
面试官:谈谈你对索引的认知系列之B-树


写在前面
对于MySQL索引,相信每位后端同学日常工作中经常会用到,但是对其索引原理,却可能未曾真正深入了解,导致在面试过程中,回答不出重点那就可能要与机会说byebye了。
面试官:MySQL的索引实现是用什么数据结构?
你:好像是B+树吧
面试官:为什么要用B+树,而不是B-树?
你:...
面试官:用B+树实现索引结构,有什么好处?
你:...
B-树和B+树是MySQL索引使用的数据结构,对于索引优化和原理理解都非常重要,下面就揭开B-树和B+树的神秘面纱,让大家在面试的时候碰到这个知识点一往无前,不再成为你前进的羁绊!
B-树 简介
B-树,这里的 B 表示 balance( 平衡的意思),B-树是一颗多路平衡查找树,它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。
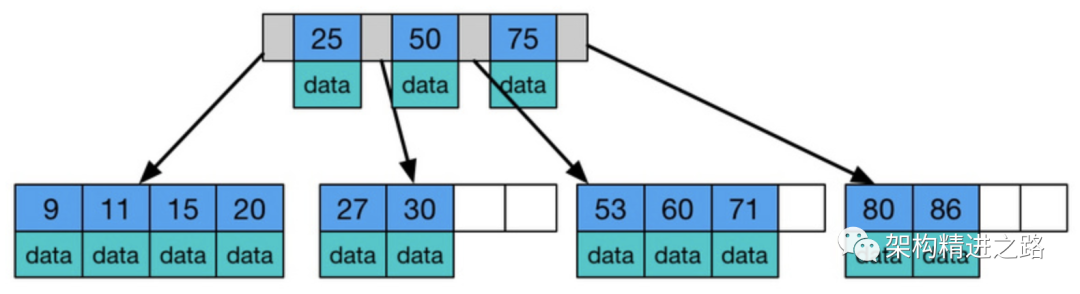
从上图B-树的简化图,我们可以发现几个显著特点:
- 所有键值分布在整颗树中(索引值和具体data都在每个节点里),叶节点具有相同的深度;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束(最好情况O(1)就能找到数据);
- 在关键字全集内做一次查找,性能逼近二分查找
平衡二叉树 VS B-树
我们知道传统用来搜索的平衡二叉树有很多,如 AVL 树,红黑树等。
这些树在一般情况下查询性能非常好,但当数据非常大的时候它们就无能为力了。原因当数据量非常大时,内存不够用,大部分数据只能存放在磁盘上,只有需要的数据才加载到内存中。一般而言内存访问的时间约为 50 ns,而磁盘在 10 ms 左右。速度相差了近 5 个数量级,磁盘读取时间远远超过了数据在内存中比较的时间。这说明程序大部分时间会阻塞在磁盘 IO 上。
那么我们如何提高程序性能呢?
- 平衡二叉树
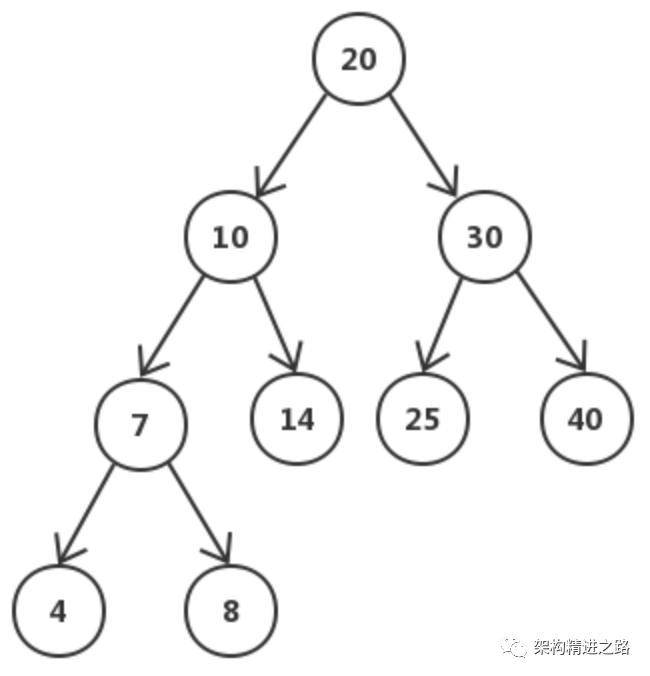
平衡二叉树 是通过旋转来保持平衡的,而旋转是对整棵树的操作,若部分加载到内存中则无法完成旋转操作。其次平衡二叉树的高度相对较大为 log n(底数为2),这样逻辑上很近的节点实际可能非常远,无法很好的利用磁盘预读(局部性原理)。
空间局部性原理:如果一个存储器的某个位置被访问,那么将它附近的位置也会被访问。
- B-树
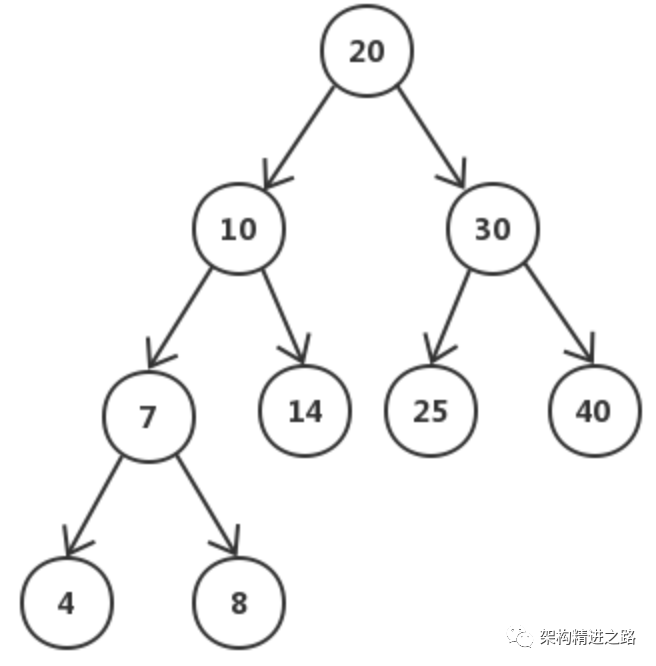
B-树多叉的好处非常明显,有效的降低了B-树的高度(为底数很大的 log n,底数大小与节点的子节点数目有关,一般一棵B-树的高度在 3 层左右)。层数低,每个节点区确定的范围更精确,范围缩小的速度越快(比二叉树深层次的搜索肯定快很多)。上面说了一个节点需要进行一次 IO,那么总 IO 的次数就缩减为了 log n 次。
B-树的每个节点是 n 个有序的序列(a1,a2,a3… an),并将该节点的子节点分割成 n+1 个区间来进行索引(X1< a1, a2 < X2 < a3, … , an+1 < Xn < anXn+1 > an)。
B-树的查找
我们来看看B-树的查找,假设每个节点有 n 个 key值,被分割为 n+1 个区间,注意,每个 key 值紧跟着 data 域,这说明B-树的 key 和 data 是聚合在一起的。一般而言,根节点都在内存中,B-树以每个节点为一次磁盘 IO。
若搜索 key 为 25 节点的 data,首先在根节点进行二分查找(因为 keys 有序,二分最快),判断 key 25 小于 key 50,所以定位到最左侧的节点,此时进行一次磁盘 IO,将该节点从磁盘读入内存,接着继续进行上述过程,直到找到该 key 为止。
总结
索引的效率依赖于磁盘 IO 的次数,快速索引需要有效的减少磁盘 IO 次数。
Q:那如何实现快速索引呢?
索引的原理其实是不断的缩小查找范围,就如我们平时用字典查单词一样,先找首字母缩小范围,再第二个字母等等。
- 平衡二叉树是每次将范围分割为两个区间;
- B-树每次将范围分割为多个区间,区间越多,定位数据越快越精确。
那么如果节点为区间范围,每个节点就较大了。所以新建节点时,直接申请页大小的空间(磁盘存储单位是按 block 分的,一般为 512 Byte。磁盘 IO 一次读取若干个 block,我们称为一页,具体大小和操作系统有关,一般为 4 k,8 k或 16 k),计算机内存分配是按页对齐的,这样就实现了一个节点只需要一次 IO。
为什么会存在B-树这类结构呢?
任何事物,存在就有其道理。B-树的设计相对平衡二叉树,似乎更“迎合”磁盘的角度。
原文链接:https://mp.weixin.qq.com/s/MvzJJOX-pm9SGIAC8idE1g
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









