
MySql批量插入时如何不重复插入数据

前言
Mysql插入不重复的数据,当大数据量的数据需要插入值时,要判断插入是否重复,然后再插入,那么如何提高效率?解决的办法有很多种,不同的场景解决方案也不一样,数据量很小的情况下,怎么搞都行,但是数据量很大的时候,这就不是一个简单的问题了。
一、insert ignore into
会忽略数据库中已经存在 的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过当前插入的这条数据。这样就可以保留数据库中已经存在数据,达到在间隙中插入数据的目的。
控制器方法:
?| 1 2 3 4 5 6 7 8 | /** * 插入员工数据 */ @PostMapping ( "save" ) @ResponseBody public CommonResult<Employee> save( @RequestBody Employee employee){ return employeeService.saveEmp(employee); } |
| 1 | INSERT INTO 插入数据 |
| 1 2 3 4 5 | <!--插入员工数据--> < insert id = "saveEmp" parameterType = "com.dt.springbootdemo.entity.Employee" > INSERT INTO t_employee(id, name, age, salary, department_id) VALUES (#{id},#{name},#{age},#{salary},#{departmentId}) </ insert > |
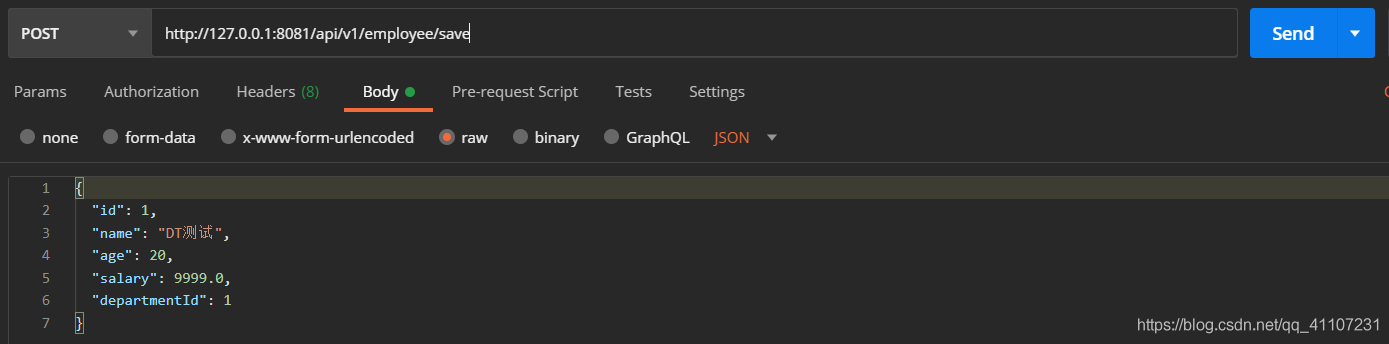
我们新增一条主键ID为1的员工记录。
当我再发送一次请求的时候,会报SQL语句执行错误,因为主键唯一,并且ID=1的记录已经存在了。

加上ignore,再次添加一条ID=1的员工记录
?| 1 | INSERT IGNORE INTO |

并没有报错,但是也没有添加成功,忽略了重复数据的添加。
二、on duplicate key update
?当主键或者唯一键重复时,则执行update语句。
| 1 | ON DUPLICATE KEY UPDATE id = id |
我们任然插入ID=1的员工记录,并且修改一下其他字段(age=25):
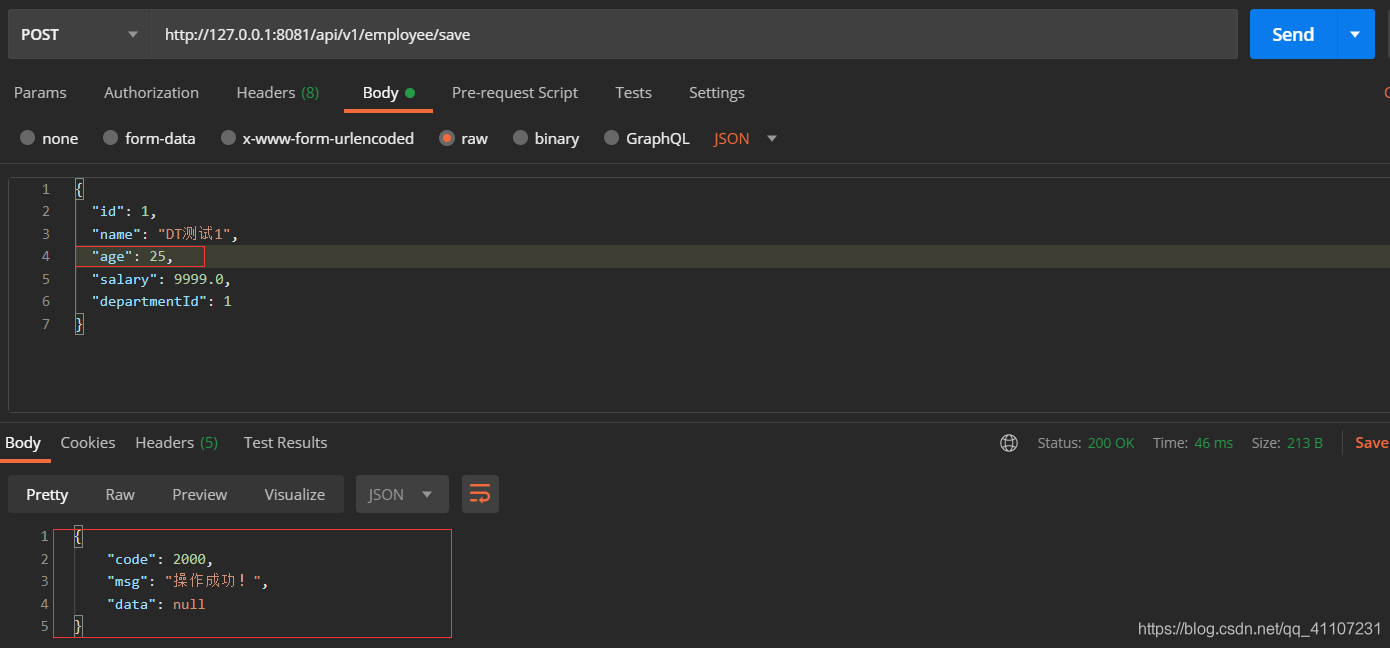
查看数据库记录:

可以看到并没有改变,数据也只有一条,并且返回了成功的提示。
这种方法有个前提条件,就是,需要插入的约束,需要是主键或者唯一约束(在你的业务中那个要作为唯一的判断就将那个字段设置为唯一约束也就是unique key)。
扩展:这种方式还有其他业务场景的需求->>>定时更新其他字段。
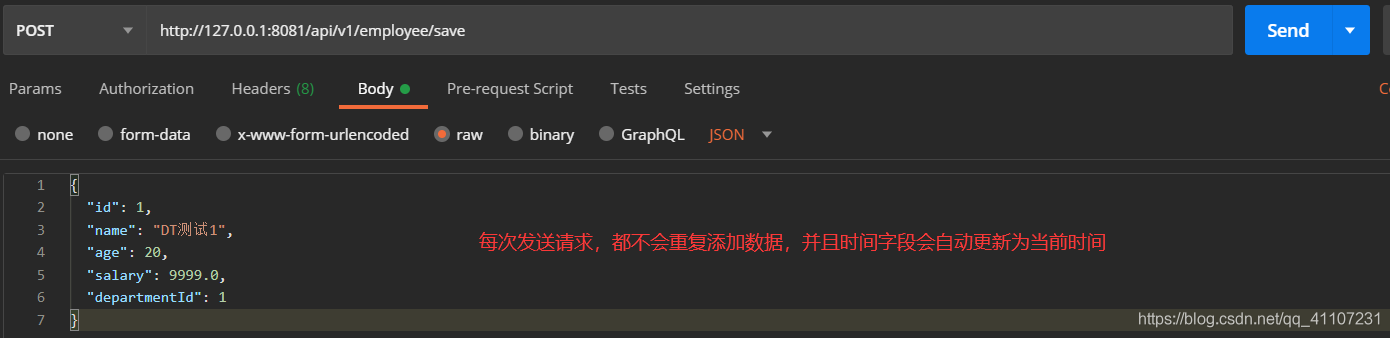
我们在员工表中,再加入一个时间字段:
?| 1 | private Date updateTime; |

然后我们根据updateTime字段来插入数据:
?| 1 2 3 4 5 | < insert id = "saveEmp" parameterType = "com.dt.springbootdemo.entity.Employee" > INSERT INTO t_employee(id, name, age, salary, department_id,update_time) VALUES (#{id},#{name},#{age},#{salary},#{departmentId},now()) ON DUPLICATE KEY UPDATE update_time = now() </ insert > |


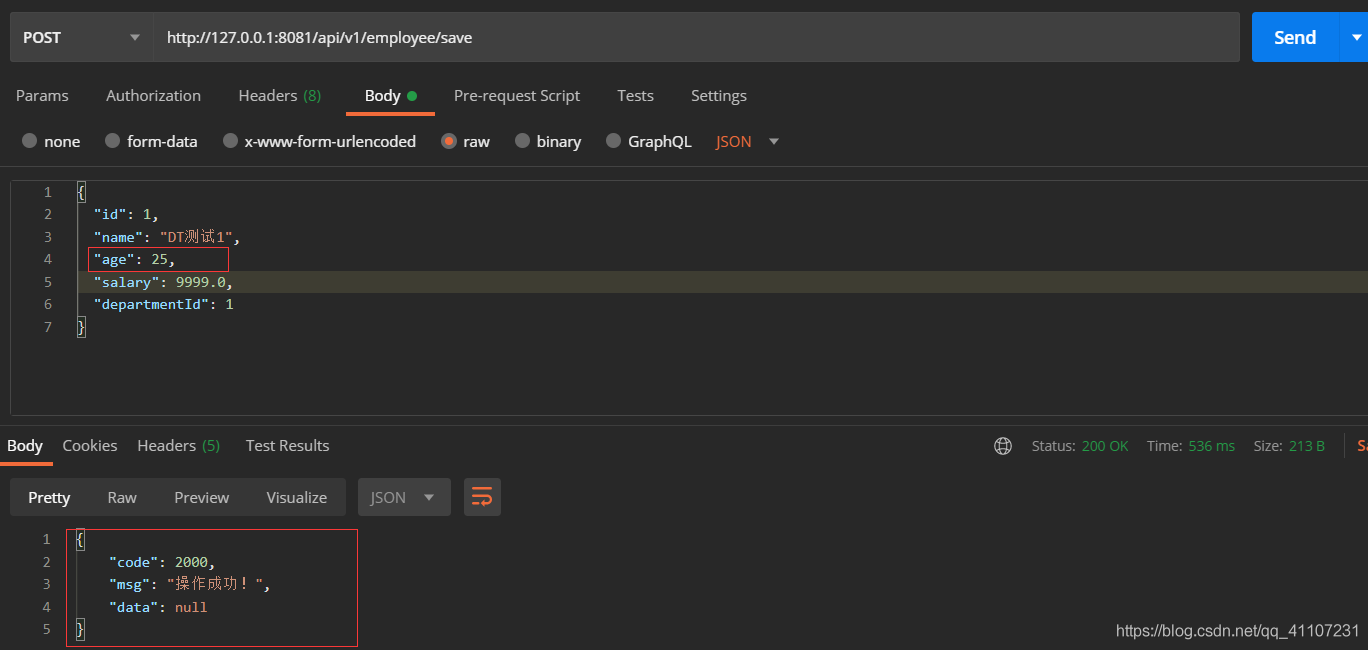
如果插入的时候需要更新其他字段(比如age),该怎么做呢?


三、replace into
?如果存在primary or unique相同的记录,则先删除掉。再插入新记录。
| 1 | REPLACE INTO |
| 1 2 3 4 5 | <!--插入员工数据--> < insert id = "saveEmp" parameterType = "com.dt.springbootdemo.entity.Employee" > REPLACE INTO t_employee(id, name, age, salary, department_id,update_time) VALUES (#{id},#{name},#{age},#{salary},#{departmentId},now()) </ insert > |
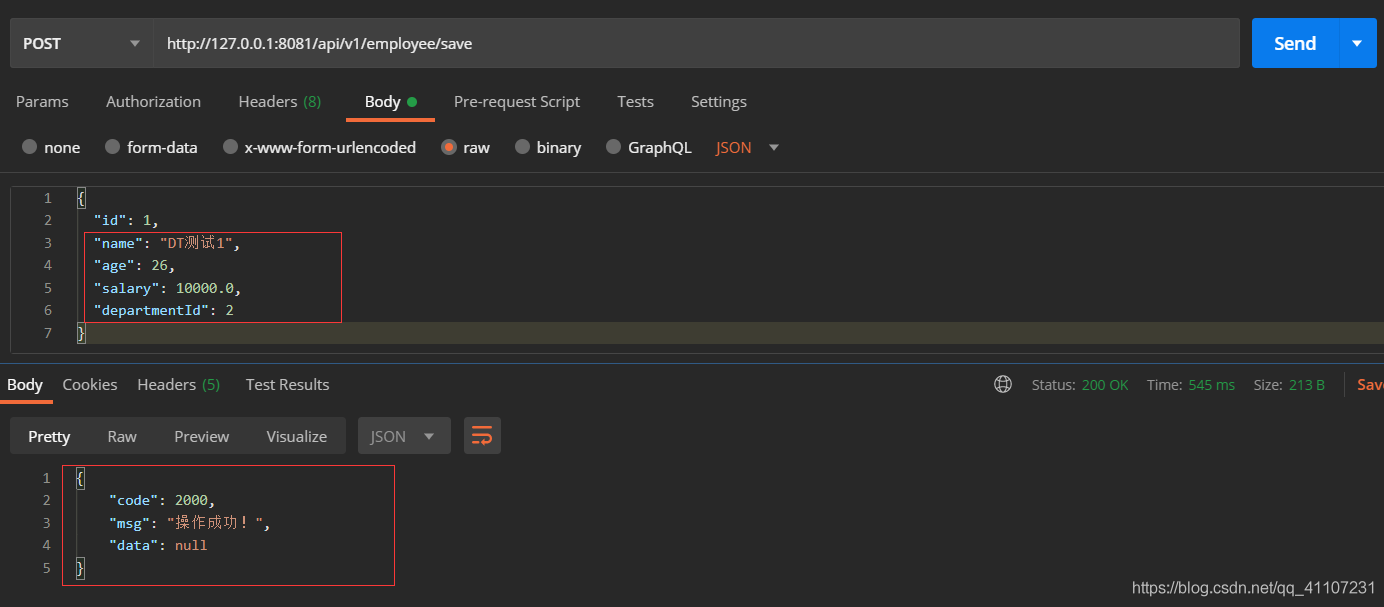

总结:实际开发中,用得最多的就是第二种方式,进行的批量加。
?| 1 2 3 4 5 6 7 8 9 | <!--插入员工数据--> < insert id = "saveEmp" parameterType = "java.util.List" > INSERT INTO t_employee(id, name, age, salary, department_id,update_time) VALUES < foreach collection = "list" item = "item" index = "index" separator = "," > (#{item.id},#{item.name},#{item.age},#{item.salary},#{item.departmentId},now()) </ foreach > ON DUPLICATE KEY UPDATE id = id </ insert > |
控制器:
?| 1 2 3 4 5 | @PostMapping ( "save" ) @ResponseBody public CommonResult<Employee> save( @RequestBody List<Employee> employeeList){ return employeeService.saveEmp(employeeList); } |
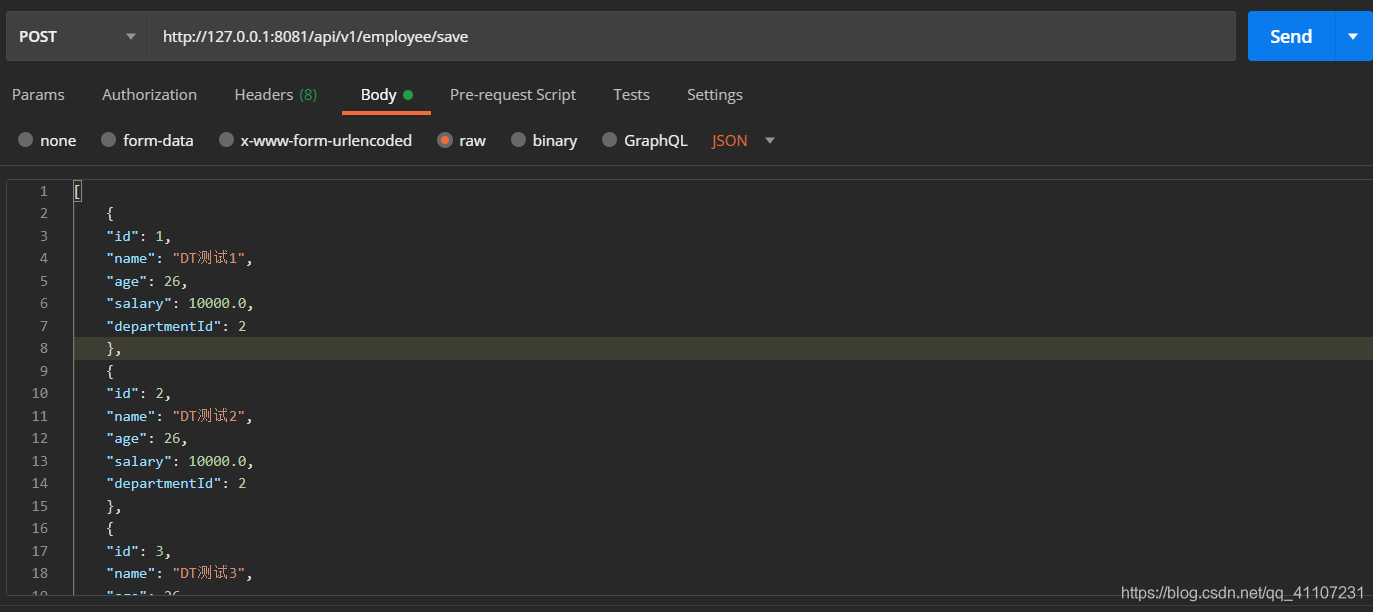
如果存在相同的ID,则不会重复添加。
总结
实际工作中,使用最多的是方法二,根据不同的场景选择不同的方式使用。
到此这篇关于MySql批量插入时如何不重复插入数据的文章就介绍到这了,更多相关MySql不重复插入内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.csdn.net/qq_41107231/article/details/117911314
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








