
mysql聚簇索引的页分裂原理实例分析
吾爱主题
阅读:373
2024-04-05 14:21:59
评论:0

本文实例讲述了mysql聚簇索引的页分裂。分享给大家供大家参考,具体如下:
在MySQL中,MyISAM采用的是非聚簇索引的,InnoDB存储引擎是采用聚簇索引的。
聚簇结构的特点:
- 根据主键查询条目时,不用回行(数据就在主键节点下)
- 如果碰到不规则数据插入时,造成频繁的页分裂
为什么会产生页分裂?
这是因为聚簇索引采用的是平衡二叉树算法,而且每个节点都保存了该主键所对应行的数据,假设插入数据的主键是自增长的,那么根据二叉树算法会很快的把该数据添加到某个节点下,而其他的节点不用动;但是如果插入的是不规则的数据,那么每次插入都会改变二叉树之前的数据状态。从而导致了页分裂。
测试:
创建2张表
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | create table t8( id int primary key , c1 varchar (500), c2 varchar (500), c3 varchar (500), c4 varchar (500), c5 varchar (500), c6 varchar (500) ) engine innodb charset utf8; create table t9( id int primary key , c1 varchar (500), c2 varchar (500), c3 varchar (500), c4 varchar (500), c5 varchar (500), c6 varchar (500) ) engine innodb charset utf8; |
写一个php脚本,用于插入1W条无规则的主键数据和1W条规则的主键数据,来看看区别。
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | <?php set_time_limit(0); $conn = mysql_connect( 'localhost' , 'root' , '1234' ); mysql_query( 'use test;' ); //自增长主键 $str = str_repeat ( 'a' , 500); $startTime = microtime(true); for ( $i =1; $i <=10000; $i ++){ mysql_query( "insert into t8 values($i,'$str','$str','$str','$str','$str','$str')" ); } $endTime = microtime(true); echo $endTime - $startTime . '<br/>' ; //无序的主键 $arr = range(1, 10000); shuffle( $arr ); $startTime = microtime(true); foreach ( $arr as $i ){ mysql_query( "insert into t9 values($i,'$str','$str','$str','$str','$str','$str')" ); } $endTime = microtime(true); echo $endTime - $startTime . '<br/>' ; |
测试结果图
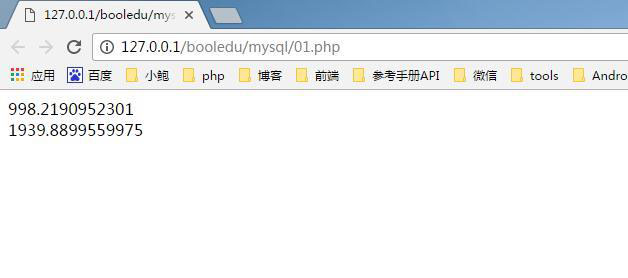
1W条规则的数据:998秒 = 16分钟
1W条不规则的数据:1939秒 = 32分钟
结论:
聚簇索引的主键值,应尽量是连续增长的值,而不是要是随机值, (不要用随机字符串或UUID),否则会造成大量的页分裂与页移动。在使用InnoDB的时候最好定义成:
id int unsigned primary key auto_increment
希望本文所述对大家MySQL数据库计有所帮助。
原文链接:https://blog.csdn.net/baochao95/article/details/61924952
声明
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








