
Mysql数据库的主从复制与读写分离精讲教程

目录
- 前言
- 一、mysql主从复制
- 1.支持的复制类型
- 2.主从复制的工作过程是基于日志
- 3.请求方式
- 4.主从复制的原理
- 5.mysql集群和主从复制分别适合在什么场景下使用
- 6.为什么使用主从复制、读写分离
- 7.用途及条件
- 8.mysql主从复制存在的问题
- 9.mysql主从复制延迟
- 二、主从复制的形式
- 三、读写分离
- 1.原理
- 2.为什么要读写分离呢?
- 3.什么时候要读写分离?
- 5.目前较为常见的mysql读写分离
- 四、案例实施
- 1.案例环境
- 2.实验思路(解决需求)
- 3.准备
- 4.搭建mysql主从复制
- 5.搭建mysql读写分离
- 总结
- 1.如何查看主从同步状态是否成功
- 2.如果i/o和sql不是yes呢,你是如何排查的
- 3.show slave status能看到哪些信息(比较重要的)
- 4.主从复制慢(延迟)有哪些可能
前言
在实际的生产环境中,如果对mysql数据库的读和写都在一台数据库服务中操作,无论在安全性、高可用性,还是高并发性等各个方面都是完全不能满足实际需求的,一般来说都是通过主从复制(master-slave)的方式来同步数据,再通过读写分离来提升数据库的并发负载能力这样的方案进行部署与实施
一、mysql主从复制
1.支持的复制类型
基于语句的复制(statement):在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制,执行效率高基于行的复制(row): 把改变的内容复制过去,而不是把命令在从服务器上执行一遍混合类型的复制(mixed): 在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制,执行效率高
2.主从复制的工作过程是基于日志
master二进制日志
slave中继日志
3.请求方式
i/o线程
dump线程
sql线程
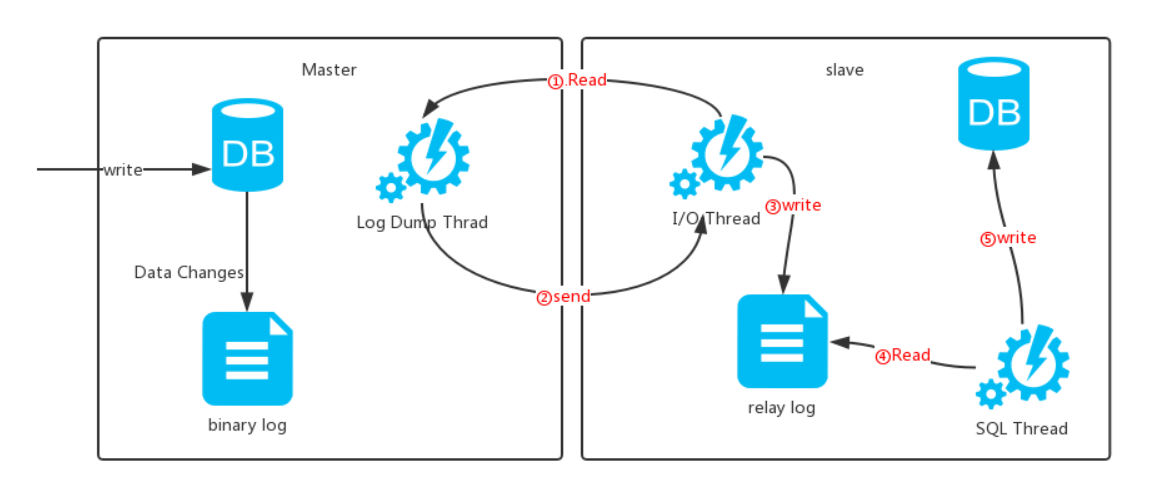
4.主从复制的原理
①master节点将数据的改变记录成二进制日志(bin log),当master上的数据发生改变时,则将其改变写入二进制日志中
②slave节点会在一定时间间隔内对master的二进制日志进行探测其是否发生改变
如果发生改变,则开始一个i/o线程请求 master的二进制事件
③同时master节点为每个i/o线程启动一个dump线程,用于向其发送二进制事件,并保存至slave节点本地的中继日志(relay log)中
④slave节点将启动sql线程从中继日志中读取二进制日志,在本地重放,即解析成 sql 语句逐一执行,使得其数据和 master节点的保持一致,最后i/o线程和sql线程将进入睡眠状态,等待下一次被唤醒
复制过程有一个很重要的限制,即复制在 slave 上是串行化的,也就是说 master 上的并行更新操作不能在 slave 上并行操作
中继日志通常会位于os缓存中,所以中继日志的开销很小
5.mysql集群和主从复制分别适合在什么场景下使用
集群和主从复制是为了应对高并发、大访问量的情况,如果网站访问量和并发量太大了,少量的数据库服务器是处理不过来的,会造成网站访问慢,数据写入会造成数据表或记录被锁住,锁住的意思就是其他访问线程暂时不能读写要等写入完成才能继续,这样会影响其他用户读取速度,采用主从复制可以让一些服务器专门读,一些专门写可以解决这个问题
6.为什么使用主从复制、读写分离
主从复制、读写分离一般是一起使用的,目的很简单,就是为了提高数据库的并发性能。你想,假设是单机,读写都在一台mysql上面完成,性能肯定不高。如果有三台mysql,一台mater只负责写操作,两台salve只负责读操作,性能不就能大大提高了吗?
所以主从复制、读写分离就是为了数据库能支持更大的并发
随着业务量的扩展、如果是单机部署的mysql,会导致i/o频率过高。采用主从复制、读写分离可以提高数据库的可用性
7.用途及条件
mysql主从复制用途:
实时灾备,用于故障切换
读写分离,提供查询服务
备份,避免影响服务
必要条件:
主库开启binlog日志(设置log-bin参数)
主从server-id不同
从库服务器能连通主库
8.mysql主从复制存在的问题
主库宕机后,数据可能丢失
从库只有一个sql thread,主库写压力大,复制很可能延时
解决办法
半同步复制——解决数据丢失的问题
并行复制——解决从库复制延迟的问题
9.mysql主从复制延迟
①master服务器高并发,形成大量事务
②网络延迟
③主从硬件设备导致——cpu主频、内存io、硬盘io
④本来就不是同步复制、而是异步复制
- 从库优化mysql参数。比如增大innodb_buffer_pool_size,让更多操作在mysql内存中完成,减少磁盘操作
- 从库使用高性能主机,包括cpu强悍、内存加大。避免使用虚拟云主机,使用物理主机,这样提升了i/o方面性
- 从库使用ssd磁盘
- 网络优化,避免跨机房实现同步
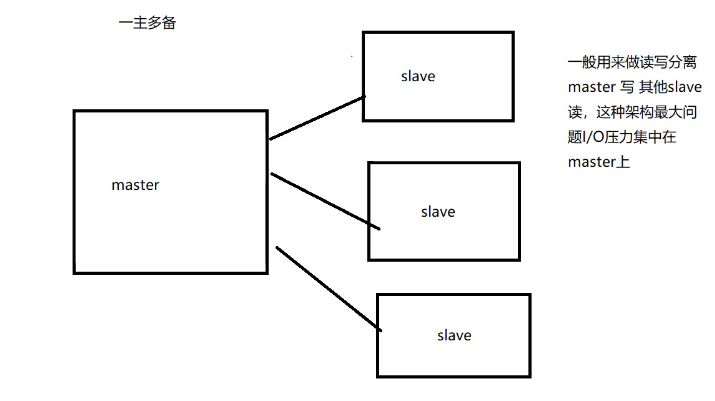
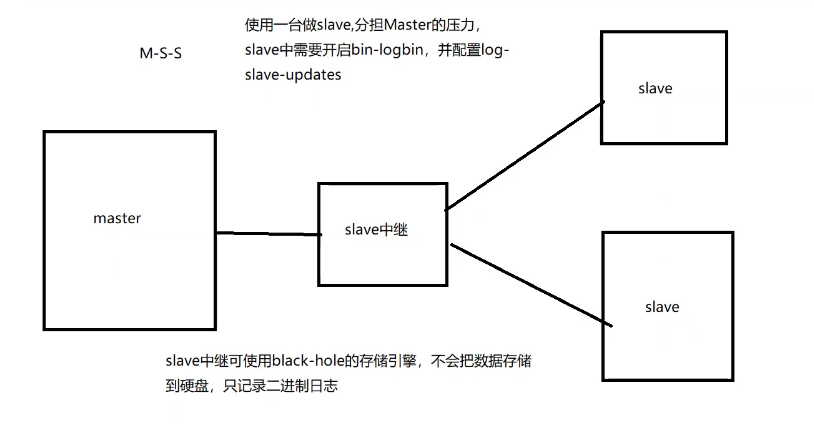
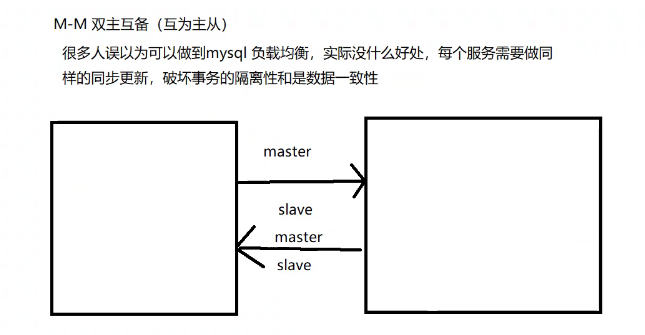
二、主从复制的形式
三、读写分离
1.原理
①只在主服务器上写,只在从服务器上读
②主数据库处理事务性查询,从数据库处理select查询
③数据库复制用于将事务性查询导致的变更同步到集群中的从数据库
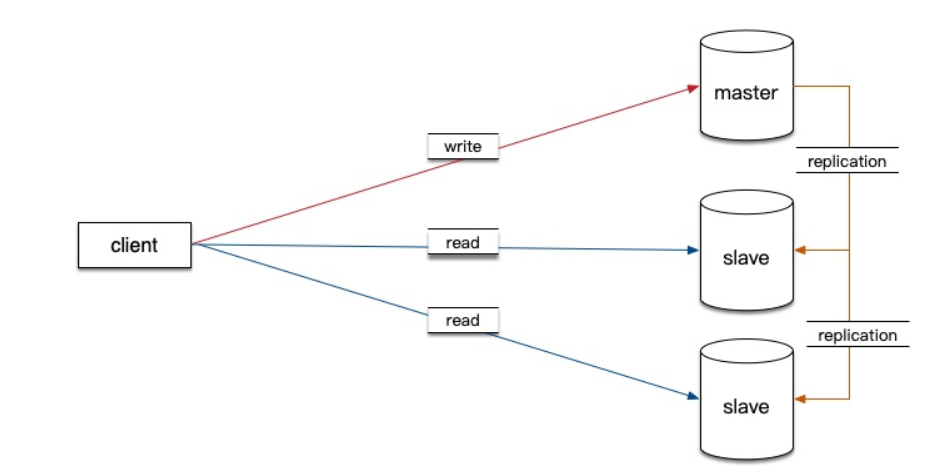
2.为什么要读写分离呢?
因为数据库的“写”(写10000条数据可能要3分钟)操作是比较耗时的但是数据库的“读”(读10000条数据可能只要5秒钟)所以读写分离,解决的是,数据库的写入,影响了查询的效率
3.什么时候要读写分离?
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用利用数据库主从同步,再通过读写分离可以分担数据库压力,提高性能 4.主从复制与读写分离 在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足实际需求的
5.目前较为常见的mysql读写分离
分为以下两种
①基于程序代码内部实现
在代码中根据 select、insert 进行路由分类,这类方法也是目前生产环境应用最广泛的优点是性能较好,因为在程序代码中实现,不需要增加额外的设备为硬件开支;缺点是需要开发人员来实现,运维人员无从下手但是并不是所有的应用都适合在程序代码中实现读写分离,像一些大型复杂的java应用,如果在程序代码中实现读写分离对代码改动就较大
②基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接到客户端请求后通过判断后转发到后端数据库,有以下代表性程序
(1)mysql-proxy,mysql-proxy 为 mysql 开源项目,通过其自带的 lua 脚本进行sql 判断。
(2)atlas,是由奇虎360的web平台部基础架构团队开发维护的一个基于mysql协议的数据中间层项目,它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用atlas运行的mysql业务,每天承载的读写请求数达几十亿条。支持事物以及存储过程
(3)amoeba,由陈思儒开发,作者曾就职于阿里巴巴。该程序由java语言进行开发,阿里巴巴将其用于生产环境。但是它不支持事务和存储过程。
由于使用mysql proxy 需要写大量的lua脚本,这些lua并不是现成的,而是需要自己去写,这对于并不熟悉mysql proxy 内置变量和mysql protocol 的人来说是非常困难的amoeba是一个非常容易使用、可移植性非常强的软件。因此它在生产环境中被广泛应用于数据库的代理层
四、案例实施
1.案例环境
本案例环境使用舞台服务器磨你搭建,拓扑图如下
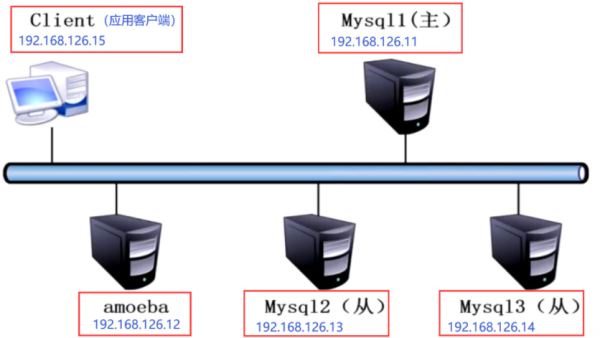
| 主机名 | 主机 | 操作系统 | ip 地址 | 主要软件 |
|---|---|---|---|---|
| centos 7-1 | master | centos 7 | 192.168.126.11 | ntp 、 mysql-boost-5.7.17.tar.gz |
| centos 7-2 | amoeba | centos 7 | 192.168.126.12 | jdk-6u14-linux-x64.bin、amoeba-mysql-binary-2.2.0.tar.gz |
| centos 7-3 | slave1 | centos 7 | 192.168.126.13 | ntp 、ntpdate 、 mysql-boost-5.7.20.tar.gz |
| cengos 7-4 | slave2 | centos 7 | 192.168.126.14 | ntp 、ntpdate 、mysql-boost-5.7.17.tar.gz |
| centos 7-5 | 客户端 | centos 7-5 | 192.168.126.15 | mysql5.7 |
2.实验思路(解决需求)
客户端访问代理服务器
代理服务器写入到主服务器
主服务器将增删改写入自己二进制日志
从服务器将主服务器的二进制日志同步至自己中继日志
从服务器重放中继日志到数据库中
客户端读,则代理服务器直接访问从服务器
降低负载,起到负载均衡作用
3.准备
- 除了客户端,都需要先源码编译安装好mysql
- 都需关闭防火墙及控制访问机制
| 1 2 3 4 5 | systemctl stop firewalld systemctl disable firewalld #关闭防火墙(及开机禁用) setenforce 0 #关闭安全访问控制机制 |
4.搭建mysql主从复制
①mysql主从服务器时间同步
主服务器设置
?| 1 2 3 4 5 6 7 8 9 10 11 | #安装 ntp yum -y install ntp #配置 ntp vim /etc/ntp.conf #末行添加以下内容 server 127.127.126.0 fudge 127.127.126.0 stratum 8 #设置本地是时钟源,注意修改网段 #设置时间层级为8(限制在15内) #重启服务 service ntpd restart |
从服务器设置
?| 1 2 3 4 5 6 7 8 9 | yum -y install ntp ntpdate #安装服务,ntpdate用于同步时间 service ntpd start #开启服务 /usr/sbin/ntpdate 192.168.126.11 #进行时间同步,指向master服务器ip crontab -e #写入计划性任务,每半小时进行一次时间同步 */30 * * * * /usr/sbin/ntpdate 192.168.126.11 |
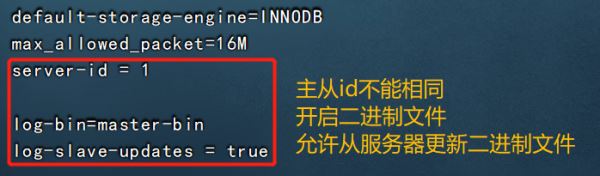
②配置mysql master主服务器
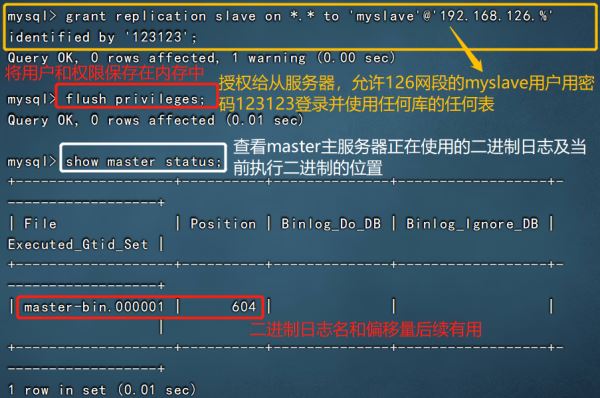
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | vim /etc/my.cnf #配置以下内容 server-id = 1 log-bin=master-bin #添加,主服务器开启二进制日志 log-slave-updates= true #添加,允许从服务器更新二进制日志 systemctl restart mysqld #重启服务使配置生效 mysql -uroot -p123123 #登录数据库程序,给从服务器授权 grant replication slave on *.* to 'myslave' @ '192.168.126.%' identified by '123123' ; flush privileges ; show master status; quit #file 列显示日志名,fosition 列显示偏移量 |
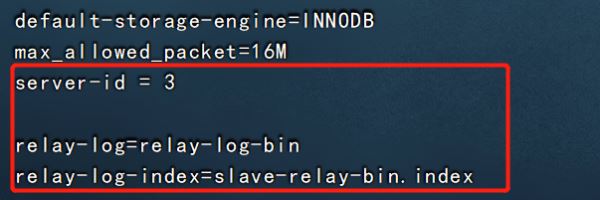
③配置从服务器
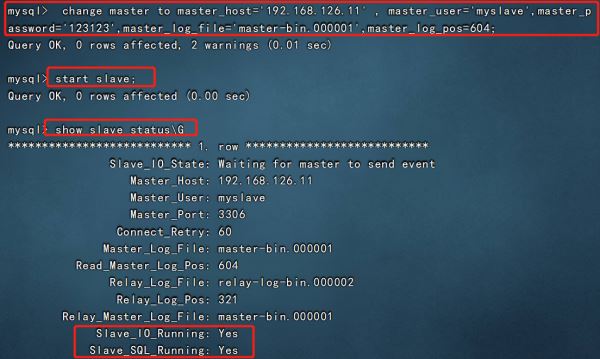
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | vim /etc/my.cnf server-id = 2 #修改,注意id与master的不同,两个slave的id也要不同 relay-log=relay-log-bin #添加,开启中继日志,从主服务器上同步日志文件记录到本地 relay-log- index =slave-relay-bin. index #添加,定义中继日志文件的位置和名称 systemctl restart mysqld mysql -uroot -p123123 change master to master_host= '192.168.126.11' , master_user= 'myslave' ,master_password= '123123' ,master_log_file= 'master-bin.000001' ,master_log_pos=604; #配置同步,注意 master_log_file 和 master_log_pos 的值要与master的一致 start slave; #启动同步,如有报错执行 reset slave; show slave status\g #查看 slave 状态 //确保 io 和 sql 线程都是 yes,代表同步正常 slave_io_running: yes #负责与主机的io通信 slave_sql_running: yes #负责自己的slave mysql进程 |
slave1:
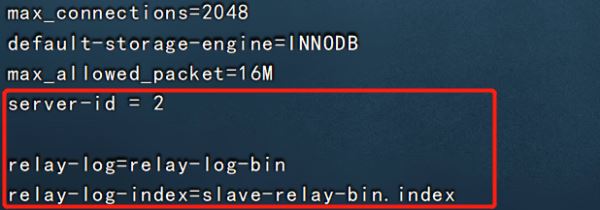

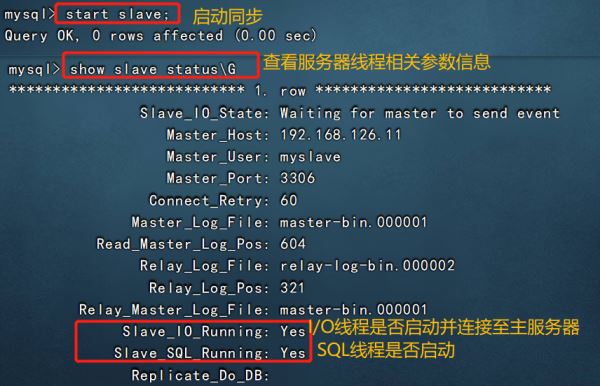
slave2: 和slave1配置一样,id不能相同
一般 slave_io_running: no 有这几种可能性:
- 网络不通
- my.cnf 配置有问题
- 密码、file 文件名、pos 偏移量不对
- 防火墙没有关闭
④验证主从复制效果

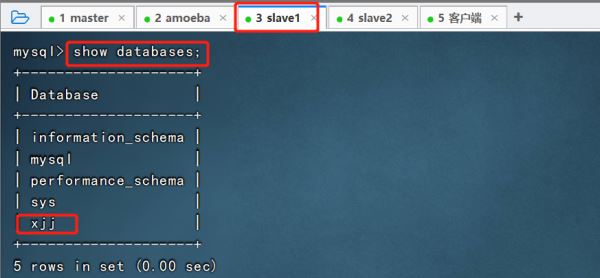
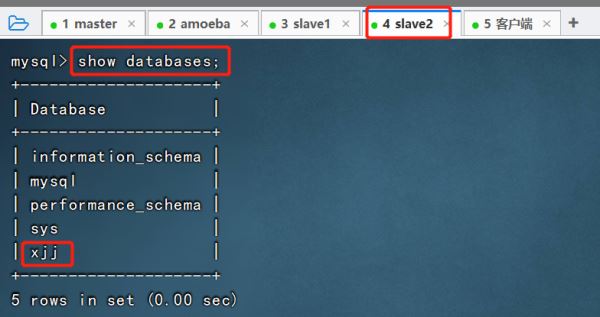
5.搭建mysql读写分离
- 这个软件致力于 mysql 的分布式数据库前端代理层,它主要为应用层访问 mysql 时充当 sql 路由,并具有负载均衡、高可用性、sql 过滤、读写分离、可路由相关到目标数据库、可并发请求多台数据库
- 通过 amoeba 能够完成多数据源的高可用、负载均衡、数据切片的功能
①在主机amoeba上安装java环境 因为 amoeba 基于是 jdk1.5 开发的,所以官方推荐使用 jdk1.5 或 1.6 版本,高版本不建议使用
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | cd /opt/ #在finalshell中,把软件包拖进来 amoeba-mysql- binary -2.2.0.tar.gz jdk-6u14-linux-x64.bin cp jdk-6u14-linux-x64.bin /usr/ local / cd /usr/ local / chmod +x jdk-6u14-linux-x64.bin ./jdk-6u14-linux-x64.bin #按住enter键不动一直到最下面,有提示输入yes+回车即可 mv jdk1.6.0_14/ /usr/ local /jdk1.6 #改名 vim /etc/profile #编辑全局配置文件,在最后一行添加以下配置 export java_home=/usr/ local /jdk1.6 export classpath=$classpath:$java_home/lib:$java_home/jre/lib export path=$java_home/lib:$java_home/jre/bin/:$path:$home/bin export amoeba_home=/usr/ local /amoeba export path=$path:$amoeba_home/bin #输出定义java的工作目录 #输出指定的java类型 #将java加入路径环境变量 #输出定义amoeba工作目录 #加入路径环境变量 source /etc/profile #执行修改后的全局配置文件 java -version #查看java版本信息以检查是否安装成功 |
②安装并配置amoeba
?| 1 2 3 4 5 | mkdir /usr/ local /amoeba tar zxvf /opt/amoeba-mysql- binary -2.2.0.tar.gz -c /usr/ local /amoeba/ chmod -r 755 /usr/ local /amoeba/ /usr/ local /amoeba/bin/amoeba #如显示 amoeba start|stop 说明安装成功 |

③配置amowba读写分离,两个slave读写负载均衡 在master、slave1、slave2的mysql上开放权限给amoeba访问



④在主机amoeba中编辑amoeba.xml配置文件
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 | cd /usr/ local /amoeba/conf/ cp amoeba.xml amoeba.xml.bak vim amoeba.xml #修改amoeba配置文件 #30行修改 <property name = "user" >amoeba</property> #32行修改 <property name = "password" >123123</property> #115行修改 <property name = "defaultpool" >master</property> #117去掉注释 <property name = "writepool" >master</property> <property name = "readpool" >slaves</property> |
⑤编辑dbservers.xml 配置文件
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | cp dbservers.xml dbservers.xml.bak vim dbservers.xml #修改数据库配置文件 #23行注释掉 作用:默认进入test库 以防mysql中没有test库时,会报错 <! -- <property name="schema">test</property> --> #26行修改 <property name = "user" >test</property> #28-30行去掉注释 <property name = "password" >123.com</property> #45行修改,设置主服务器的名master <dbserver name = "master" parent= "abstractserver" > #48行修改,设置主服务器的地址 <property name = "ipaddress" >192.168.126.11</property> #52行修改,设置从服务器的名slave1 <dbserver name = "slave1" parent= "abstractserver" > #55行修改,设置从服务器1的地址 <property name = "ipaddress" >192.168.126.13</property> #58行复制上面6行粘贴,设置从服务器2的名slave2和地址 <dbserver name = "slave2" parent= "abstractserver" > <property name = "ipaddress" >192.168.184.14</property> #65行修改 <dbserver name = "slaves" virtual= "true" > #71修改 <property name = "poolnames" >slave1,slave2</property> |
⑥确定配置无误后,可以启动 amoeba 软件,其默认端口为 tcp 8066
?| 1 2 3 4 | /usr/ local /amoeba/bin/amoeba start& #启动amoeba软件,按ctrl+c 返回 netstat -anpt | grep java #查看8066端口是否开启,默认端口为tcp 8066 |
⑦测试
1.前往客户端快速装好 mysql 虚拟客户端,然后通过代理访问 mysql
?| 1 2 3 4 5 6 | yum -y install mysql #用yum快速安装mysql虚拟客户端 mysql -u amoeba -p123123 -h 192.168.126.12 -p8066 #通过代理访问mysql,ip地址指向amoba #在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从服务器 |
2.在 master 上创建一个表,同步到两个从服务器上
?| 1 2 | use club; create table puxin (id int (10), name varchar (10),address varchar (20)); |
3.然后关闭从服务器的 slave 功能,从主服务器上同步了表,手动插入数据内容
?| 1 2 3 4 5 6 | stop slave; #关闭同步 use club; insert into puxin values ( '1' , 'wangyi' , 'this_is_slave1' ); #slave2 insert into puxin values ( '2' , 'wanger' , 'this_is_slave2' ); |
4.再回到主服务器上插入其他内容
?| 1 | insert into pucin values ( '3' , 'wangwu' , 'this_is_master' ); |
5.测试读操作,前往客户端主机查询结果
?| 1 2 | use club; select * from puxin; |
6.在客户端上插入一条语句,但是在客户端上查询不到,最终只有在 master 上才上查看到这条语句内容,说明写操作在 master 服务器上
?| 1 | insert into puxin values ( '4' , 'liuliu' , 'this_is_client' ); |
7.再在两个从服务器上执行 start slave; 即可实现同步在主服务器上添加的数据
总结
由此验证,已经实现了 mysql 读写分离,目前所有的写操作全部在 master 主服务器上,用来避免数据的不同步
而所有的读操作都分摊给了 slave 从服务器,用来分担数据库的压力
1.如何查看主从同步状态是否成功
在从服务器内输入命令 show slave status\g,查看主从信息进行查看,里面有io线程的状态信息,还有master服务器的ip地址、端口、事务开始号
当 slave_io_running 和 slave_sql_running 都显示为yes时,表示主从同步状态成功
2.如果i/o和sql不是yes呢,你是如何排查的
- 首先排除网络问题,使用ping命令查看从服务是否能与主服务器通信
- 再者查看防火墙和核心防护是否关闭
- 接着查看从服务器内的slave是否开启
- 两个从服务器的 server-id 是否相同导致只能连上一台
- master_log_file 和 master_log_pos 的值要是否与master查询的一致
3.show slave status能看到哪些信息(比较重要的)
- io线程的状态信息
- master服务器的ip地址、端口、事务开始位置
- 最近一次的报错信息和报错位置等
4.主从复制慢(延迟)有哪些可能
- 主服务器的负载过大,被多个睡眠或者僵尸线程占用,导致系统负载过大
- 从库硬件比主库差,导致复制延迟
- 主从复制单线程,如果主库写并发太大,来不及传送到从库,就会导致延迟
- 慢sql语句过多
- 网络延迟
以上就是mysql数据库的主从复制与读写分离精讲教程的详细内容,更多关于mysql数据库主从复制与读写分离的资料请关注服务器之家其它相关文章!
原文链接:https://blog.csdn.net/weixin_53560205/article/details/121073207
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。









