杂
这时需要用到分库分表(sharding),把库和表存放在不同的MySQL Server上,每台服务器可以均衡写请求的次数
二、库表太大产生的问题
- 单库太大:单库处理能力有限、所在服务器上的磁盘空间不足、遇到IO瓶颈,需要把单库切分成更多更小的库
- 单表太大:CURD效率都很低、数据量太大导致索引文件过大,磁盘IO加载索引花费时间,导致查询超时。所以只用索引还是不行的,需要把单表切分成多个数据集更小的表。MyCat提供的分表算法都在rule.xml,可以根据不同的分表算法进行拆分,比如根据时间拆分、一致性哈希、直接用主键对分表的个数取模等
拆分策略
单个库太大,先考虑是表多还是数据多:
- 如果因为表多而造成数据过多,则使用垂直拆分,即根据业务拆分成不同的库
- 如果因为单张表的数据量太大,则使用水平拆分,即把表的数据按照某种规则(rule.xml定义的分表算法)拆分成多张表
分库分表的原则应该是先考虑垂直拆分,再考虑水平拆分
三、垂直拆分
分库分表和读写分离可以共同进行
1. 垂直分库
server.xml
<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB1,USERDB2</property> </user>
配置了USERDB1、USERDB2这两个逻辑库
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB1" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1" /> <!-- 两个逻辑库对应两个不同的数据节点 --> <schema name="USERDB2" checkSQLschema="false" sqlMaxLimit="100"dataNode="dn2" /> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <!-- 两个数据节点对应两个不同的物理机器 --> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- USERDB1对应mytest1,USERDB2对应mytest2 --> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
两个逻辑库对应两个不同的数据节点,两个数据节点对应两个不同的物理机器
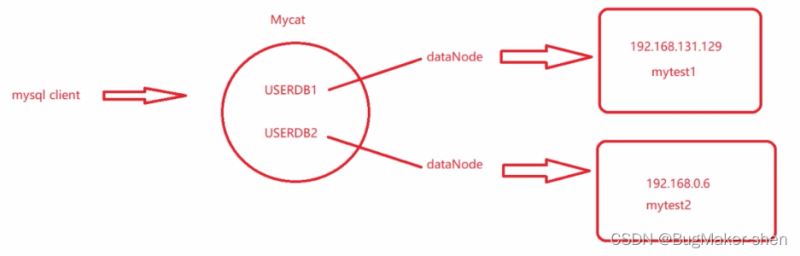
mytest1和mytest2分成了不同机器上的不同的库,各包含一部分表,它们原来是合在一块的,在一台机器上,现在做了垂直的拆分。
客户端就需要去连接不同的逻辑库了,根据业务操作不同的逻辑库
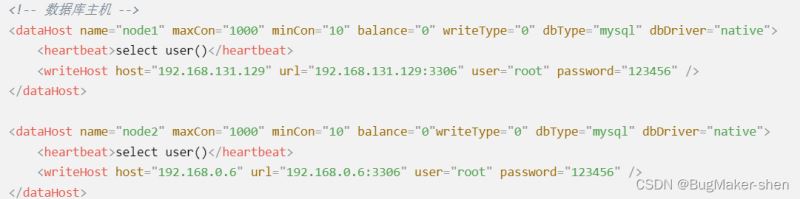
然后配置了两个写库,两台机器把库平分了,分担了原来单机的压力。分库伴随着分表,从业务上对表拆分
2. 垂直分表
垂直分表,基于列字段进行。一般是针对几百列的这种大表,也避免查询时,数据量太大造成的“跨页”问题。
一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到扩展表。访问频率较高的字段单独放在一张表
四、水平分库分表
针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE、HASH取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈,不建议采用
将单张表的数据切分到多个服务器上去,每个服务器具有一部分库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈
分库分表可以和主从复制同时进行,但不基于主从复制;读写分离才基于主从复制
server.xml
<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB</property> </user>
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB" checkSQLschema="false" sqlMaxLimit="100"> <table name="user" dataNode="dn1" /> <!-- 这里的user和student都是实际存在的物理表名 --> <table name="student" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long"/> </schema> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
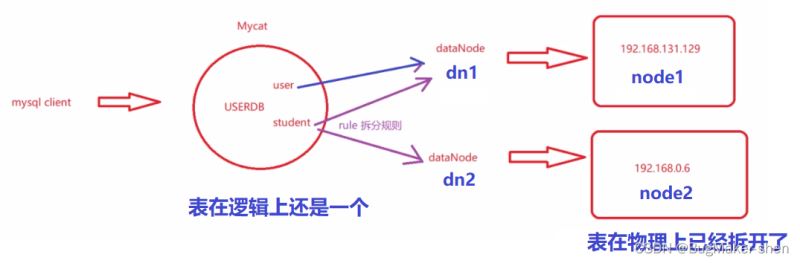
user表示一个普通的表,直接放在数据节点dn1上,放在一台机器上,这张表不用进行拆分
student表的primaryKey是id,根据id拆分,放在dn1和dn2上,最终这个表要分在两台机器上,在物理上分开了,但是在逻辑上还是一个,往哪张表里增加,在2台机器上查询然后如何合并这些操作都是由mycat完成的
拆分的规则是取模(mod - long),每次插入用id模上存在的机器数(2)
此外还需要在rule.xml中配置以下拆分算法
找到算法mod-long,因为我们将逻辑表student分开映射到两台主机上,所以修改数据节点的数量为2

2. 测试水平分表
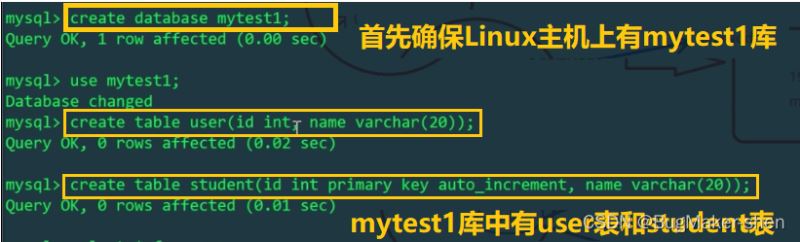
Linux主机
Windows主机
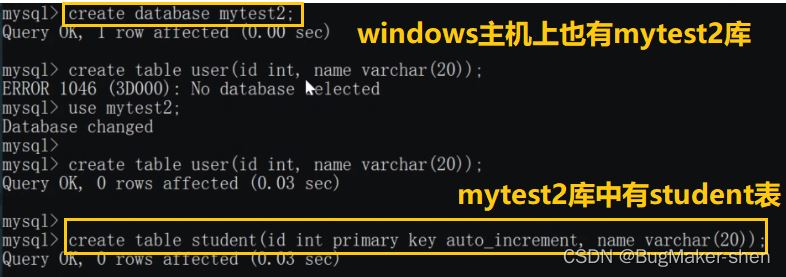
登录到mycat的8066端口
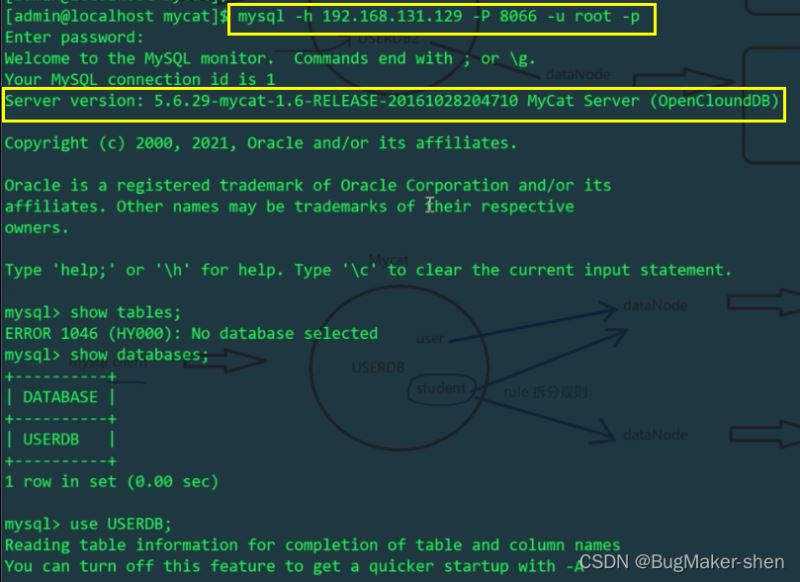
使用MyCat给user表插入两条数据

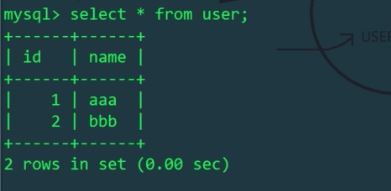
由于schema.xml配置文件中,逻辑表user只在Linux主机的mytest1库中存在,mycat操作的逻辑表user会影响Linux主机上的物理表,而不会影响Windows主机上的表。我们分别查看一下Linux和Windows主机的user表:

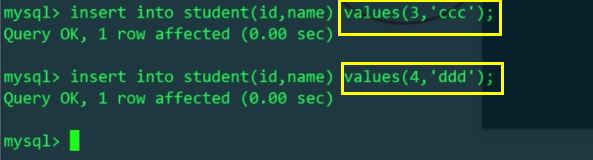
我们再通过MyCat给student表插入两条数据
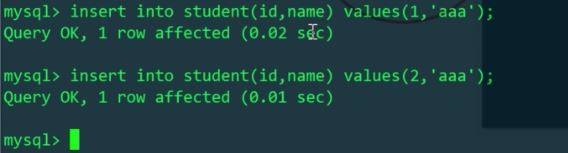
我们知道schema.xml配置文件中,逻辑表student对应两台主机上的两个库mytest1、mytest2中的两张表,所以对逻辑表插入的两条数据,会实际影响到两张物理表(用id%机器数,决定插入到哪张物理表)。我们分别查看一下Linux和Windows主机的student表:
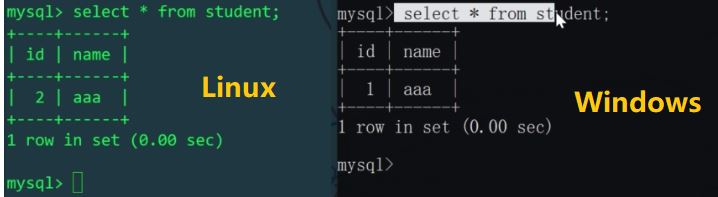
再通过MyCat插入id=3和id=4的数据,应该插入不同主机上的不同物理表
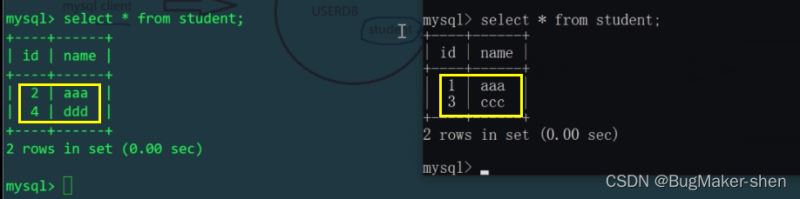
这就相当于把student表进行水平拆分了
通过MyCat查询的时候只需要正常输入就行,我们配置的是表拆分后放在这2个数据节点上,MyCat会根据配置在两个库上查询并进行数据合并
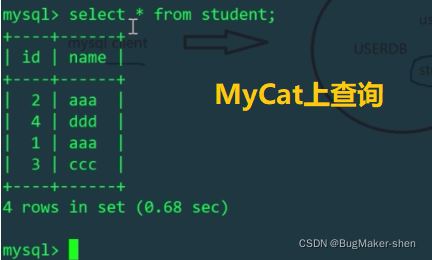
到此这篇关于MySQL 分库分表的项目实践的文章就介绍到这了,更多相关MySQL 分库分表内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文地址:https://blog.csdn.net/qq_42500831/article/details/124006319
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








